

更多AI前沿科技资讯,请关注我们:http://aigc.douyoubuy.cn/
【closerAI ComfyUI】太牛逼了!wavespeed延续“加速”赛道高潮!一体化的推理优化解决方案,通用,灵活,快速!
大家好,我是Jimmy。太震撼了兄弟们。上一期我们刚介绍完加速推理新王者——teacache,才刚上一天不到,圈里又炸出一个站在它肩膀上起飞的加速推理小王子——wavespeed!直接提升10倍速度。
上期介绍的teacache:【closerAI ComfyUI】太炸裂了!小节点大能量,一个能让FLUX生图、混元视频速度直线提升的技术!又快又好又简单!
我们已知在工作流中加入teacache的节点能提升1.4~2倍加速推理。
今天要介绍的是Comfy-WaveSpeed
Comfy-WaveSpeed 介绍
comfyUI地址:https://github.com/chengzeyi/Comfy-WaveSpeed/tree/main
ComfyUI的一体化推理优化解决方案,通用,灵活,快速。
它的原理是:
受TeaCache和其他去噪缓存算法的启发,引入了第一块缓存(FBCache),使用第一个Transformer块的残差输出作为该高速缓存指示器。如果当前和第一个Transformer块的先前残差输出之间的差足够小,则可以重用先前的最终残差输出,并跳过所有后续Transformer块的计算。这可以显著降低模型的计算成本,在保持高精度的同时实现高达2倍的加速。
主要有两个节点:
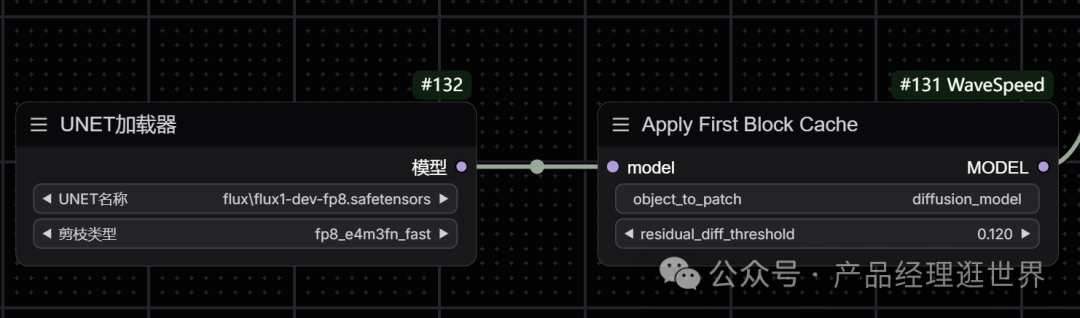
节点一:Apply First Block Cache
要使用第一个块缓存,只需将wavespeed->Apply First Block Cache节点添加到您的工作流中的Load Diffusion Model节点之后,并将residual_diff_threashold值调整为适合您的模型的值,0.12用于flux-dev.safetensors,带有fp8_e4m3fn_fast和28个步骤。预计将看到1.5倍到3.0倍的加速,精度损失可接受。
节点作者给出以下参数值:

节点接入方法如下:
节点二:增强torch.compile
要使用增强的torch.compile,只需将wavespeed->Compile Model+节点添加到您的工作流中的Load Diffusion Model节点或Apply First Block Cache节点之后。编译过程发生在您第一次运行工作流时,它需要相当长的时间,但它将被缓存以供将来运行。您可以传递不同的mode值以使其运行得更快,例如max-autotune或max-autotune-no-cudagraphs。与原始TorchCompileModel节点相比,该节点的优势之一是它与LoRA一起工作。
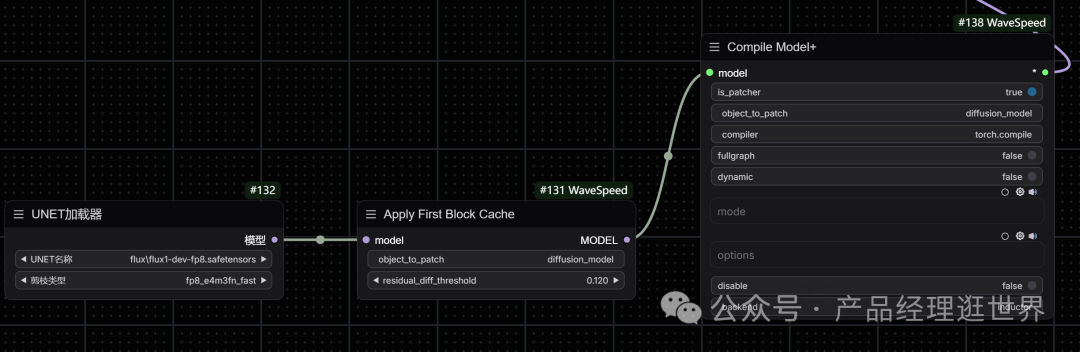
值得注意的是:torch.compile可能无法很好地处理模型卸载,您可以尝试在启动--gpu-only时传递ComfyUI以禁用模型卸载。
安装方法很简单了,没有太多复杂性,这里不介绍了。
先更新comfyUI,下载这个节点,解压放到comfyUI\custom_nodes\下。
以下是作者测试的结果:
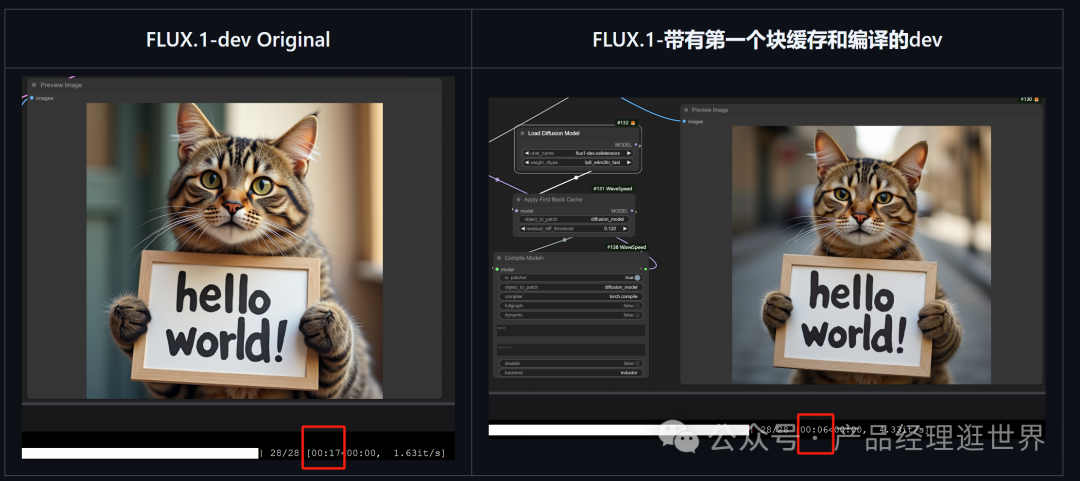
左边是原生生图速度,17s,右边是加入该节点后的生图速度:6s
我们也测试了一下:拉了一个 teacache与wavespeed测试的工作流:
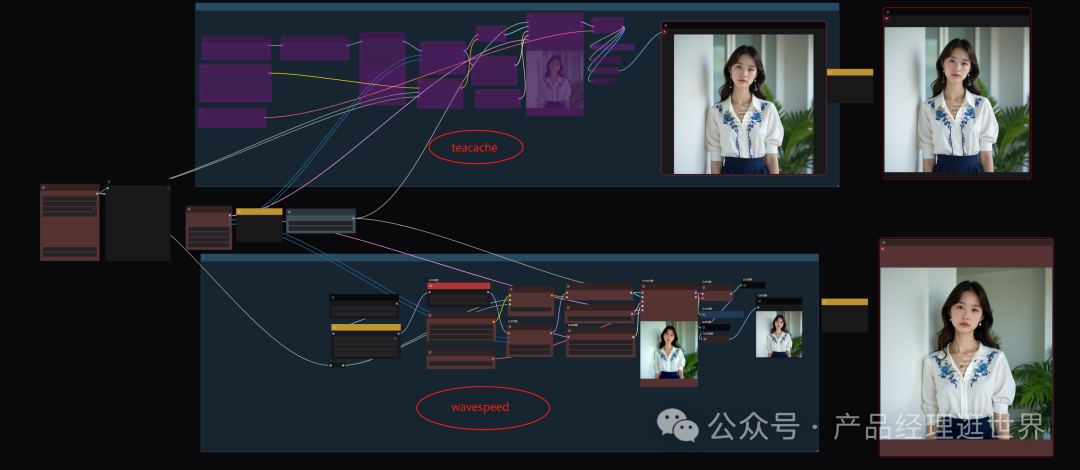
我们固定了随机种子。用的底模型是:flux fp8原生的,剪枝类型是默认。
在teacache中我们加速值 rel_l1_thresh值为0.4 。这是无损推理1.5倍提速。如果是1的话会有损失。我们选折中的来对比。
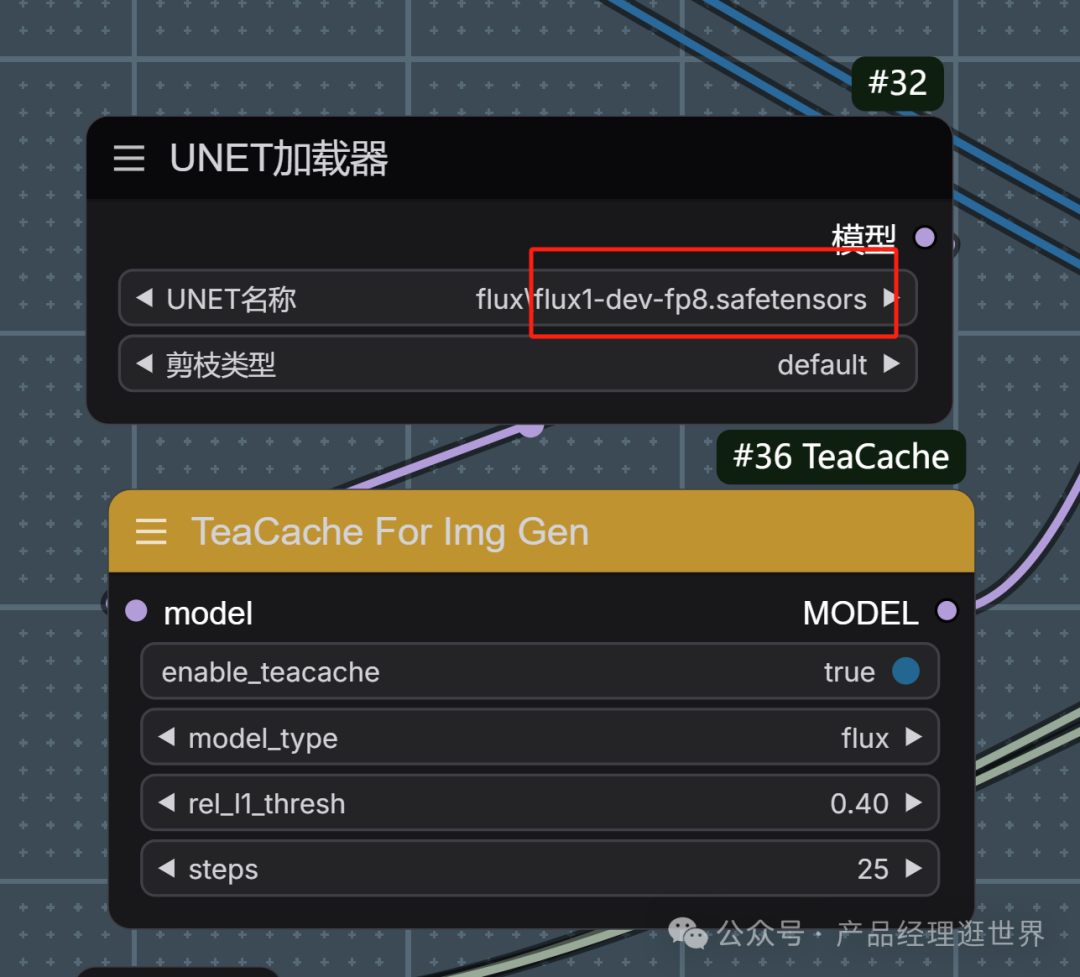
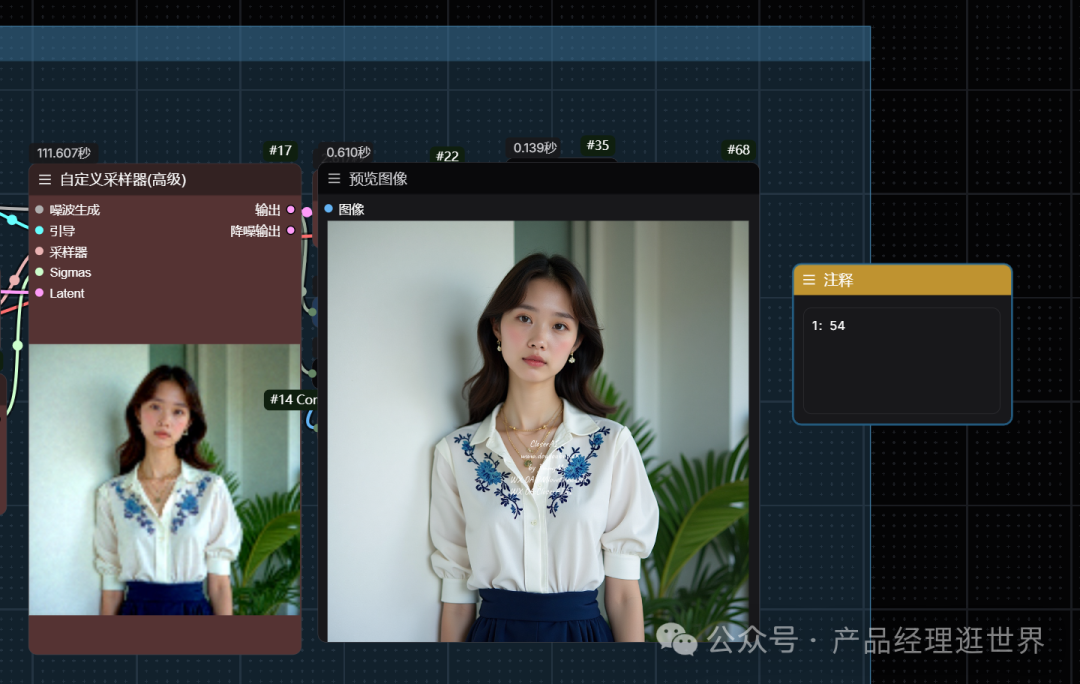
以下teacache是生图结果:用时1分54秒

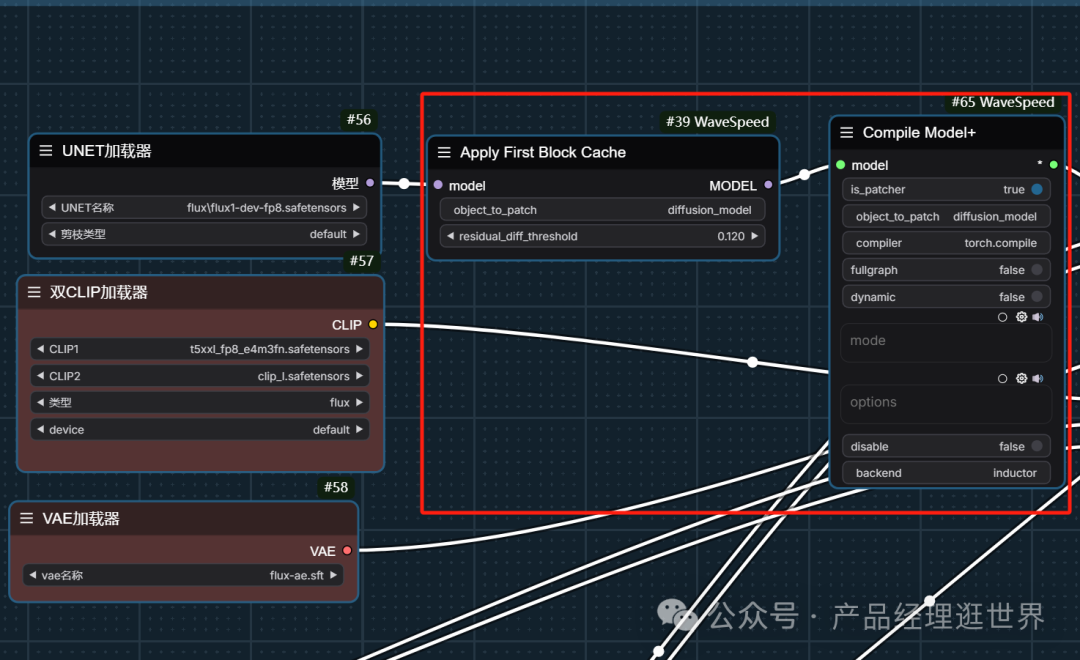
wavespeed中,我们这样接入,参数如下:我们用它默认值即可。
以下是结果:1分35秒。
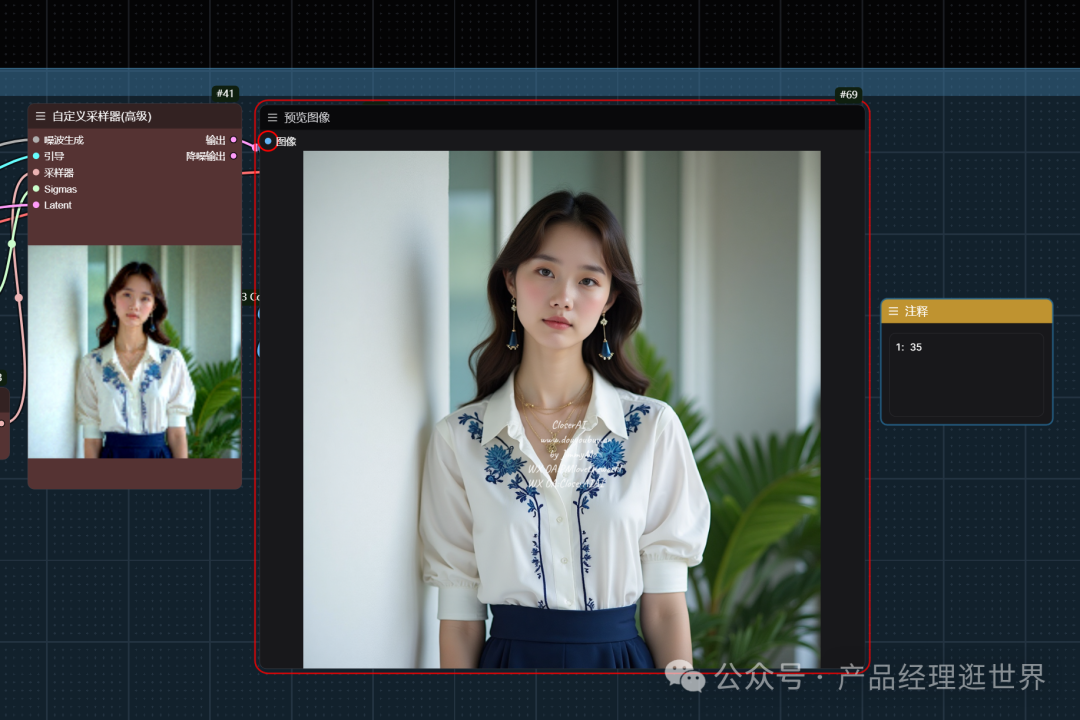

我们可见两者在生图质量相当的情况下,生图速度用时有点出入了。wavespeed会快一点点啦。
但整体上,跟我此前不用量化模型,直接用原生flux fp8的3半~4多的时间,直接节省了一半多。这里我就不测试原生生图速度了,我的配置是4060ti 8G啦。大家作参考就是。

结论:
二者都是在缓存上作优化从而实现提速。大家其实两个都可以用。大家可以多尝试它的值,找到符合自己配置的参数。
加载时会有点久,但整体不算久,在多次抽卡时,它的速度就会快。多次抽时,生图速度控制在1分钟


以上是closerAI团队对两个动态缓存加速推理方法的介绍和测试,大家可以根据工作流思路进行尝试搭建。当然,也可以在我们closerAI会站上获取应的工作流。
更多AI前沿科技资讯,请关注我们:http://aigc.douyoubuy.cn/
主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网
评论(0)