

更多AI前沿科技资讯,请关注我们:

closerAIGCcloserAI,一个深入探索前沿人工智能与AIGC领域的资讯平台,我们旨在让AIGC渗入我们的工作与生活中,让我们一起探索AIGC的无限可能性! 公众号

产品经理逛世界一只在互联网PM浪迹多年的吉米猫,希望与一起分享,一起成长,一起用发现的眼光看世界,用一颗产品心分析世间万物。个人资源分享网站:www.douyoubuy.cn 公众号
【closerAI ComfyUI】阿里团队又放大招,AI绘画又一重大突破,上下文微调文生图LORA,保持人物高度一致性与连贯性。大家好,我是Jimmy。正如我上面说到的,这个消息非常震撼,阿里出的这个上下文微调LORA模型,直接让我们能通过文本,来实现生图的人物一致性!并且图与图之间是有关联性的。也就是它能生产连环画面。这个作用的想象性很大,我们可以制作故事,电影画面,摄影集、字体设计、家装、PPT、夫妻档案、视觉识别等!这太疯狂了!In-Context LoRA微调文生图模型介绍

阿里团队推出In-Context LoRA微调文本到图像模型,以生成具有可自定义内在关系的图像集,可选地以另一个集合为条件,使其能够适应各种任务。这次开源提供了10个模型:情侣档案设计、电影故事板、字体设计、家装、肖像插图、人像摄影、PPT模板、沙尘暴视觉效果、视觉效果、视觉识别设计。
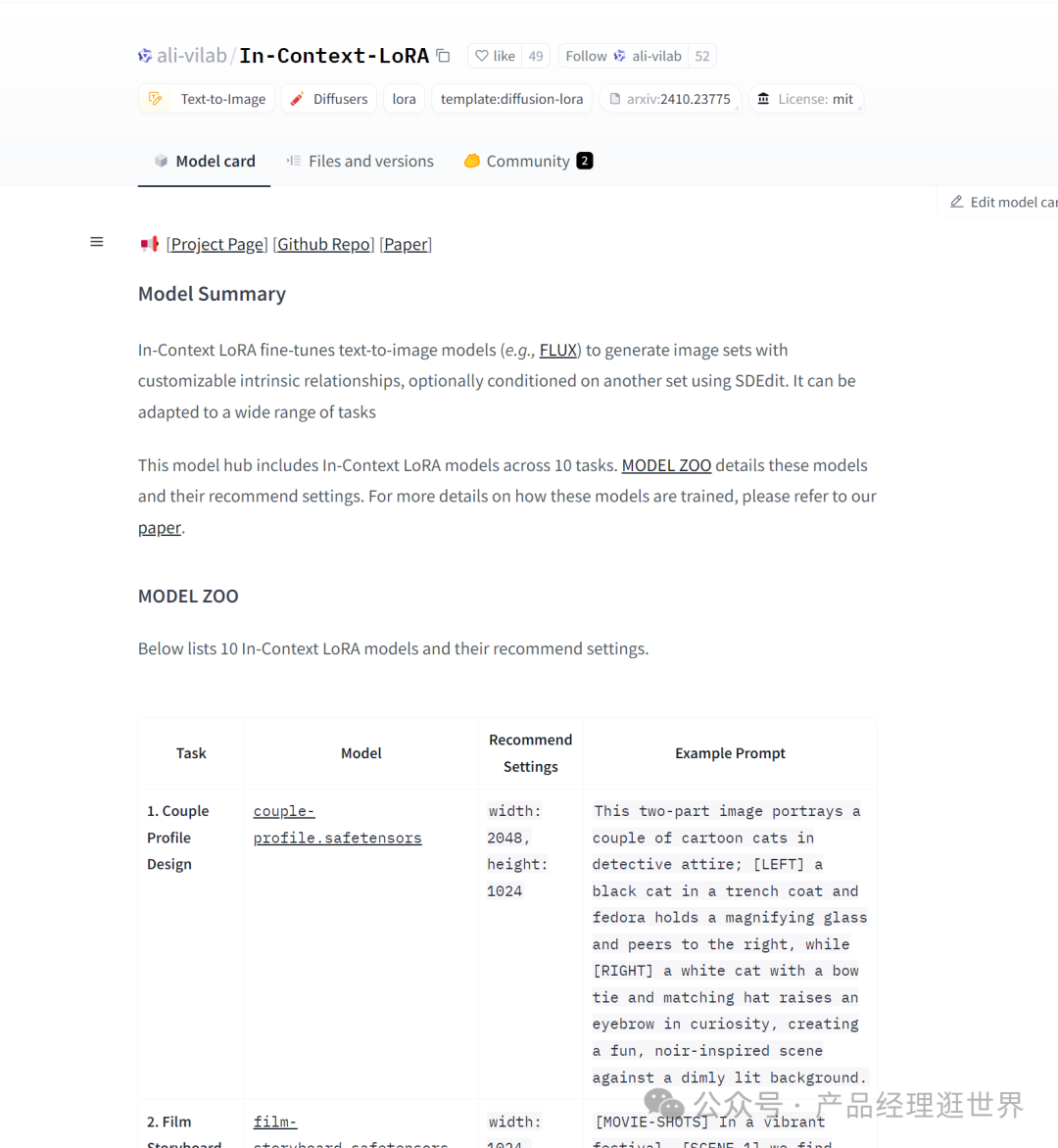
In-Context LoRA地址论文地址:https://ali-vilab.github.io/In-Context-LoRA-Page/模型下载地址:https://huggingface.co/ali-vilab/In-Context-LoRA
鼓励大家在抱脸上下载,但如果不能魔法,可上镜像站下载:https://hf-mirror.com/ali-vilab/In-Context-LoRA








In-Context LoRA使用方法使和方法:直接下载10个LORA,文件不大。每个172MB,总的大小1G多吧。直接下载就是了。
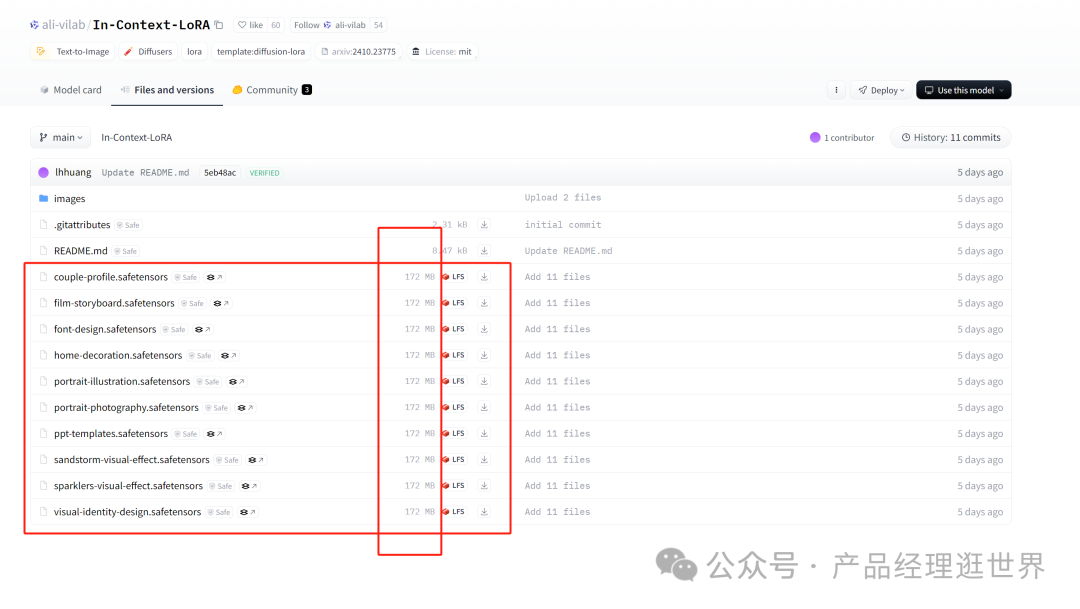
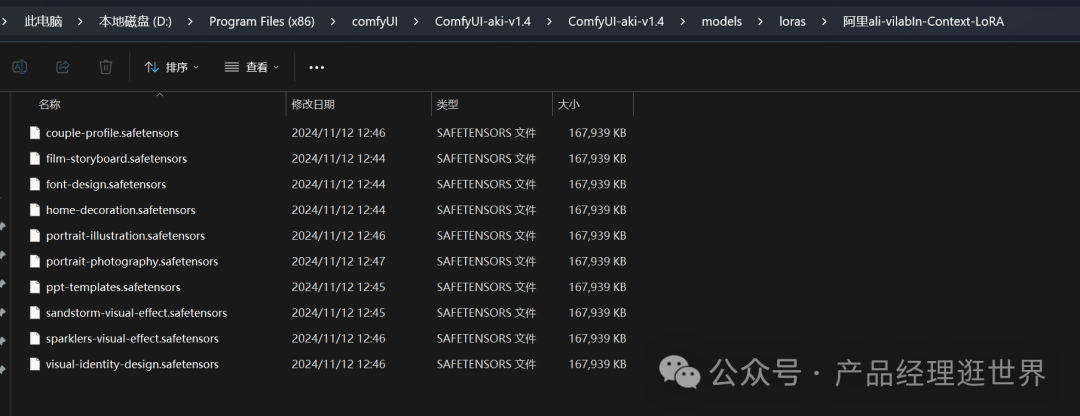
下载后放入。放到以下路径。
In-Context LoRA的体验首先打开我们搭建的工作流:closerAI iClora 上下文文生图工作流
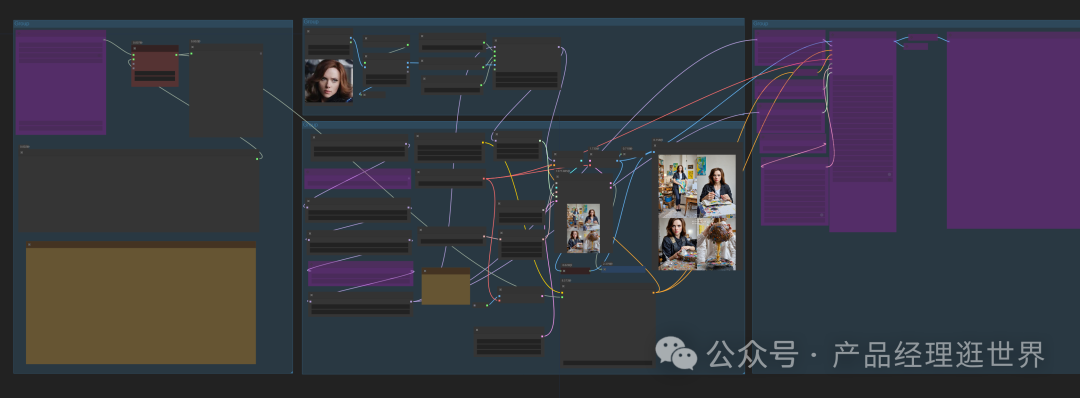
工作流搭建思路,提供中文提示词输入,加入pulid flux测试换脸。加载in-context LoRA模型。因为有10个模型,我们抽几个测试。1、电影故事板 film-storyboard.safetensors输入以下提示词:
[MOVIE-SHOTS] In a vibrant festival, [SCENE-1] we find <Leo>, a shy boy, standing at the edge of a bustling carnival, eyes wide with awe at the colorful rides and laughter, [SCENE-2] transitioning to him reluctantly trying a daring game, his friends cheering him on, [SCENE-3] culminating in a triumphant moment as he wins a giant stuffed bear, his face beaming with pride as he holds it up for all to see.
中文翻译一下:
[电影镜头]在一个充满活力的节日,
[场景-1]我们发现<Leo>,一个害羞的男孩,站在一个繁华的狂欢节的边缘,眼睛睁得大大的,对五颜六色的游乐设施和笑声充满敬畏,
[场景-2]过渡到他不情愿地尝试一个大胆的游戏,他的朋友们为他欢呼,
[场景-3]在一个胜利的时刻达到高潮,因为他赢得了一个巨大的毛绒熊,他脸洋溢着骄傲,因为他把它举起来让所有人看到。
工作流生成以下结果:
[场景-1]我们发现<Leo>,一个害羞的男孩,站在一个繁华的狂欢节的边缘,眼睛睁得大大的,对五颜六色的游乐设施和笑声充满敬畏,

[场景-2]过渡到他不情愿地尝试一个大胆的游戏,他的朋友们为他欢呼,

[场景-3]在一个胜利的时刻达到高潮,因为他赢得了一个巨大的毛绒熊,他的脸上洋溢着骄傲,因为他把它举起来让所有人看到。

不错不错,贯与致,人物从表现上看是几乎一致的,不能说百分百,衣服背包都有。也很好地遵守提示词的内容来生图。
在生成以上结果时候,我就在想是否能接入pulid来控制人物的脸!于是我加入了pulid来测试。
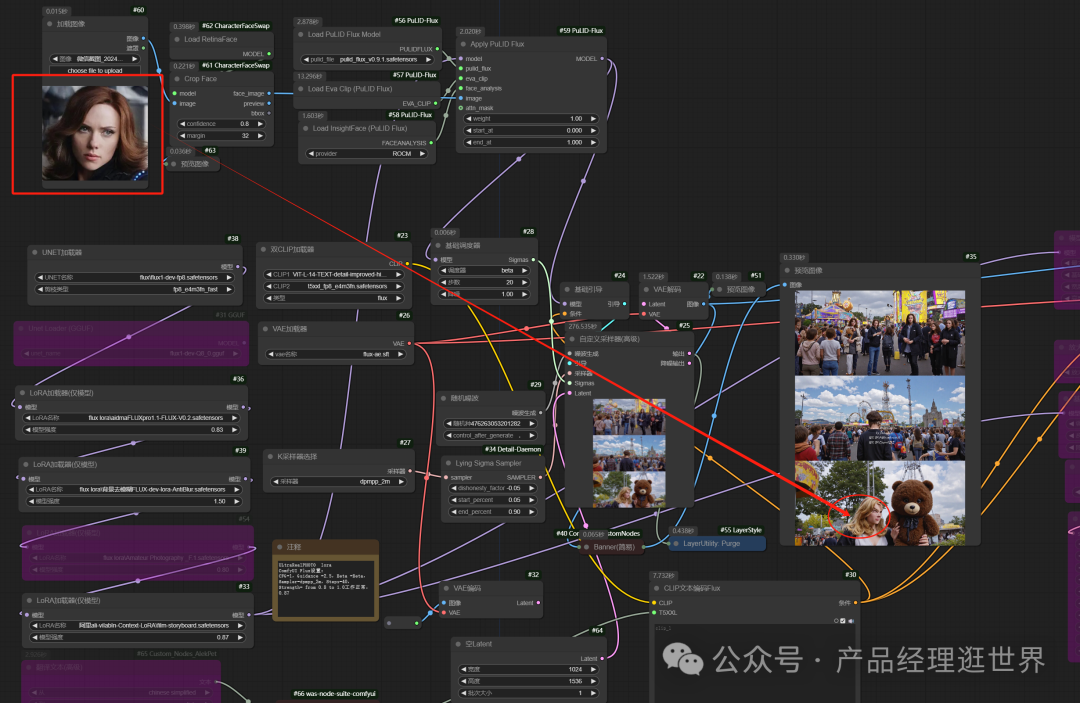
测试结果可以看出,崩的。我觉得既然是分开10个模型,那它的微调重点是已经区分开的,于是,在换脸的话我还是用它的人像摄影微调的LORA吧。
输入提示词:
This [FOUR-PANEL] image illustrates a young artist's creative process in a bright and inspiring studio; [TOP-LEFT] she stands before a large canvas, brush in hand, adding vibrant colors to a partially completed painting, [TOP-RIGHT] she sits at a cluttered wooden table, sketching ideas in a notebook with various art supplies scattered around, [BOTTOM-LEFT] she takes a moment to step back and observe her work, adjusting her glasses thoughtfully, and [BOTTOM-RIGHT] she experiments with different textures by mixing paints directly on the palette, her focused expression showcasing her dedication to her craft.
输出结果如下:

可以看到,我打码了两张,因为崩了。不堪入目。
再测试下,


加入pulid后影响了生图质量。加入了其它LORA后它还是具有不稳定性
我们直接测试不加入的换脸的结果,因为我们测试了两次都影响了原来的质量,但有些画面是可以生成的,所以我们换个思路就是生图之后进行换脸即可。

看,这效果好了。非常棒!
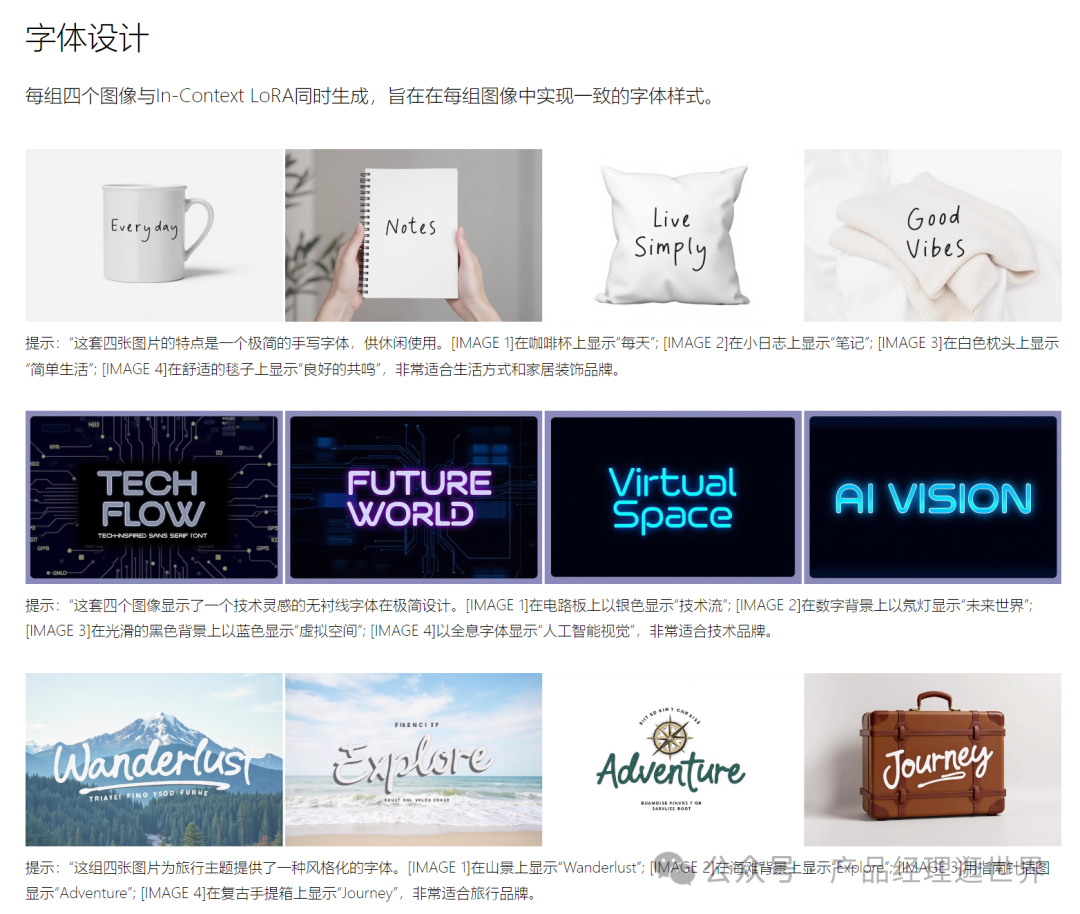
以下我还测试了视觉识别LORA,因为lora太多,日后根据需要使用,大家可以下载来进行体验!
下图是视觉识别测试结果:
The pair of images showcases the joyful identity of a produce brand, [IMAGE1] showing a smiling pineapple graphic and the brand name “CloserAI” in a fun, casual font on a light aqua background; while [IMAGE2] translates the design onto a reusable shopping tote with the pineapple logo in black, held by a person in a market setting, emphasizing the brand’s approachable and eco-friendly vibe.

效果非常棒。建议大家体验使用。并构思项目落地。
以上是closerAI团队基于stable diffusion comfyUI 制作作的closerAI iClora 上下文文生图工作流介绍以及阿里推出的In-Context LoRA微调文生图模型的介绍,大家可以根据工作流思路进行尝试搭建和体验In-Context LoRA。
当然,也可以在我们closerAI会员站上获取对应的工作流。
更多AI前沿科技资讯,请关注我们:

closerAIGCcloserAI,一个深入探索前沿人工智能与AIGC领域的资讯平台,我们旨在让AIGC渗入我们的工作与生活中,让我们一起探索AIGC的无限可能性! 公众号

产品经理逛世界一只在互联网PM浪迹多年的吉米猫,希望与大家一起分享,一起成长,一起用发现的眼光看世界,用一颗产品心分析世间万物。个人资源分享网站:www.douyoubuy.cn 公众号
主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网
评论(0)