


更多AI前沿科技资讯,请关注我们:
【closerAI ComfyUI】图像与视频反推神器:Qwen3-VL,速度快又精准,复刻从此开启,电影/短剧/片段等通通搞掂
大家好,我是Jimmy。
前两期介绍了视频生成领域的两个重要的生态补充项目:SeC模型和FlashVSR超分。今天再推荐一个犹如写轮眼复刻一般能力的项目,Qwen3-VL视觉模型。社区已经有大佬在comfyUI中复现出来了。这使得在开源反推项目中是最强的存在了。它能描述图片与视频,这使用在视频生成时,我们完全能复刻出人、场、景三个主要的元素。
comfyUI中的实现:
项目地址:https://github.com/IuvenisSapiens/ComfyUI_Qwen3-VL-Instruct
它的安装与使用也很简单。完全没有难度。
1、直接下载节点放置custom_nodes中
2、拉出以下节点到工作流中,它自动下载模型。
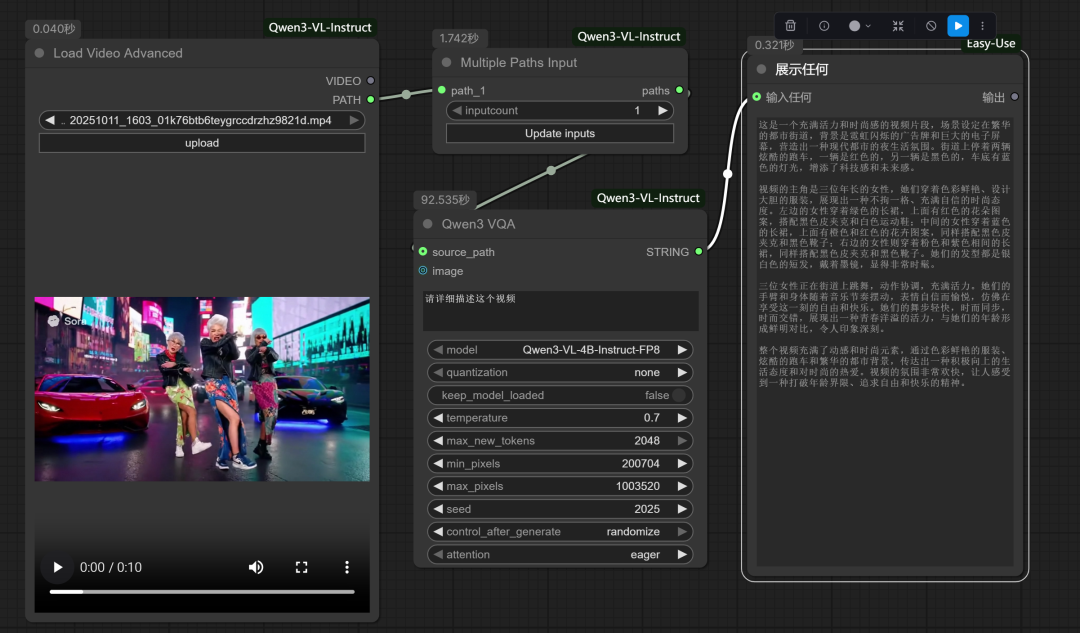
我们加载一个视频:
这是用索拉生成的说唱视频,我们来看看:
通过Qwen3-VL。得到了以下详细描述:
视频中,三位年长的女性在繁华的都市街头跳舞,背景是闪烁的霓虹灯和巨大的广告牌,营造出一种充满活力和现代感的氛围。她们穿着色彩鲜艳、设计独特的服装,分别穿着绿色、蓝色和粉色的长裙,搭配黑色皮夹克和时尚配饰,展现出自信和活力。她们的头发都精心打理,有的戴着墨镜,有的戴着发饰,整体造型极具个性。 在她们身后,两辆豪华跑车停在路边,一辆红色,一辆黑色,车底发出蓝色的灯光,增添了科技感和时尚感。背景中的广告牌上显示着各种品牌和广告,如“LE BERGE”和“ZENS”,进一步强化了都市的繁华和现代感。 三位女性的动作协调一致,她们随着音乐节奏舞动,动作充满活力和自信,时而挥动手臂,时而跳跃,展现出一种不拘一格的自由和快乐。她们的表情洋溢着喜悦和自信,仿佛在享受这一刻的自由和快乐。 视频中的说唱内容虽然没有直接展示,但从她们的舞蹈和背景可以感受到一种充满活力和自信的氛围,她们似乎在表达对生活的热爱和对自我表达的追求。整体来看,这个视频通过时尚的服装、炫目的背景和充满活力的舞蹈,传达出一种积极向上、不拘一格的生活态度。
然后,我们通过反推出来的提示词,使用视频生成模型来进行复刻,同样这里使用索拉来生成:
从生成的效果看,能完全生成原视频中有的内容,因为是文生视频,所以基本上改有的内容都有了。所以基于这个思路,我们完全能够利用它来反推分镜,人物设计、衣服设计、场景设计的内容。有个不足的地方就是对音频不能分析。那也无所谓。音频与对白我们再自己添加。
也就是,qwen3-vl能帮我们解决看得到的内容的提示词,听得到需要我们再另外补充。上面老奶奶说唱就是我在后补充了下说唱的提示词。
接着,我们如果想复刻分镜的画面,例如我用我自己的形象用索拉生成的香港古惑仔的视频:
节点中反推指令修改下:
请详细描述这个视频包括每个分镜出现的时间与内容,得到以下结果:

将它复制到索拉中,得到以下视频:
我也拿gemini来对比了一个。
当然,这里使用的是gemini-2.0-flash-thinking模型,用的是API来实现,能力当然会出色点。得到结果如下:很详细。同样因为不能同时分析视频与音频,我这里先分析视频:

然后再利用gemini分析音频:

很完美。
所以,在制作AI视频时候,我们如果想利用某个视频的场景,一是可以直接截图然后利用LLM进行反推提示词。二是使用qwen3-vl模型来反推(图像与视频均可)。
当然,这得看大家自己的情况使用了。
最后总结下,利用LLM分析视频,其中使用comfyUI qwen3-vl节点可免费分析视频。利用这样的方式可复刻场景。如果大家能使用到gemini,我也推荐使用它来完成提示词。
使用它更简单,不用本地作推理,调用免费的API够用,将视频分析结果与音频分析结果进行相加,再经过LLM融合形成新的可用于文生视频的提示词,工作流如下:
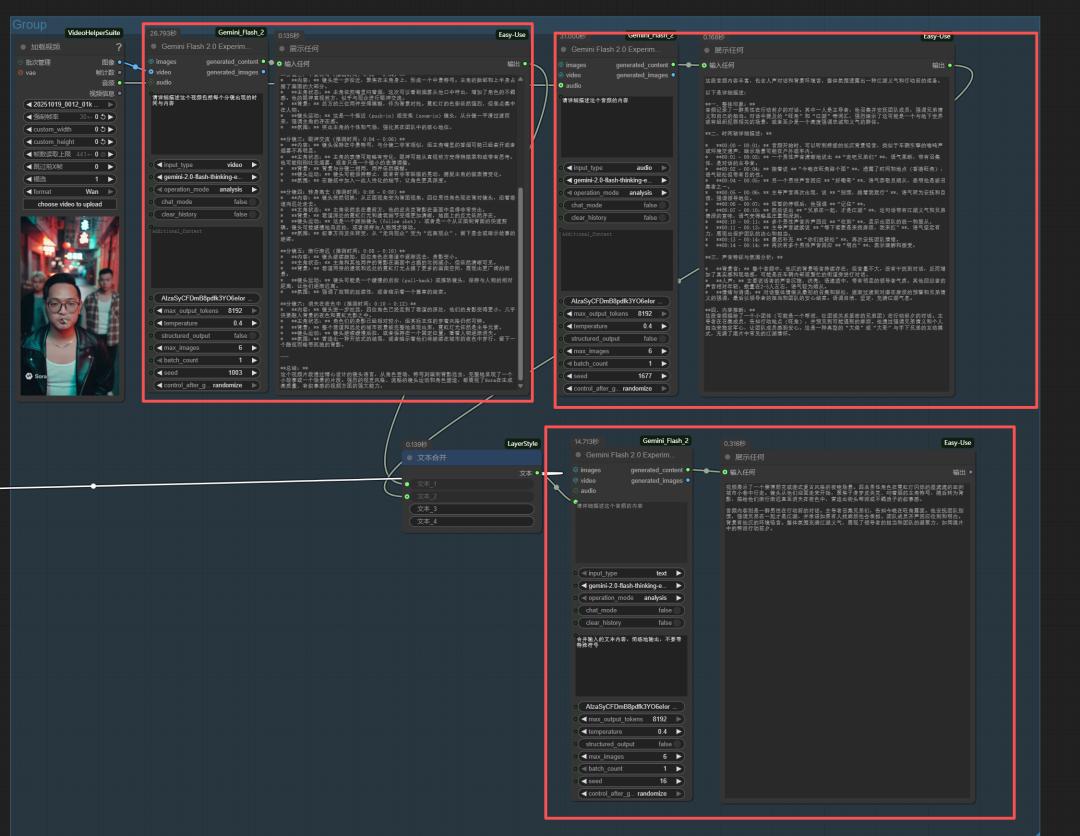
然后在索拉中生成视频:
以上仅作示范。并提供实现思路给大家。对你有帮助,请一键三连支持下我谢谢啦。
本地算力不够怎么办?
如果本地设备算力不好的小伙伴,推荐使用线上comfyUI来运行体验:runninghub.cn
FlashVSR 视频高清化/超分应用体验地址:
https://www.runninghub.cn/ai-detail/1979417336983752705
注册地址:https://www.runninghub.cn/?utm_source=kol01-RH151
通过这个链接第一次注册送1000点,每日登录送100点
最后几句:
如果对你有帮助,请一键三连支持下我,感谢
以下是我开发的节点,配合kontext能高效出片:
1、comfyUI kontext 标注助手节点:
http://closerai.douyoubuy.cn/2025/07/01/2089/
2、comfyUI kontext提示词生成器节点:
http://aigc.douyoubuy.cn/2025/06/30/2062/
3、closerAI 图像循环助手节点:
http://aigc.douyoubuy.cn/2025/07/05/2137/
4、closerAI 自由组合节点:
http://aigc.douyoubuy.cn/2025/07/24/2305/
5、closerAI 自动白边处理节点:
http://aigc.douyoubuy.cn/2025/07/28/2357/
6、closerAI NAG_Sampler节点:
http://aigc.douyoubuy.cn/2025/07/28/2354/
7、comfyUI kontext提示词生成器网页应用:
http://aigc.douyoubuy.cn/closerai-flux-kontext/
8、closerAI 图像自由组合在线版
http://aigc.douyoubuy.cn/closerai-imagefree/
以下是qwen-image相关节点:
以下是我开发的节点,配合qwen-image能高效出片:
1、comfyUI qwen-image-edit提示词生成器节点:
http://aigc.douyoubuy.cn/2025/08/20/2615/
2、closerAI可视化中文编辑节点:
http://aigc.douyoubuy.cn/2025/08/11/2545/
以上是closerAI团队制作的stable diffusion comfyUI
closerAI qwen3-VL和Gemini视频/图像分析工作流1019介绍,大家可以根据工作流思路进行尝试搭建。
当然,也可以在我们closerAI会员站上获取对应的工作流(查看原文)。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。
>/ 作者:JimmyMo
更多AI前沿科技资讯,请关注我们:

主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网

评论(0)