


更多AI前沿科技资讯,请关注我们:
closerAI-一个深入探索前沿人工智能与AIGC领域的资讯平台
【closerAI ComfyUI】视频生成继续卷!字节发布跨模态对齐统一视频生成框架Phantom,多图融合生成一致性视频!炸!
大家好,我是Jimmy。ByteDance的研究团队最近发布了一个名为Phantom的统一视频生成框架,旨在通过跨模态对齐实现单人和多人主体的视频生成。
Phantom:通过跨模态对齐实现主体一致的视频生成
https://hf-mirror.com/bytedance-research/Phantom
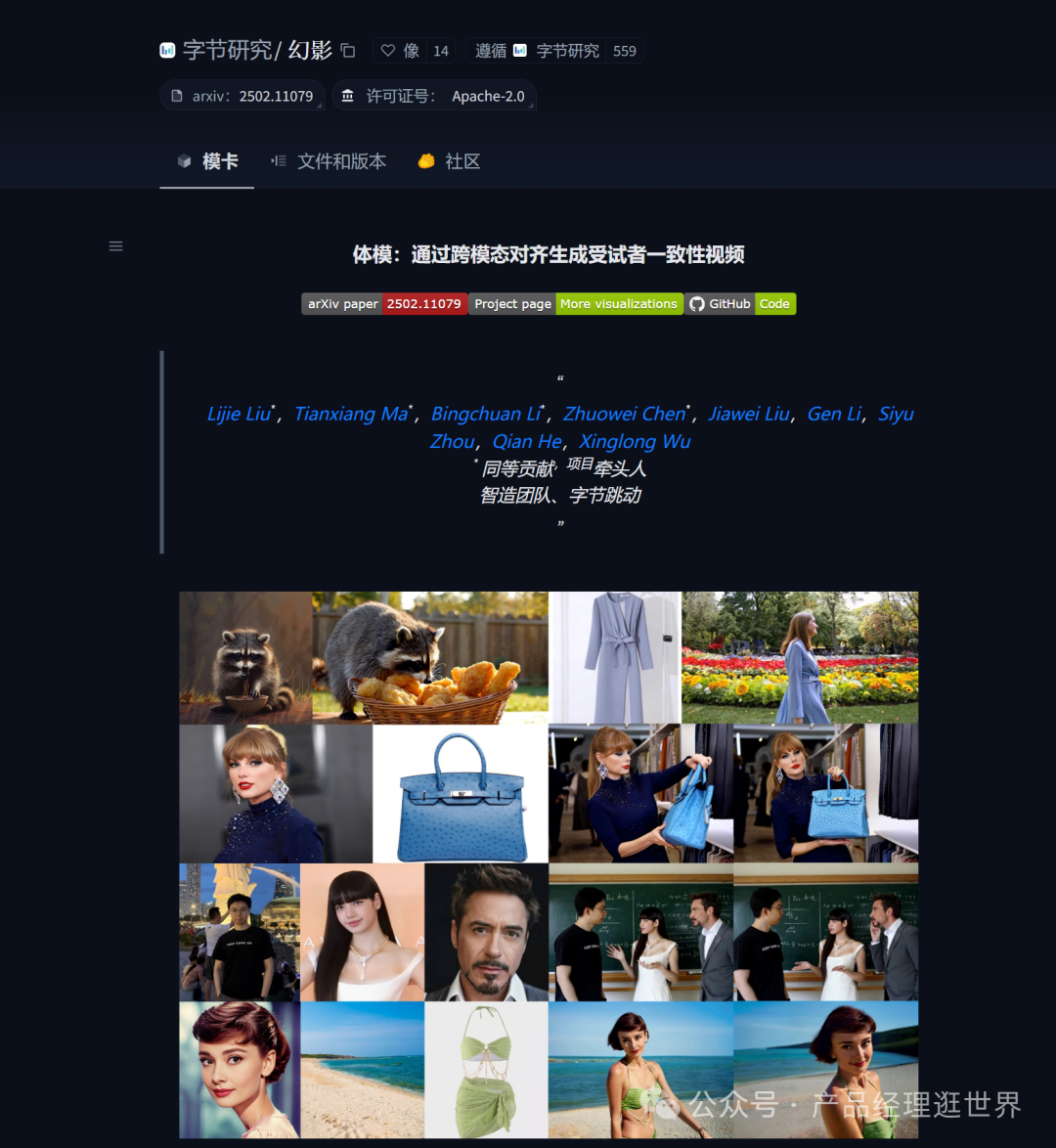
Phantom是一个基于现有文本到视频和图像到视频架构(wan2.1)的统一视频生成框架。它通过重新设计联合文本-图像注入模型来实现跨模态对齐,从而在人类生成的视频中强调主体一致性,并增强身份保留的视频生成能力。
主要特点
- 跨模态对齐:Phantom通过使用文本-图像-视频三元组数据来实现跨模态对齐,这使得模型能够更好地理解输入文本和图像的语义信息,并将其转化为高质量的视频内容。
- 主体一致性:在生成视频时,Phantom特别注重保持主体的连贯性和一致性,这对于生成涉及多个主体的视频尤为重要。
- 身份保留:Phantom在生成视频时能够保留输入图像中的身份特征,使得生成的视频在视觉上与输入图像保持一致。
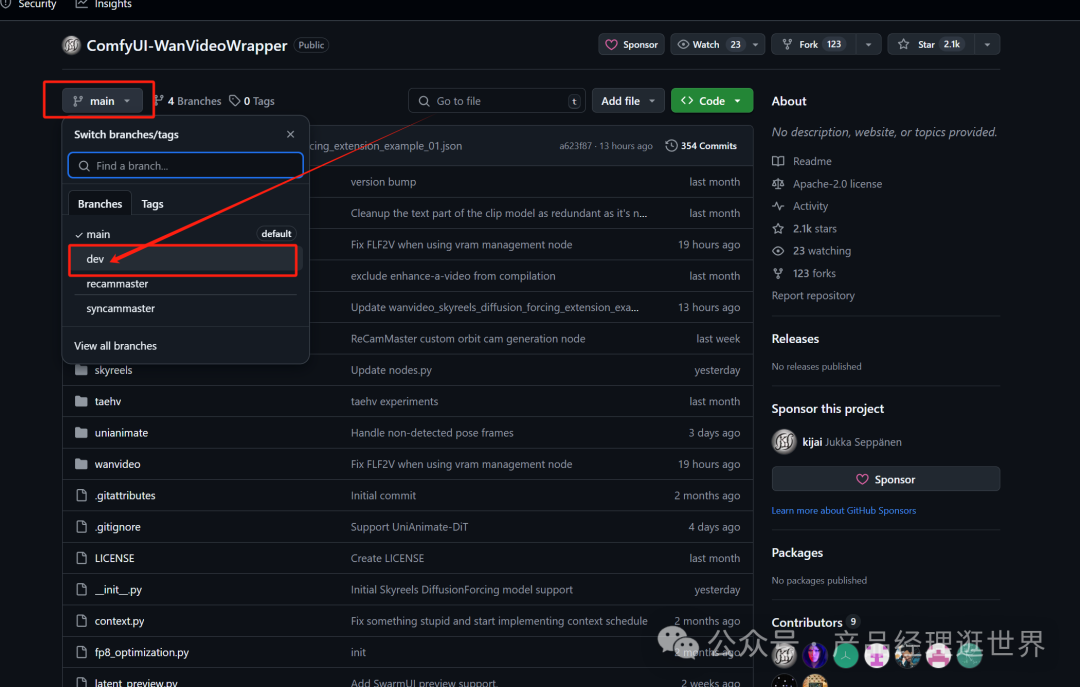
目前大佬kijai已在wanvideo节点中作更新,但目前还处于开发阶段。
大家可以在https://github.com/kijai/ComfyUI-WanVideoWrapper
在分支中选择dev,下载dev下的所有文件。如下图示:
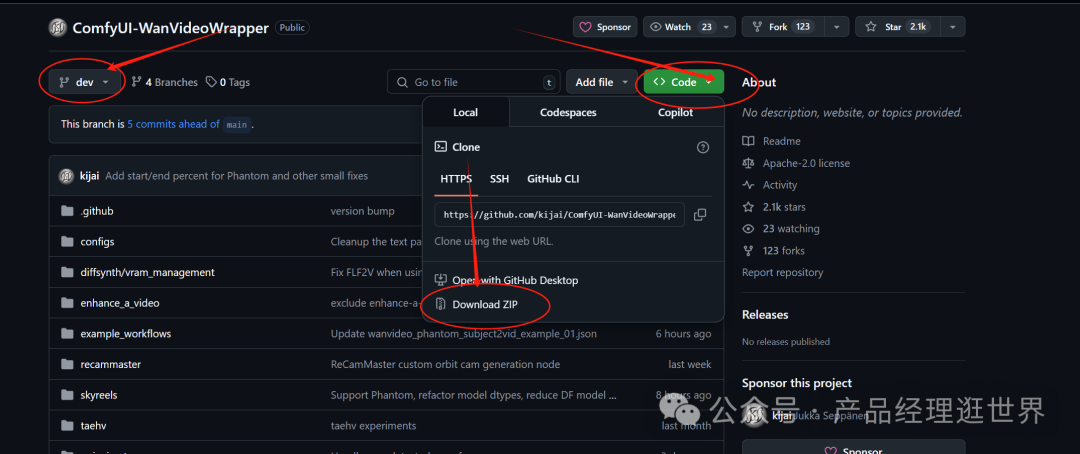
下载后,覆盖原来节点的文件。
模型要使用kijai版本的,在以下链接下载即可:
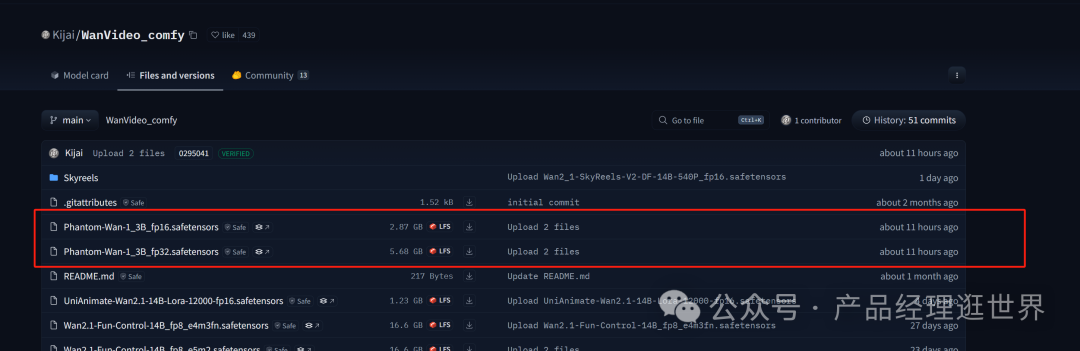
下载后,将模型放置:comfyUI/models/diffusion_models下。
Phantom的comfyUI中实现与体验
前面的模型和节点下载后,加载工作流打开。如下图示:
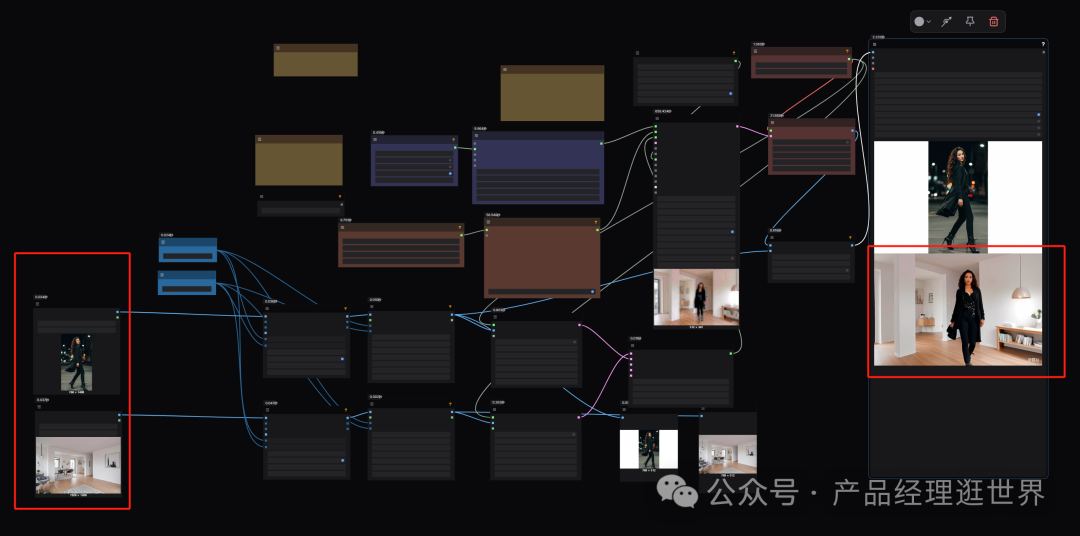
工作流加载节点中的示例工作流。
我添加了两张图进行融合测试,这里我使用的是KJ的FP16模型来生成视频,大家可以根据自己设备情况来选择合适的模型。
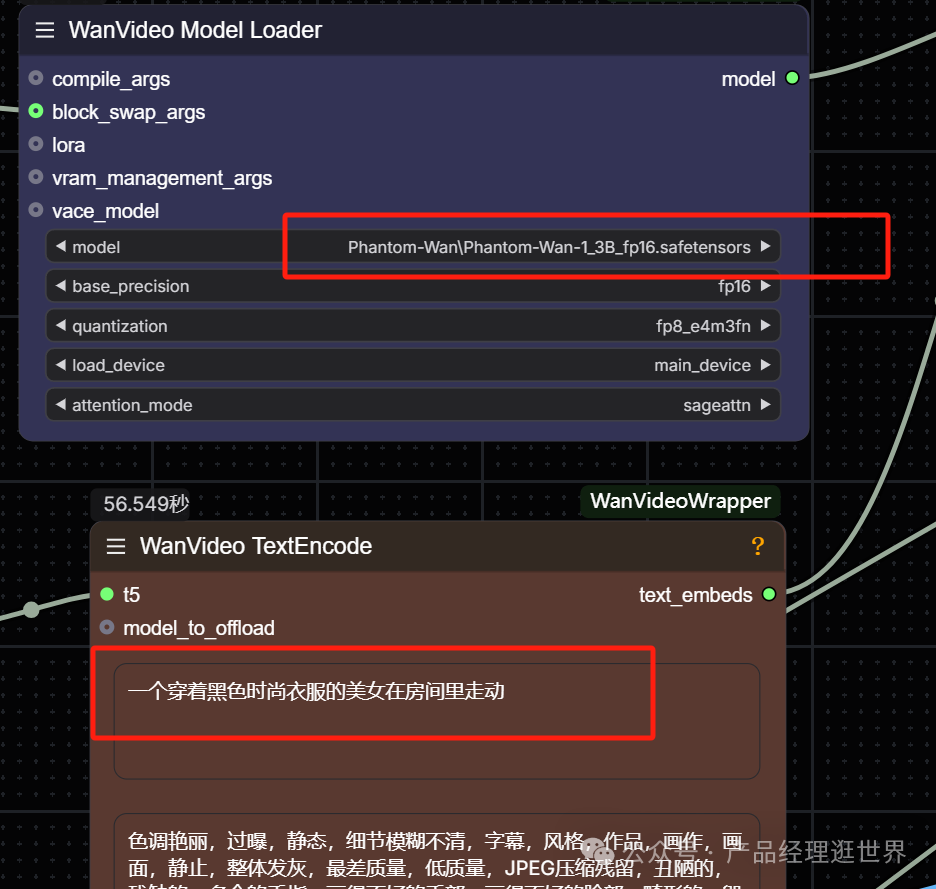
提示词我们是需要描述下的,这样更容易引导模型合成我们需要的内容。像物体、人物这些要简单描述。
一张人物,一张场景,如下:
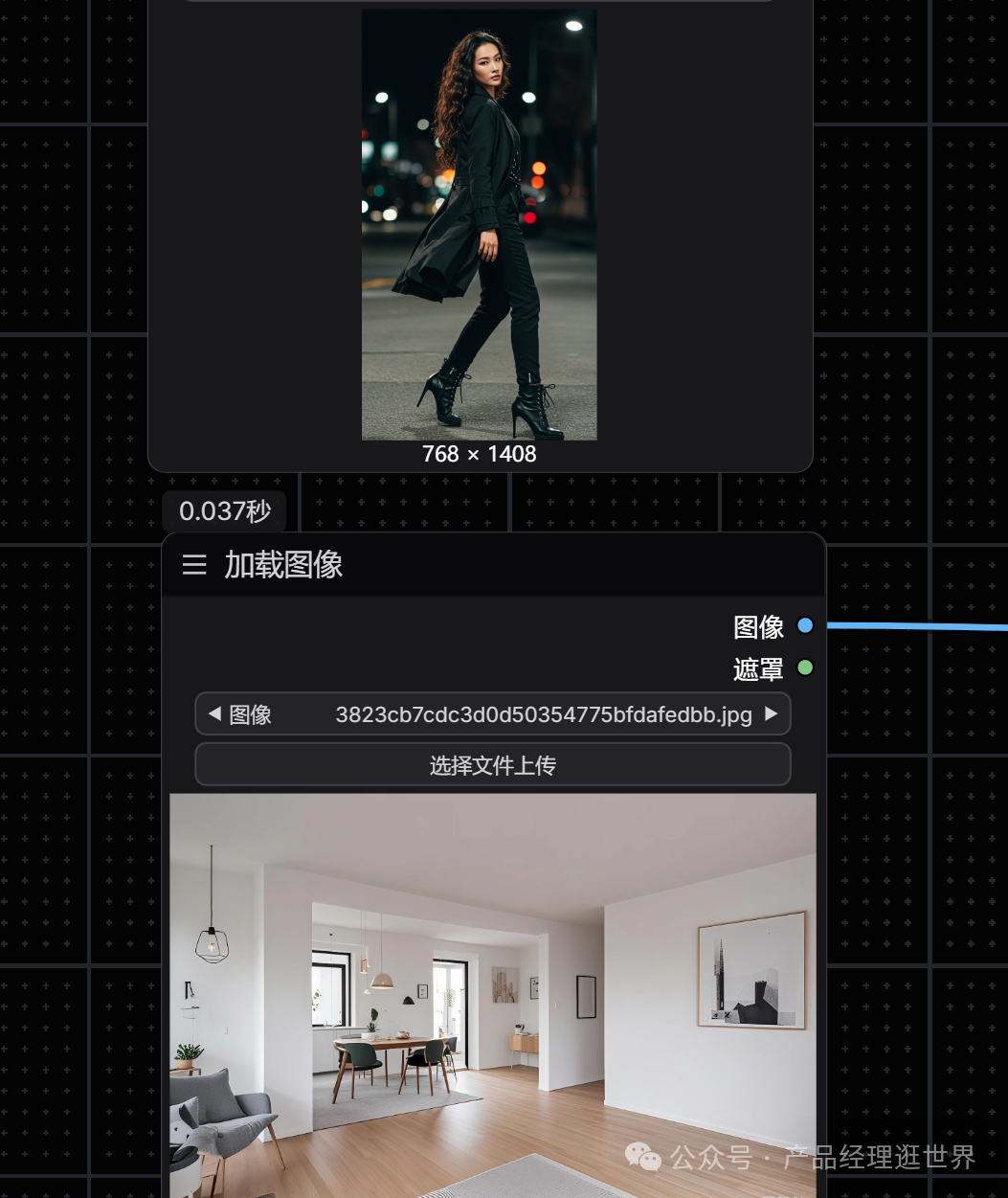
然后直接执行:以下是效果。我8G显存,跑了16分钟。大家作参考吧。

我们很直观地看出,人物的特征以及场景的一致性保持得很好,人脸虽然有点崩,但这仅是它开源的1.3B的模型,接下来还会开源一个14B模型。非常强!
本地算力不够怎么办?
如果本地设备算力不好的小伙伴,推荐使用线上comfyUI来运行体验:runninghub.cn
runninghub.cn framepack首尾帧工作流体验地址:
https://www.runninghub.cn/ai-detail/1914594578874466305
注册地址:https://www.runninghub.cn/?utm_source=kol01-RH151
通过这个链接第一次注册送1000点,每日登录送100点
最后几句:
Phantom的多图参考视频生成是基于万相视频生成训练的,得到这样的一个这么强的一致性融图,期待它的14B模型开源。它的价值在于,简化了我们为了保持人物一致性,花大量时间在生产图片中,在图片中先保持人物一致再进行图生视频的工作流,现在,它可以直接多图参考一起图生视频!
以上是closerAI团队制作的stable diffusion comfyUI closerAI
phantom多图融合视频生成工作流介绍,大家可以根据工作流思路进行尝试搭建。
当然,也可以在我们closerAI会员站上获取对应的工作流(查看原文)。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。
>/ 作者:JimmyMo
更多AI前沿科技资讯,请关注我们:
closerAI-一个深入探索前沿人工智能与AIGC领域的资讯平台

主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网
评论(0)