


更多AI前沿科技资讯,请关注我们:
【closerAI ComfyUI】开源视频模型新王:LTX-2,重新定义影音同步的 AI 视频创作新标准,多种控制引导实现精确创作!

大家好,我是Jimmy。2026年刚来不久,沉寂一年的LTX终于再次出来,发布了LTX-2模型。这次,它将音画同步生成的门槛再次降低,目前开源界新王。
LTX-2:定义 4K 影音同步的 AI 视频创作新标准
近日,Lightricks 正式推出了其旗舰级视频生成模型 LTX-2。这不仅是一个技术升级,更是一个完整的影音生产引擎。它解决了 AI 视频创作中最大的痛点:画面与声音的自然同步,并首次在开源领域实现了生产级别的 4K/50 FPS 输出。
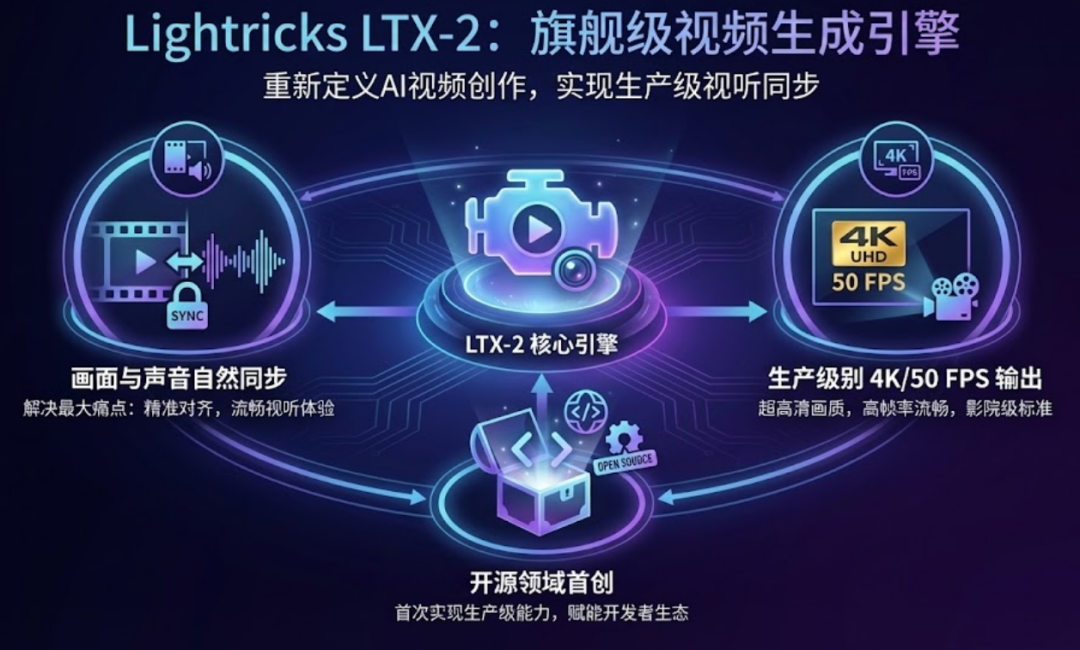
1. 核心技术突破:声画一体,视听交织
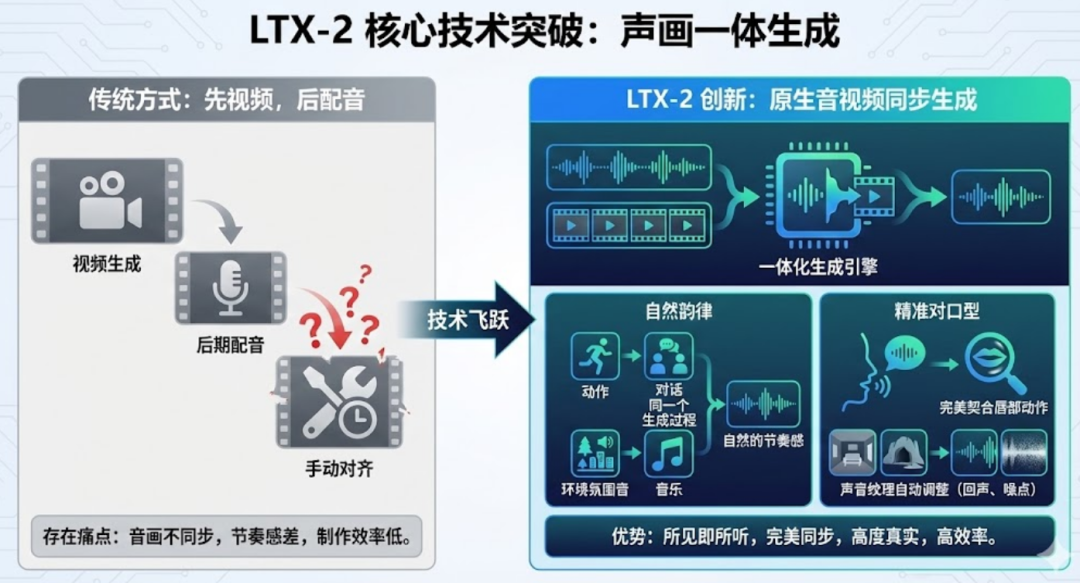
LTX-2 彻底告别了“先画后音”的落后模式。
- 原生同步生成: 运动、对话、氛围音和音乐在同一个生成过程中自然涌现。
- 电影级对话: 无论何种语言,模型都能生成精准的口型动画,并根据环境(如大厅回声或窄室闷响)实时调整声音质感。
2. 生产力性能:20 秒长格式与 50 FPS 丝滑体验
针对专业影视与广告需求,LTX-2 提供了突破性的性能支持:
- 20 秒超长剪辑: 告别以往 3-5 秒的局限,LTX-2 支持长达 20 秒的高保真视频生成,保持风格与身份的一致性。
- 原生 4K / 50 FPS: 以真正的 4K 分辨率和每秒 50 帧的高帧率输出,确保动态画面无拖影,完美适配影院大幕和高清直播。
- 双工作流方案:
- Fast Flow(快速模式): 极速迭代,适合创意脑暴与快速原型。
- Pro Flow(专业模式): 极致细节与超强稳定性,专为最终成品输出打造。

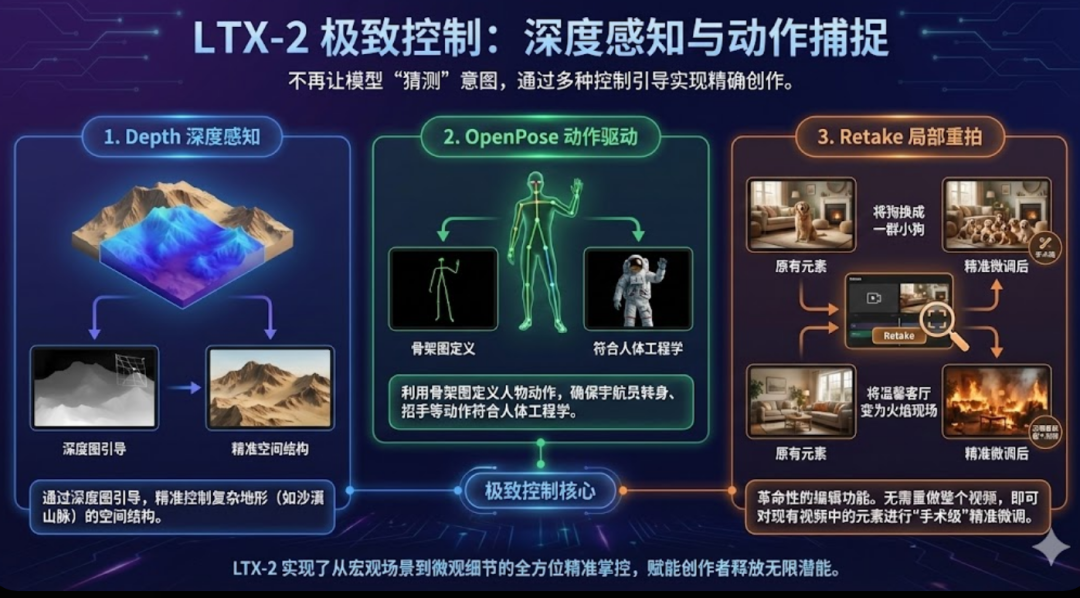
3. 极致控制:深度感知与动作捕捉
LTX-2 不再让模型“猜测”你的意图,而是通过多种控制引导实现精确创作:
- Depth 深度感知: 通过深度图引导,精准控制复杂地形(如沙漠山脉)的空间结构。
- OpenPose 动作驱动: 利用骨架图定义人物动作,确保宇航员转身、招手等动作符合人体工程学。
- Retake 局部重拍: 革命性的编辑功能。无需重做整个视频,即可对现有视频中的元素(如将狗换成一群小狗,或将温馨客厅变为火焰现场)进行“手术级”精准微调。
4. 拥抱开源:人人皆可部署
LTX-2 采用了**开放权重(Open Weights)**策略,这一举动震动了整个社区:
- 本地化运行: 模型针对 NVIDIA RTX 系列显卡(包括最新的 RTX 50 系列)进行了深度优化,甚至可以在 12GB-16GB 显存的消费级 GPU 上运行量化版本(如 NVFP8)。
- 生态集成: 已深度支持 ComfyUI。通过 weight streaming 技术,即使 VRAM 有限,也可以通过调用系统内存来生成复杂的大尺寸模型。
- 商业许可: 对个人用户和年营收 1000 万美元以下的小型企业免费开放(非商业或小型商业用途)。
comfyUI LTX-2安装与体验
地址:https://ltx.io/model/ltx-2
模型地址:https://huggingface.co/Lightricks/LTX-2
仓库地址:https://github.com/Lightricks/LTX-2
目前comfyUI已原生支持。方法很简单,更新至最新的comfyUI。同时在comfyUI模板中找到示例工作流:
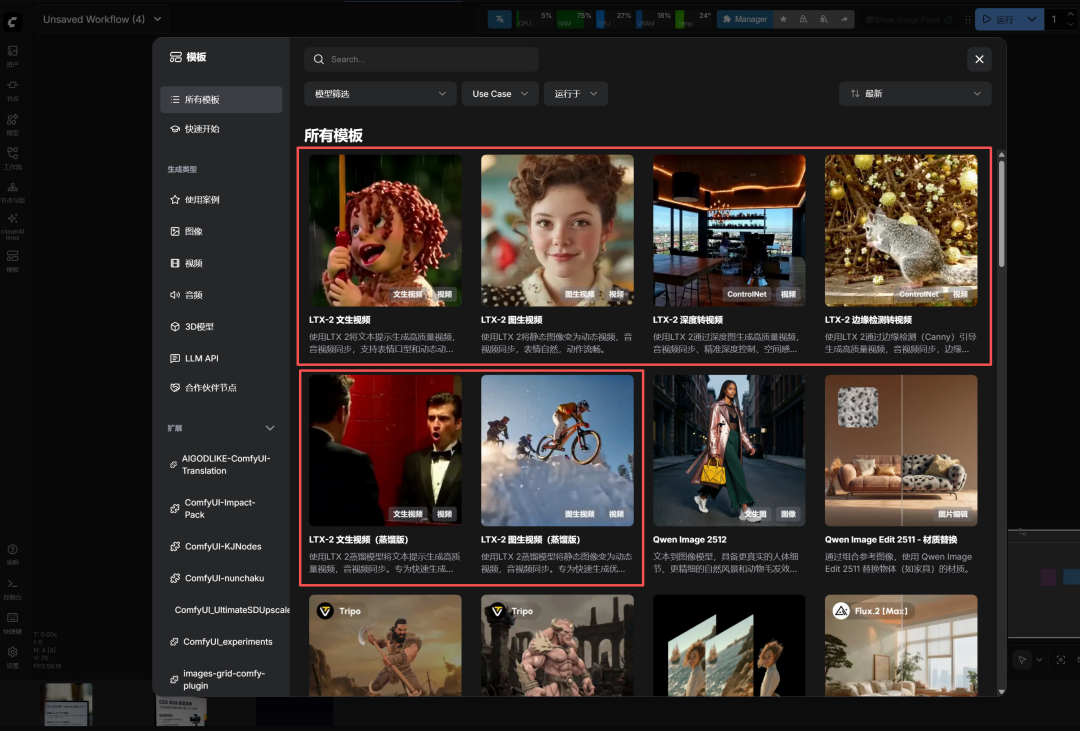
工作流有了,其次是需要下载模型,我们先看它开源的模型:
开源主要模型有:

主要模型版本概括如下:
- LTX-2-19b-dev: 190亿参数的开发版,支持 bf16、fp8 和 nvfp4 量化,适合微调。
- LTX-2-19b-distilled: 8步极速蒸馏版,用于快速原型设计。
- 放大器模型: 提供专门的空间(x2)和时间(x2)放大器,用于提升分辨率和流畅度。
还有一系列的控制LORA:
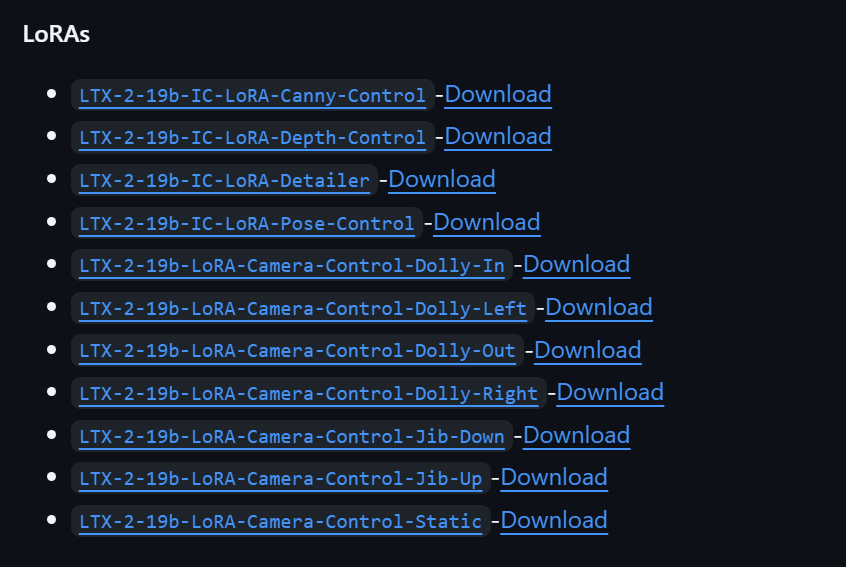
在comfyUI中的模型下载与放置路径表如下:
LTX-2 模型放置位置总表 (ComfyUI)
| 模型类别 | 推荐文件名 (Safetensors) | 放置目录 (以 ComfyUI 根目录为例) |
|---|---|---|
| 基础模型 (Checkpoints) | ltx-2-19b-dev-fp8.safetensors | models/checkpoints/ |
| 极速版模型 (Distilled) | ltx-2-19b-distilled-fp8.safetensors | models/checkpoints/ |
| 空间放大器 (Spatial) | ltx-2-spatial-upscaler-x2-1.0.safetensors | models/upscale_models/ |
| 时间放大器 (Temporal) | ltx-2-temporal-upscaler-x2-1.0.safetensors | models/upscale_models/ |
| 文本编码器 (Gemma 3) | gemma-3-12b-it-fp8.safetensors (及其 JSON 配置) | models/text_encoders/gemma3/ |
| 控制模型 (IC-LoRA) | ltx-2-19b-ic-lora-depth-control.safetensors | models/loras/ |
| 相机控制 (LoRA) | ltx-2-19b-lora-camera-control-dolly-in.safetensors | models/loras/ |
核心细节补充与注意事项
1. 文本编码器 (Gemma 3) 的特殊处理
LTX-2 使用了 Google 的 Gemma 3 作为文本编码器,这与以往的 T5 或 CLIP 不同。
- 放置要求: 建议在 models/text_encoders/ 下新建一个名为 gemma3 的文件夹。
- 文件完整性: 除了 .safetensors 模型文件,通常还需要从 Hugging Face 下载该模型的 config.json 等配置文件放在同一目录下,否则节点可能无法正确识别。
2. 8G/12G 显存环境的型号选择
- 强烈建议使用 fp8 或 nvfp4 版本:避免下载原版 bf16 模型(通常大于 35GB),否则 12G 显存会直接溢出。
- 蒸馏版 (Distilled):如果你追求速度,请确保下载带有 distilled 字样的模型,它配合特殊的采样器只需 8 步即可出图。
3. 放大器模型 (Upscalers)
LTX-2 的原生 4K 输出依赖于“两阶段生成”。
- 第一阶段生成低分辨率潜空间视频。
- 第二阶段调用 Spatial Upscaler 提升空间分辨率,调用 Temporal Upscaler 提升帧率至 50 FPS。
- 注意: 这两个模型务必放入 models/upscale_models/,否则在运行双阶段工作流时会报错。
| 功能特性 | 低显存 (8G-12G) | 高显存 (24G+) |
|---|---|---|
| 推荐模型 | FP8 / NVFP4 量化版 | BF16 全精度版 |
| 分辨率 | 540p / 720p (插值后) | 原生 4K (2160p) |
| 视频长度 | 2-5 秒 | 15-20 秒 |
| 文本编码器 | GGUF / 量化版 Gemma 3 | 完整版 Gemma 3 |
| 工作流 | 单阶段 (One-Stage) | 两阶段 (Two-Stages) |
| 采样步数 | 推荐 8 步 (Distilled) | 推荐 20-40 步 (Pro) |
目前,本地运行,相对还是吃力,特别是低配置的,要等社区的GGUF量化模型出来。不过好消息是,有一个出来了:https://huggingface.co/smthem/LTX-2-Test-gguf/tree/main
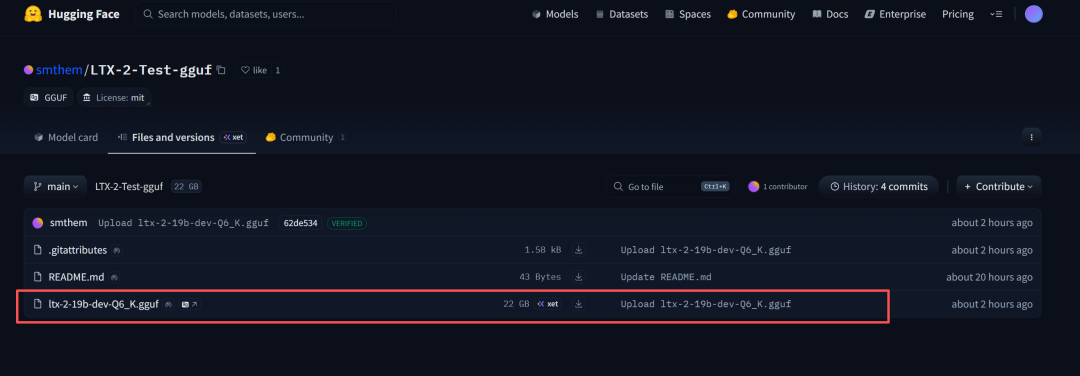
可以尝试将主模型使用GGUF来跑。
在此前,低显存的可以尝试线上跑。
下面是LTX2 文生视频与图生视频工作流体验:
以下是LTX2 文生视频工作流:
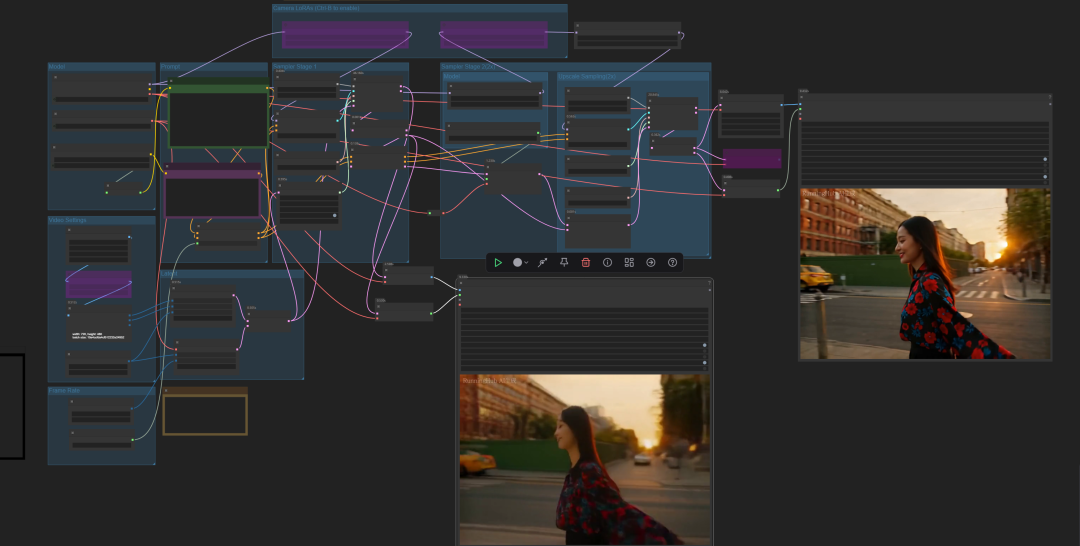
主要模型说明如下:
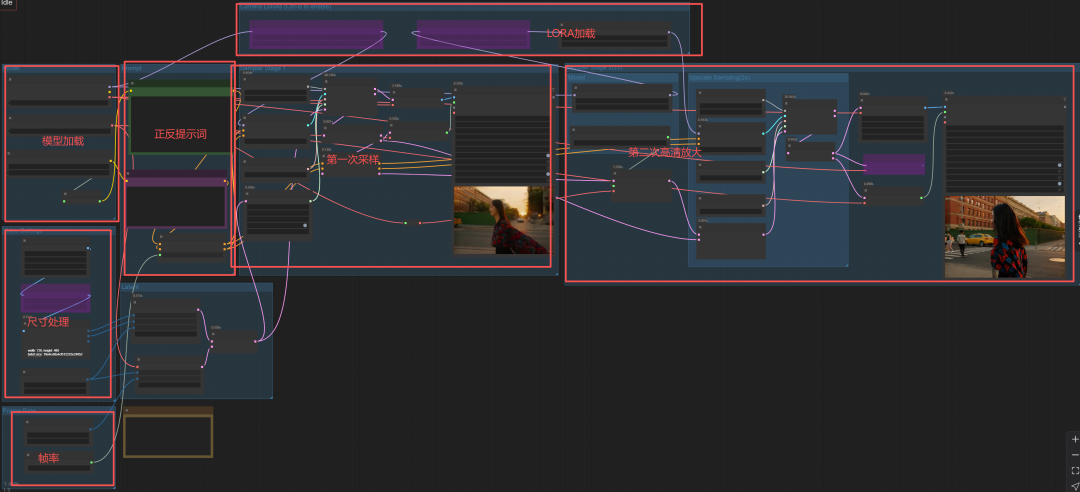
模型加载:
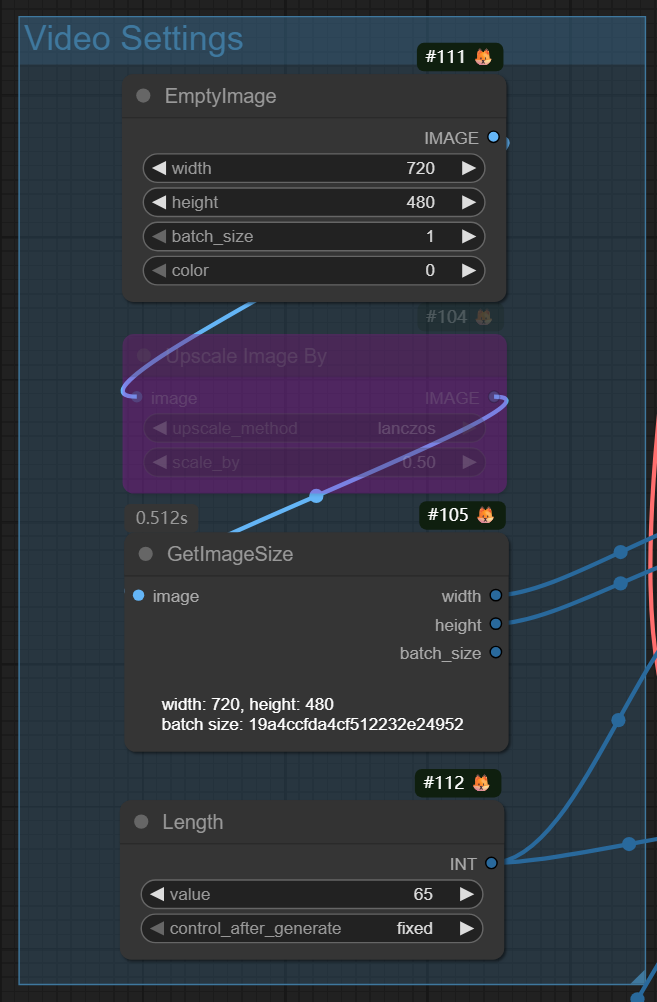
视频尺寸:这里好保守地用720P。
提示词:
因为使用FP8模型,所以20~40步。
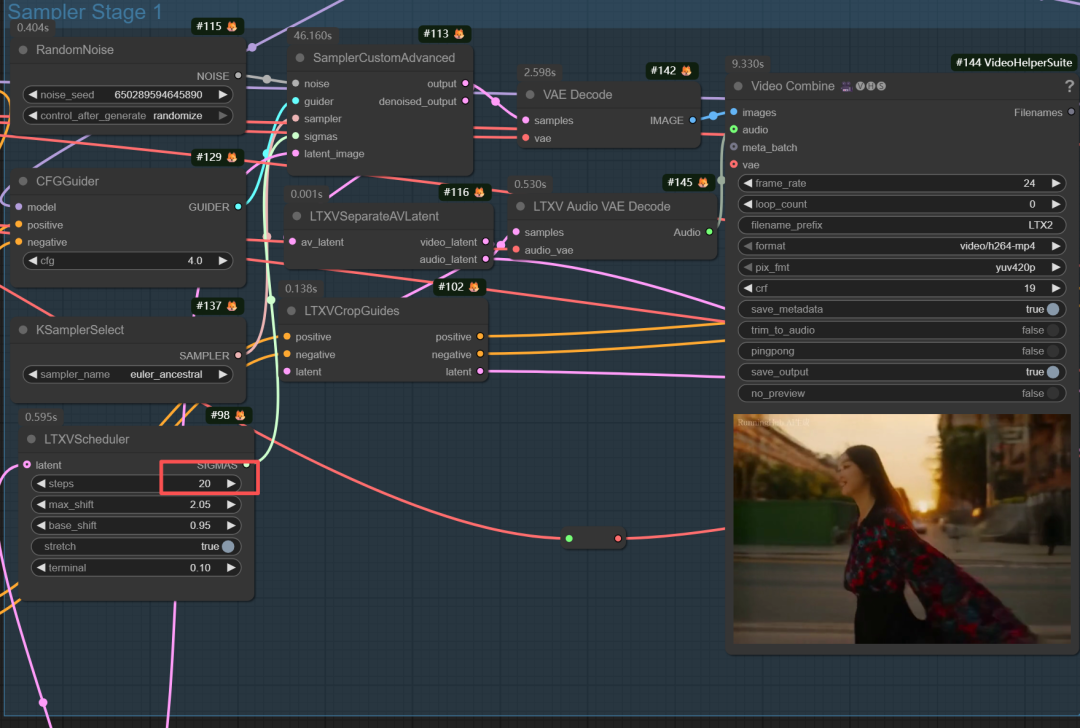
文生视频结果:
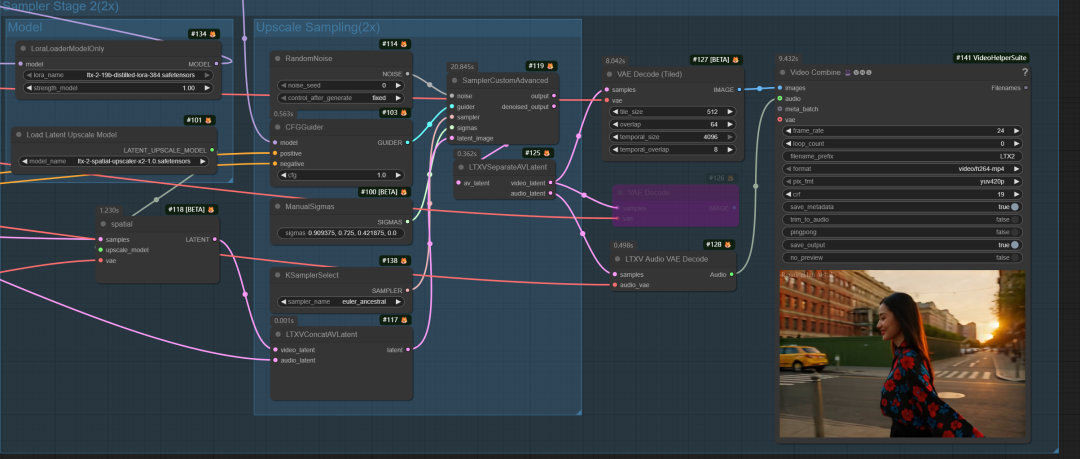
以下是LTX2 图生视频工作流:
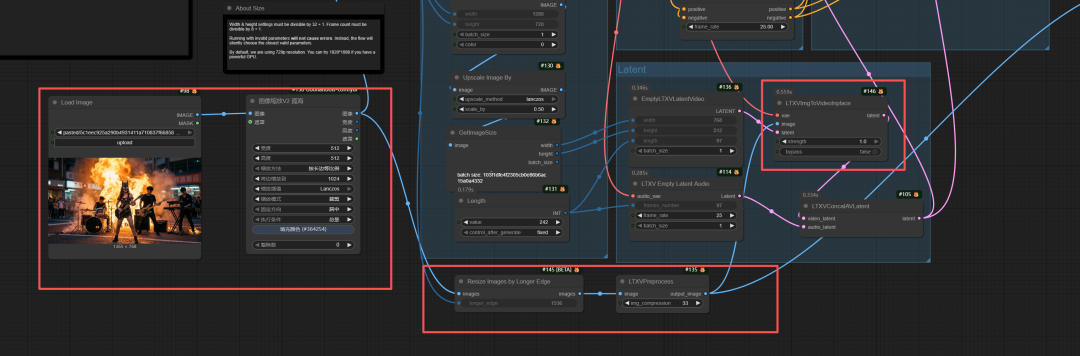
图生视频工作流是在文生视频基础上作一些小小修改,接入图像并进行图像尺寸处理,然后接入LTXVImgToVideoInplace节点中。其它一样。
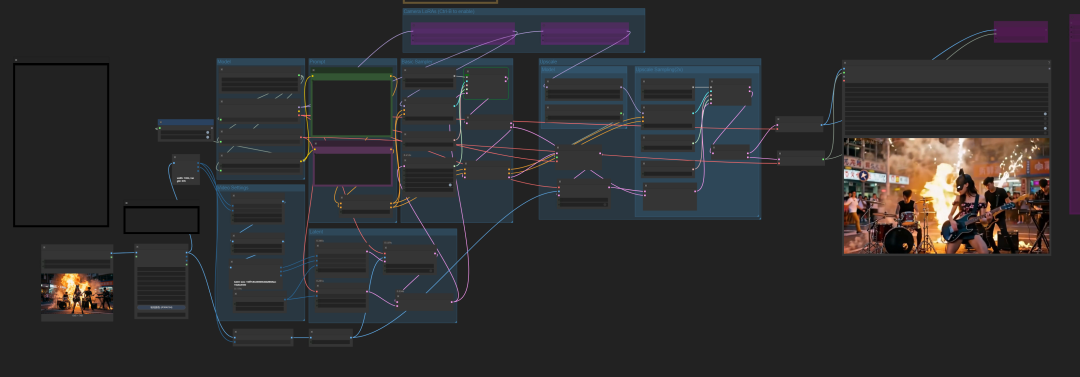
跑出来结果:
换张图和提示词再跑一下:
总结:LTX-2 是目前市场上最强大、最开放的音画生成模型之一。它能生成 4K 画质且原生音频同步和极高的可控性,目前开源界视频生成模型中最亮的仔。现在静等GGUF量化及生态完善。2026年音画同步视频生成模型开卷!
本地算力不够怎么办?
如果本地设备算力不好的小伙伴,推荐使用线上comfyUI来运行体验:runninghub.cn
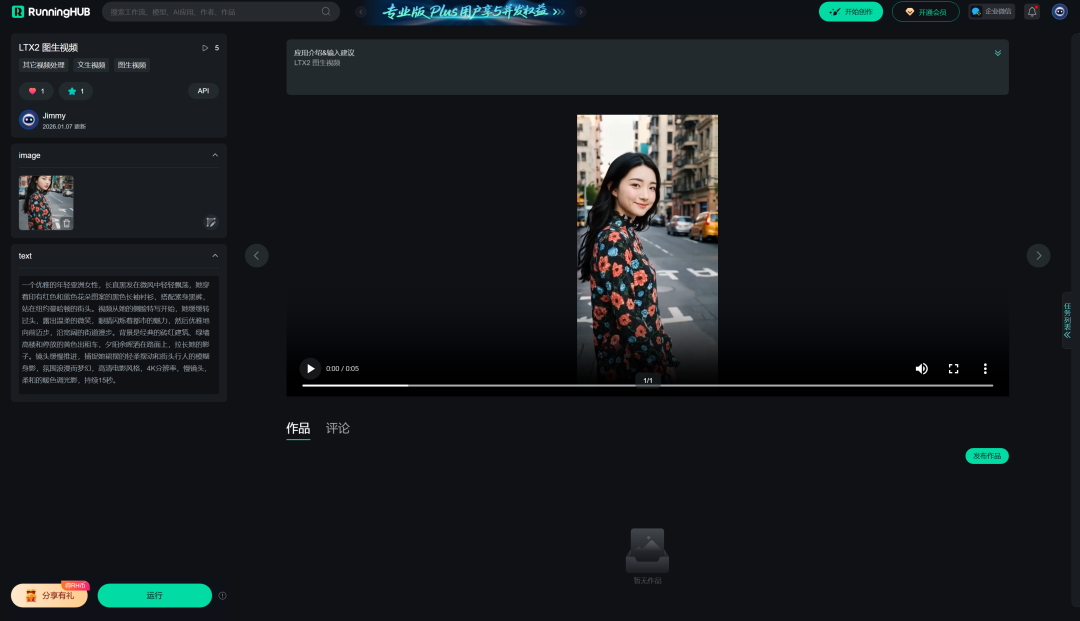
LTX2 图生视频应用体验地址:
https://www.runninghub.cn/ai-detail/2008745289913475074
注册地址:https://www.runninghub.cn/?utm_source=kol01-RH151
通过这个链接第一次注册送1000点,每日登录送100点
最后几句:
如果对你有帮助,请一键三连支持下我,感谢
CloserAI GeminiNode
http://closerai.douyoubuy.cn/2026/01/06/418991/
CloserAI 3D Pose Editor:
http://aigc.douyoubuy.cn/2025/12/03/3448/
closerAI-nanoPrompts:
http://closerai.douyoubuy.cn/2025/11/24/3396/
closerAI 分镜设计 软件(exe)本地运行版
http://aigc.douyoubuy.cn/2025/11/22/3350/
以下是closerAIwater节点:
http://aigc.douyoubuy.cn/2025/10/22/3121/
分镜分词器节点:
http://aigc.douyoubuy.cn/2025/10/11/3080/
json结构化提示词
http://aigc.douyoubuy.cn/2025/11/05/3242/
以上是closerAI团队制作的stable diffusion comfyUI
closerAI qwenEdit2511服装穿搭拆解工作流0106和closerAI NanoBananaPro(gemininodes)服装穿搭拆解工作流的介绍,当然,也可以在我们closerAI会员站上获取(查看原文)。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。
>/ 作者:JimmyMo
更多AI前沿科技资讯,请关注我们:

主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网

评论(0)