


更多AI前沿科技资讯,请关注我们:
【closerAI ComfyUI】最新最强的qwen-image-edit图像编辑模型单图编辑、多图编辑的体验分享与思考!
大家好,我是Jimmy。
qwen-image-edit编辑模型已推出几天了,大家都在尝试玩耍中。
下面分享一些这个过程中的一些心得与思考,以及我开发的节点的一些迭代方向。
一、为什么不沿用kontext dev的节点来实现而再开发一套节点来实现qwen-image-edit?
在comfyUI官方的qwen-image-edit的实现中,它开了一个节点以支持实现。正如当时kontext dev刚开源时,同样有一套实现的节点。
其实这就引发我的一个思考。为什么不沿用kontext dev的节点来实现而再开发一套节点来实现qwen-image-edit。我们先看主要两套节点:
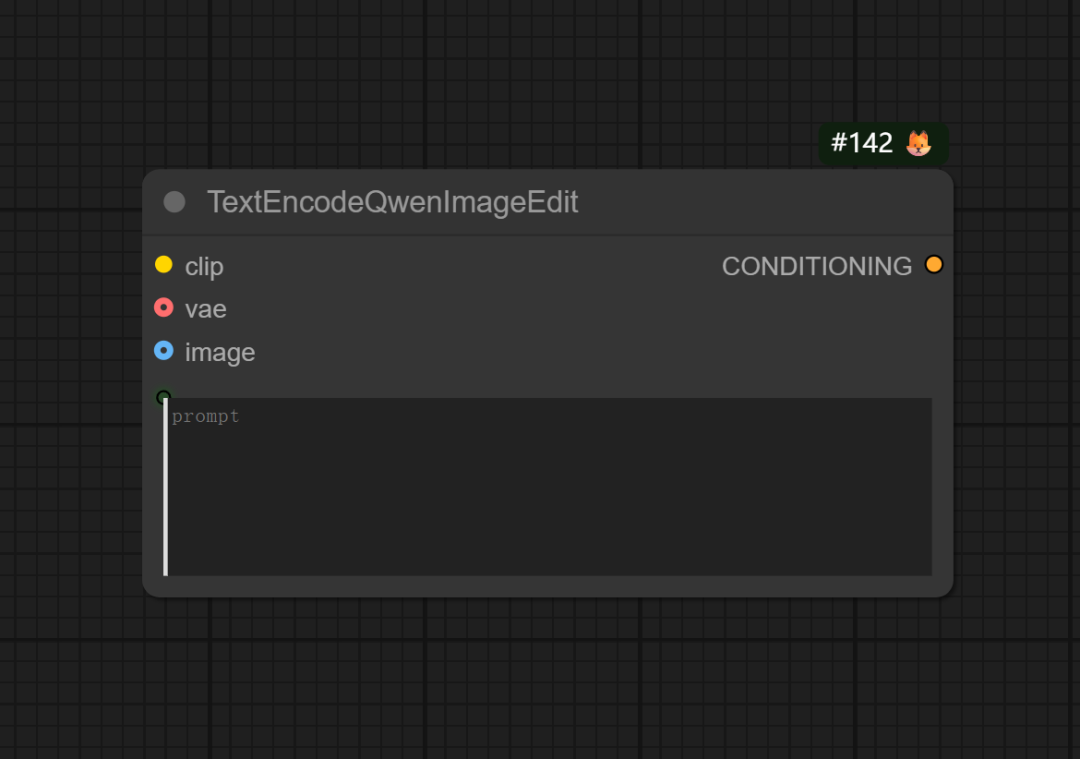
以下是qwen-image-edit的主要节点:TextEncodeQwenImageEdit
以下是flux kontext dev的主要节点:
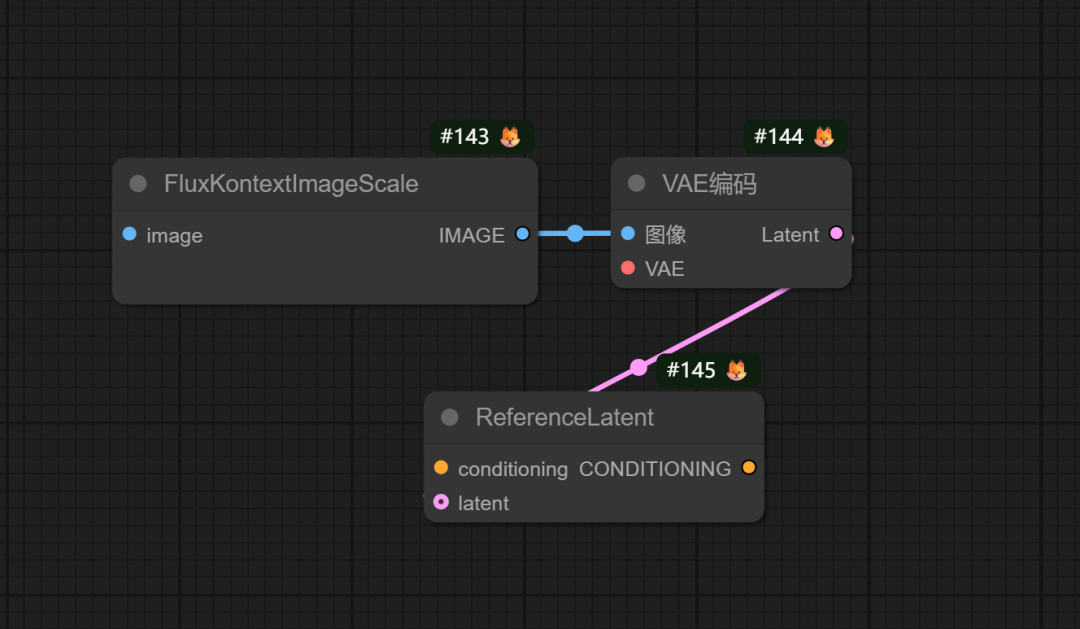
之所以为 Qwen-Image-Edit 开发一个全新的 TextEncodeQwenImageEdit 节点,而不是沿用 ReferenceLatent 节点,根本原因在于两种模型处理图像输入的方式在架构层面有着本质的区别。
1. ReferenceLatent 的工作方式:通用但“外挂”
ReferenceLatent 节点(以及类似它的工作流)代表了一种通用的处理参考图像的方法。它的核心逻辑是:
- 独立编码:使用一个标准的 VAE(变分自编码器)将输入的参考图像编码成一个潜空间张量(Latent Tensor)。
- 后期注入:将这个编码好的 latent,作为一个附加信息(通常键名为 "reference_latents"),“塞”进 CONDITIONING(条件)数据流中。
- 模型通用性:这种方法不关心文本编码器(CLIP)是如何处理提示词的。它假设扩散模型(U-Net)的某些部分(例如通过交叉注意力机制)能够理解并使用这个被注入的参考 latent。Kontext-dev 模型就是为此设计的,它能识别并利用这种方式提供的参考潜空间。
这种方式的好处是模块化和通用性强,但它意味着图像和文本是作为两个相对独立的条件信息进入模型的。
2. TextEncodeQwenImageEdit 的工作方式:原生且“一体化”
Qwen 系列的多模态大模型(包括 Qwen-Image-Edit)采用了完全不同的架构。它们不是在后期注入一个图像的潜空间,而是在最前端的文本编码(Tokenization)阶段就将图像和文本融为一体。
可能太多专业术语理解有困难,请看下面解析:
你要请一位说中文的厨师(Qwen模型)和一位说英文的厨师(Kontext模型)分别做一道“参照照片的番茄炒蛋”。
对于说英文的厨师 (Kontext模型)
- 你:告诉他 “请做一份番茄炒蛋”。(这相当于输入提示词)
- 翻译:找一个翻译,把“番茄炒蛋”翻译成英文 “scrambled eggs with tomatoes” 再告诉厨师。(这相当于普通CLIP编码器)
- 递照片:你把一张菜品的照片单独递给厨师说:“照着这个做”。(这相当于ReferenceLatent节点,它把照片“翻译”成厨师能理解的样子——潜空间)
这位厨师是分开接收“做什么菜”的指令和“长什么样”的参考图的。ReferenceLatent 节点就是那个专门负责“递照片”的助手。
对于说中文的厨师 (Qwen模型)
这位厨师非常特别,他要求你把所有信息写在一张纸上一起给他。
- 你:你不能分开给指令和照片。你必须在一张纸上,把照片贴在文字旁边,然后写上 “请参照这张图做一份番茄炒蛋”。
- 新的翻译:这时,你需要一个更厉害的新翻译(TextEncodeQwenImageEdit节点),他不仅能翻译文字,还能看懂你贴在纸上的照片,然后把“照片+文字”作为一个整体,完整地翻译成一条厨师能懂的指令。
这个新翻译(TextEncodeQwenImageEdit)的工作方式是图文一体的。它在翻译的最开始阶段,就把图片和文字“打包”在了一起。
以上就是这个问题的答案,我跟大家一样不懂,但是qwen有技术报告,虽然报告是全英文,但AI会读和理解啊。让它总结就行。这是我问LLM,LLM给我的答复。
为什么要知道这个信息?因为开始我也尝试用qwen-image-edit模型这样接:
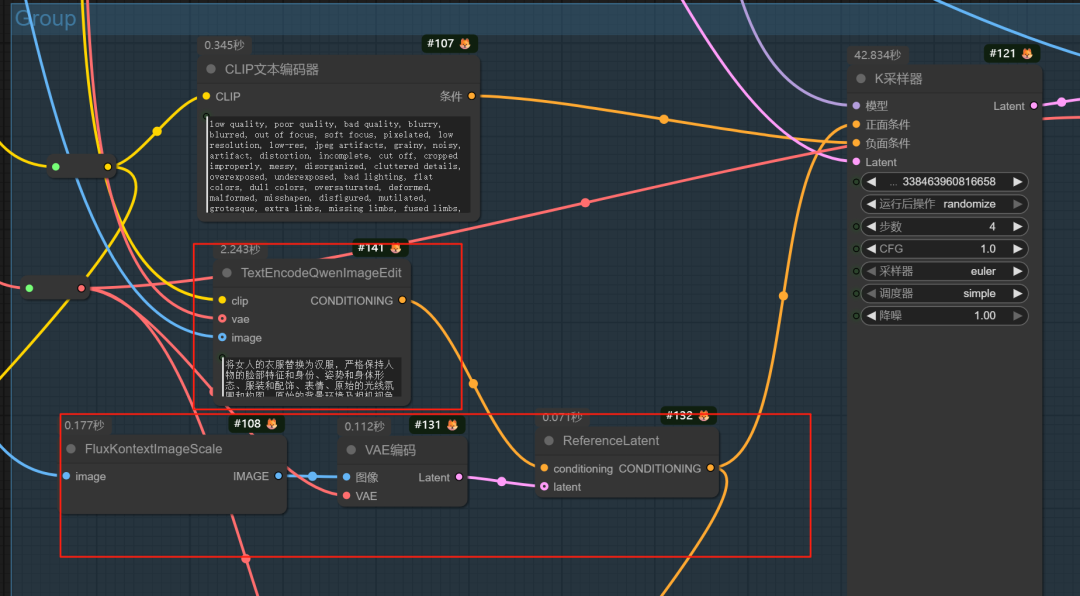
或者撇开TextEncodeQwenImageEdit直接使用ReferenceLatent ,你会发现,看下面截图:
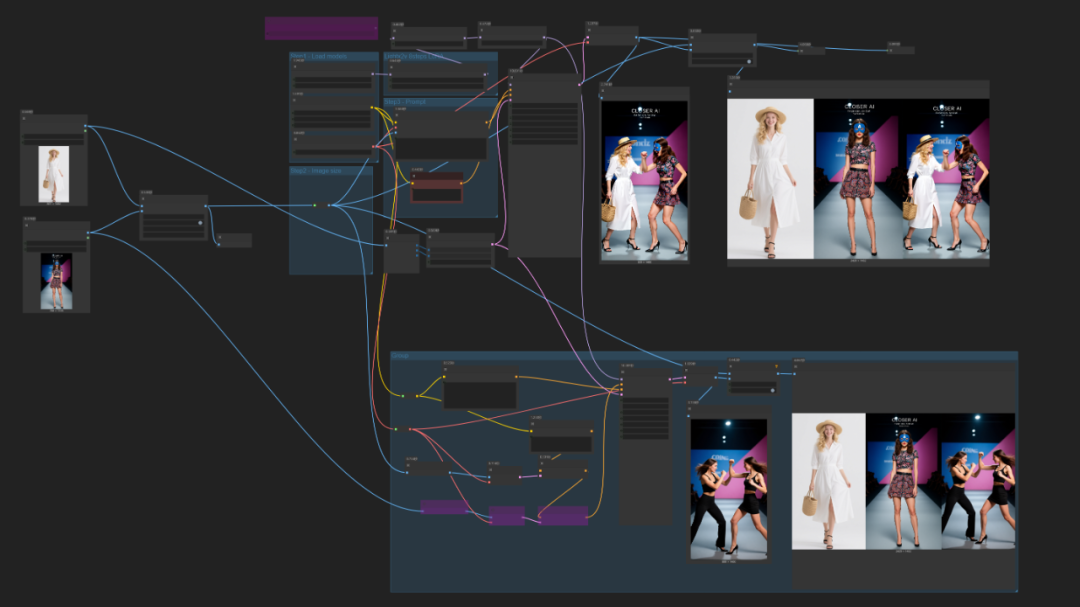
上面的结果是接入TextEncodeQwenImageEdit节点的工作流生产的:

下面的是接入ReferenceLatent节点生成的:

这个测试工作流的结果,很好地说明了这一点,“图文一体”与“分别”的差异性,所以,如果你也尝试使用ReferenceLatent节点来接入qwen edit来使用,特别是想实现多图融合时,想通过这种“分别”的方式来实现是不会成功,因为这是框架和模型的差异性决定了。所以,comfyUI官方针对不同模型开发对应实现的节点是有它的一套逻辑的。
我没说接入ReferenceLatent节点不对,毕竟尝试才会知道,我也尝试生成了好多张,所以我放弃了这种思路,直接拥抱官方TextEncodeQwenImageEdit节点!
所以拆解分析官方TextEncodeQwenImageEdit节点,了解指令,这能让多图融合更容易实现我们想要的效果。这是我开发comfyUI qwen-image-edit提示词生成器节点的很重要方向,就是生成qwen系统指令!(在开发中)
二、qwen-image-edit多图融合的心得
单图编辑能力强不用多说了,单图编辑官方说明也出了很多事例,主要是多图。根据上面我们分析qwenimageedit,我们得知,图文一体。所以图不可能分开两次输入了,只能是一次输入,也就是需要拼起来一次输入。
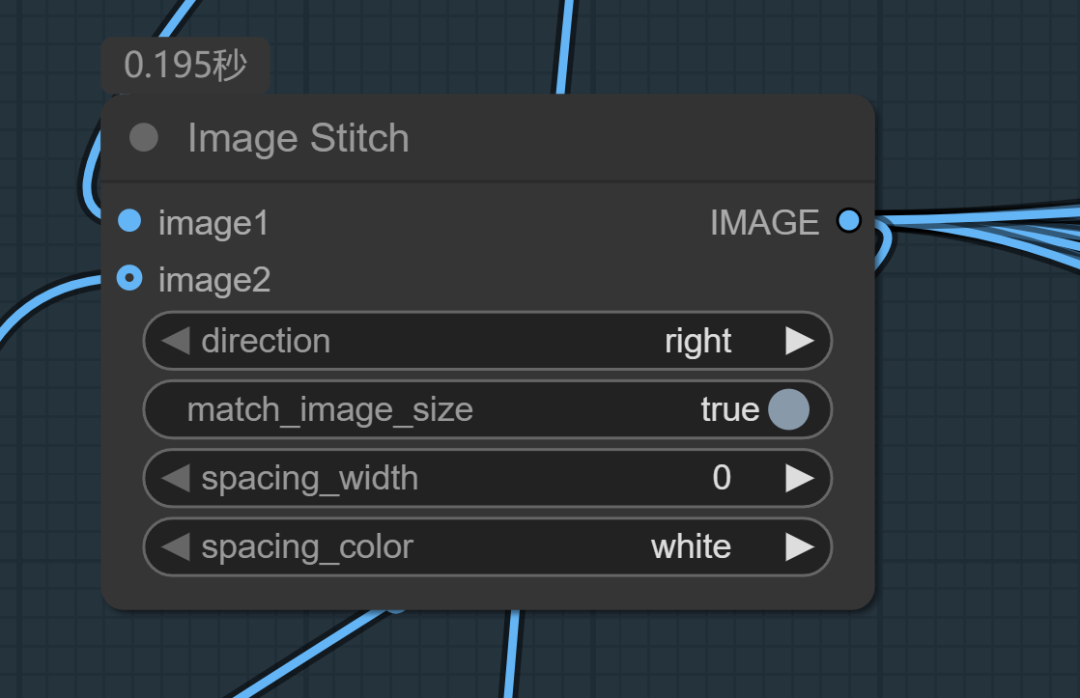
图像联结也可以。直接提示词写下内容即可。


但如果你想直接让它完成指定服装的换装,换指定内容的东西时,
如,将女人衣服图案换成右边的。

你要抽很多次卡才会有结果:





难出效果,我觉得就是上面谈到的qwen系统指令的原因,所以根据编辑任务生产特定任务下的指令可以尝试一波。
本地算力不够怎么办?
如果本地设备算力不好的小伙伴,推荐使用线上comfyUI来运行体验:runninghub.cn
阿里千问qwen-image-Edit图像编辑(4步加速)应用体验地址:
https://www.runninghub.cn/ai-detail/1957729600010907649
注册地址:https://www.runninghub.cn/?utm_source=kol01-RH151
通过这个链接第一次注册送1000点,每日登录送100点
最后几句:
还在体验,还在思考,还在挖掘qwen-image-edit更多可能性。下期再分享。
以下是我开发的节点,配合qwen-image能高效出片:
1、comfyUI qwen-image-edit提示词生成器节点:
http://aigc.douyoubuy.cn/2025/08/20/2615/
2、closerAI 图像循环助手节点:
http://aigc.douyoubuy.cn/2025/07/05/2137/
3、closerAI可视化中文编辑节点:
http://aigc.douyoubuy.cn/2025/08/11/2545/
4、closerAI 自由组合节点:
http://aigc.douyoubuy.cn/2025/07/24/2305/
6、closerAI NAG_Sampler节点:
http://aigc.douyoubuy.cn/2025/07/28/2354/
以上是closerAI团队制作的stable diffusion comfyUI closerAI开发的节点以及
closerAI kontext 对话式多轮单图编辑修复放大工作流介绍,大家可以根据工作流思路进行尝试搭建。
当然,也可以在我们closerAI会员站上获取对应的工作流(查看原文)。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。
>/ 作者:JimmyMo
更多AI前沿科技资讯,请关注我们:

主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网

评论(0)