


更多AI前沿科技资讯,请关注我们:
【closerAI ComfyUI】flux kontext dev提示词指南,同时探索controlnet控制一起生成的可行性
大家好,我是Jimmy。Ai图像编辑开源界的王,flux kontext dev昨天开源:
【closerAI ComfyUI】重磅来袭!flux kontext dev开源!图像编辑全民普及化!GGUF版本4G可玩!冲
很多人进行体验,反映模型不能很好理解文本,不遵循文本内容自由发挥。生成的结果跟我们想要的有很大偏差。其实,黑森林官方早给就出答案。建议大家在玩之前,先看看官方文档的提示词指南:
https://docs.bfl.ai/kontext/kontext_image_editing
我通过AI编程,给大家整理出一个表格,直观地看每个任务的提示词应该怎么写:

网页版的展示我形成了,大家可以上去看,电脑浏览器打开:http://aigc.douyoubuy.cn/2025/06/28/2037/
大家根据指令模板,照抄就是。
但是~
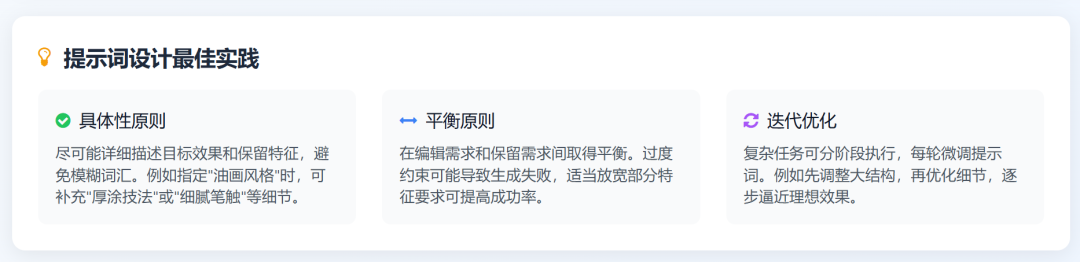
模板是死的,我的理解就是描述得越详细,它就越遵循你的指令。也就是要把话讲清楚。
单图指令控制生图,这里不多说了,按上面提示词模板套用就是。重点是想分享一些多图参考的内容。
拿这两张图为例:
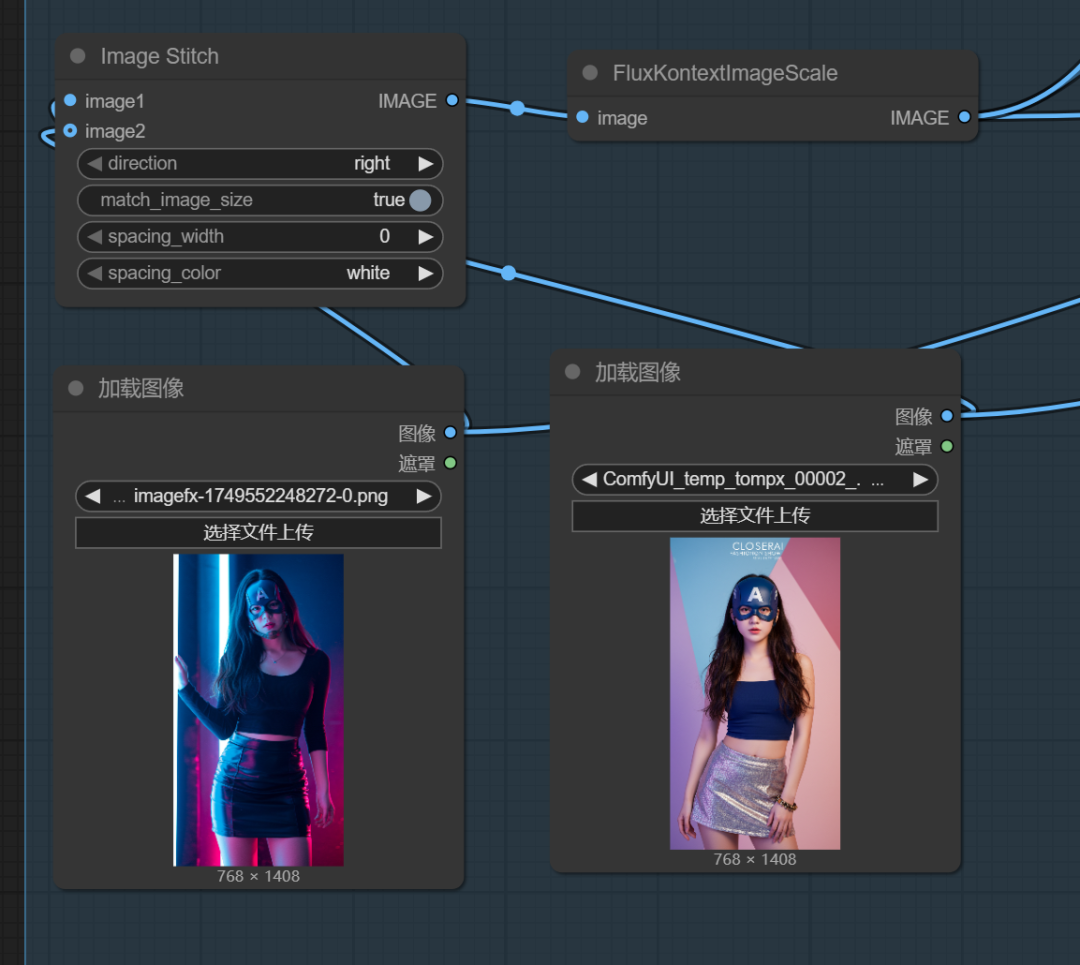
首先,我提示词这样写:
两个女人一起在赛博朋克的城市中,两个人在打架,镜头应该为远景视角且能看到两个角色全身,保持人物外貌、装饰特征不变

我这里为什么能生成两个女人在打架且全身?首先,我做了两件事。
1、将合并后的图像的尺寸形成潜空间尺寸加入采样
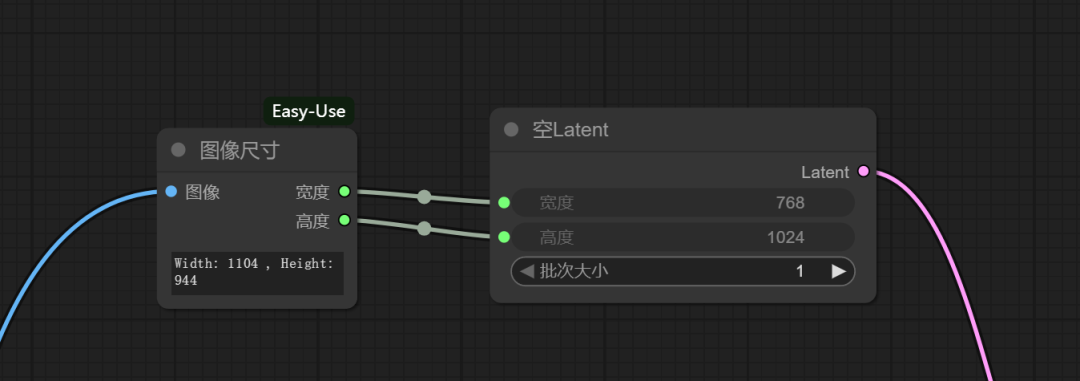
尺寸要控制吧。你想生成怎么的尺寸,模型就在这个尺寸内发挥。
2、描述清楚:
两个女人一起在赛博朋克的城市中,两个人在打架,镜头应该为远景视角且能看到两个角色全身,保持人物外貌、装饰特征不变
我是双图参考嘛,两个女人模型就知道了是哪两个女人了。“在赛博朋克的城市”画风也描述清楚了,两个人在干嘛?在“打架”,如何全身展示?“镜头应该为远景视角且能看到两个角色全身”,最后要加上:”保持人物外貌、装饰特征不变“,如果不加,模型将自由发挥,在一定概率上会改变人物及其特征。
如果你不写清楚,描述不足,其它内容kontext模型将自由发挥
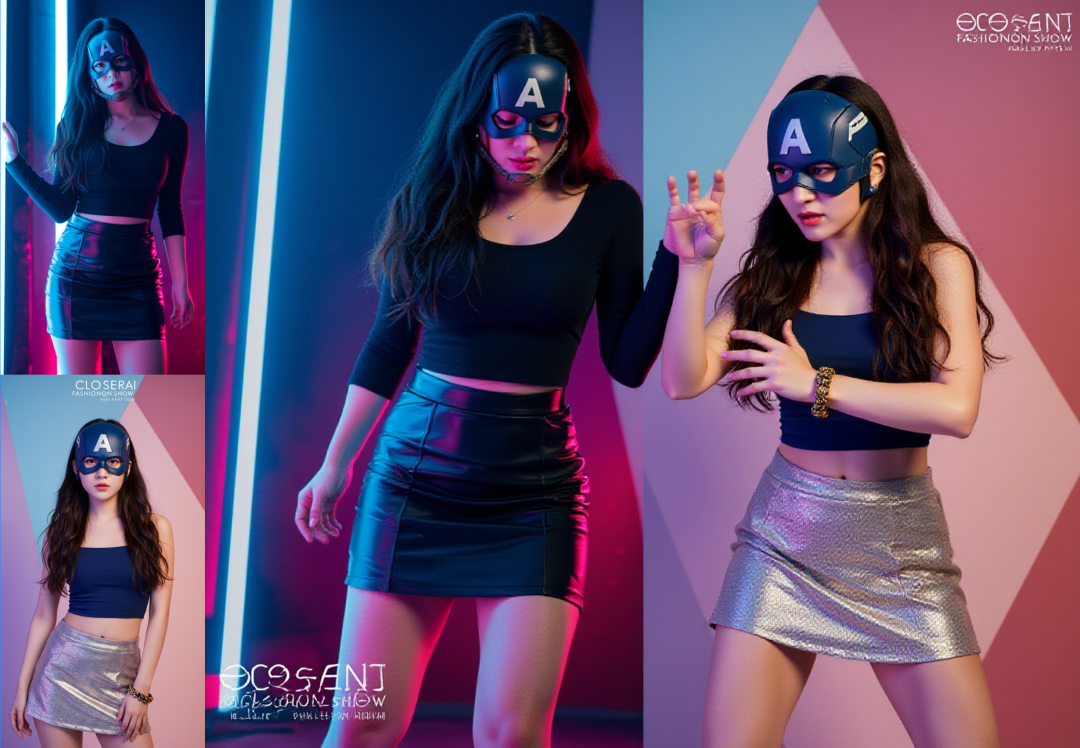
就好比全身照的效果,你如果不描述到提示词,是很难抽卡到全身的!
我这次换了背景。
两个女人一起在银色短裙女人的几何背景中出现,两个人正在打架,镜头应该为远景视角且能看到两个角色全身包括脚。保持人物外貌、装饰特征不变。
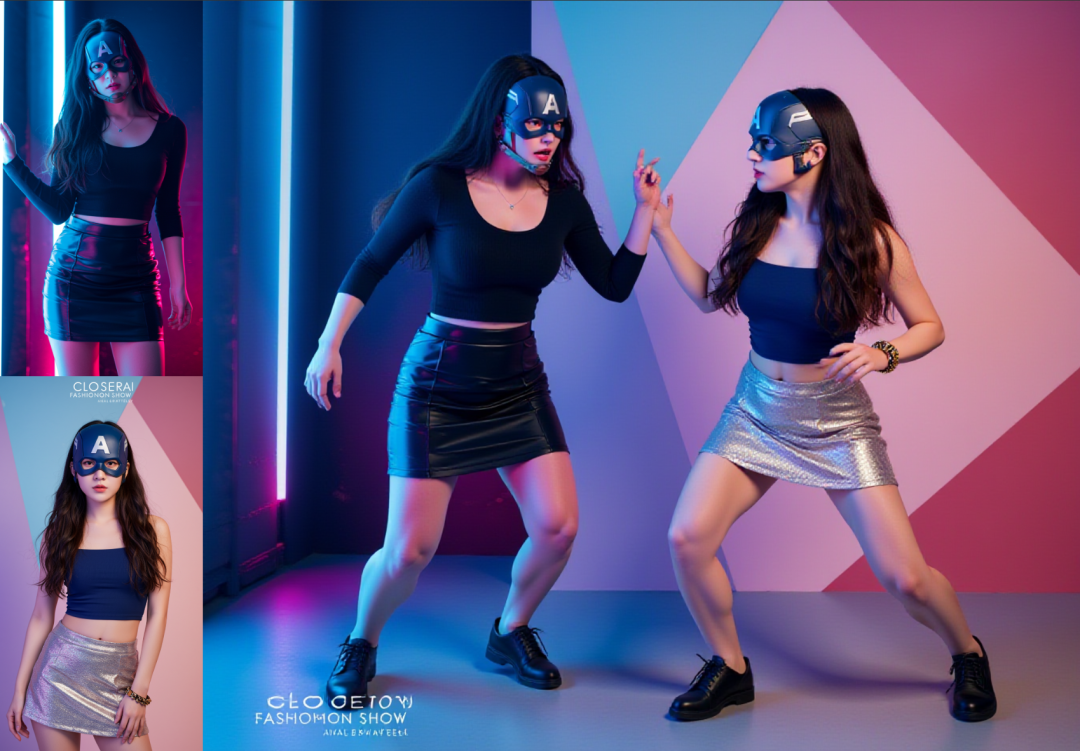
生图是同样遵循我们指令,因为我描述清楚在哪个美女的背景下。
两个女人一起在银色短裙女人的几何背景中出现,两个人正在打架,镜头应该为远景视角且能看到两个角色全身包括脚。顶部有射灯,明显的光影效果,明暗分明,保持人物外貌、装饰特征不变

从上图你会看到,人物打架的动作好搞笑,随机生成的动作。因为我们没有指令去控制模型告诉它,两个角色是如何打架的嘛,所以它会自由发挥。
这个时候,为了能描述清楚,我借助LLM来尝试。
找一张打架的图像,让多模态能力的LLM来理解并描述:

尝试修改提示词生图:将上面得到的提示词修改成两个女人的特征描述。
两个女人一起在银色短裙女人的几何背景中出现,
两个人正在打架,
黑裙美女左腿用力蹬地,肌肉紧绷,呈现出蓄势待发的状态,右腿向后弯曲抬起,膝盖微屈,显示出他正快速向前突进。他的身体大幅度前倾,将重心置于前方,展现出勇往直前的气势。
而银裙美女则呈现出攻击姿态,右腿稳稳支撑在地面,承受着身体的力量,左腿弯曲抬起,呈现出一种灵活且随时可移动的状态。他的上半身大幅度扭转,展现出强大的力量感和灵活性,右臂向前伸出。
镜头应该为远景视角且能看到两个角色全身包括脚。
保持人物外貌、装饰特征不变
以下生成效果:
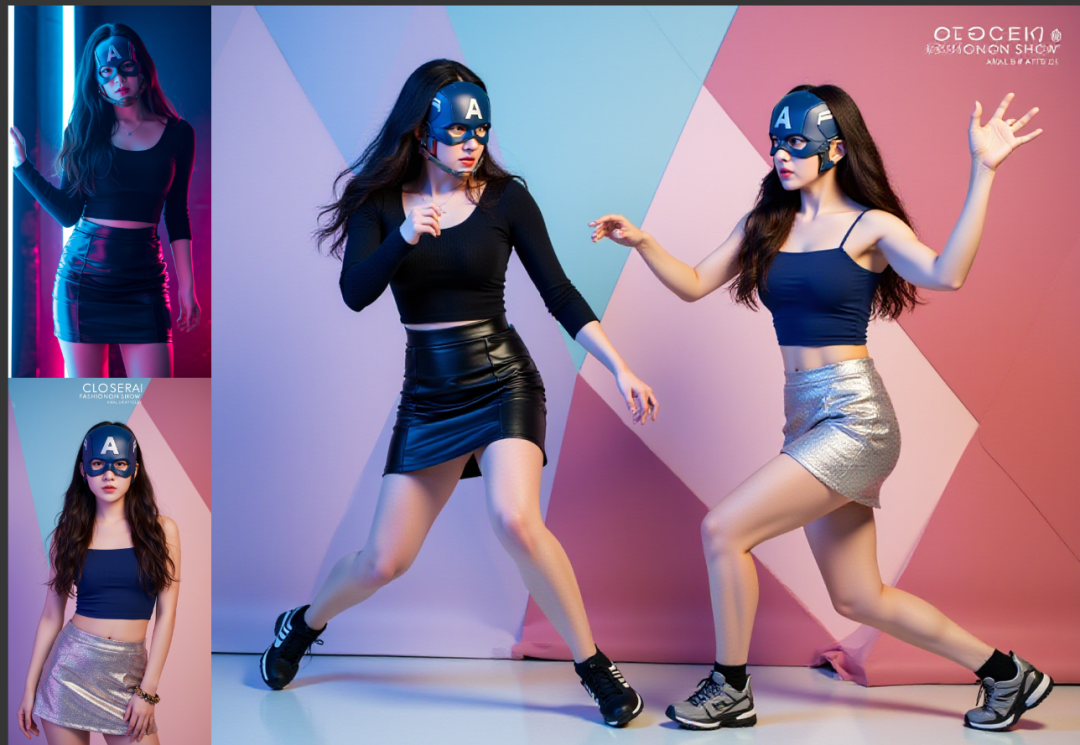

我们能看到,通过提示词的中动作的描述,它能呈现出稍微合理的打架动作。但,这对于我们讲是不够的,正如当时stablediffusion的文生图SD1.5刚出的时候,文生图是很难满足我们的生图需求,我们要精准控制,那个时候,controlnet出现。姿势参考来控制。
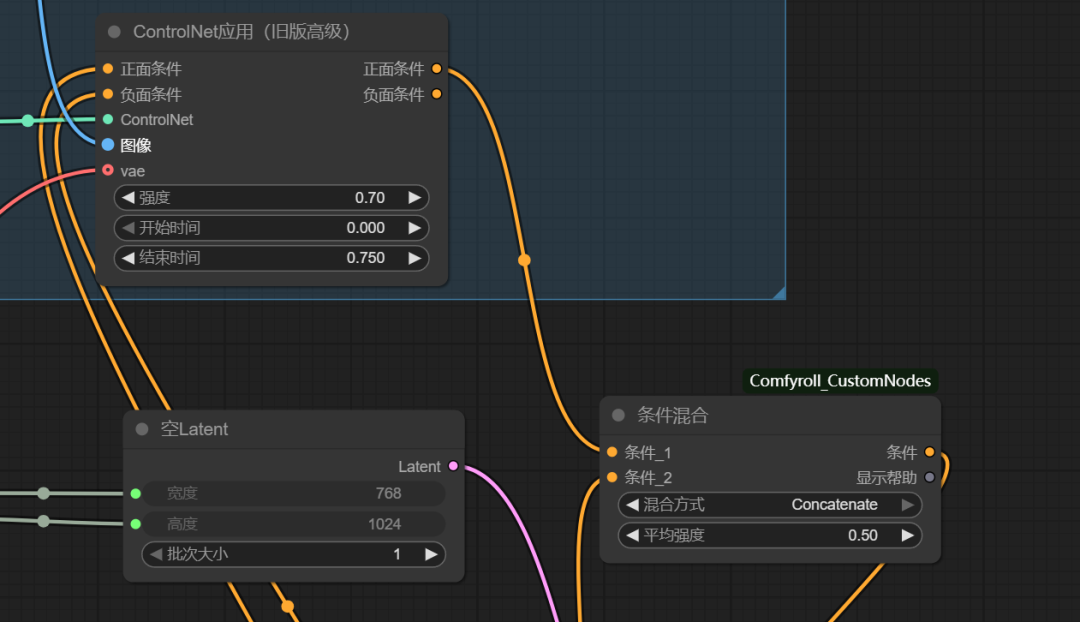
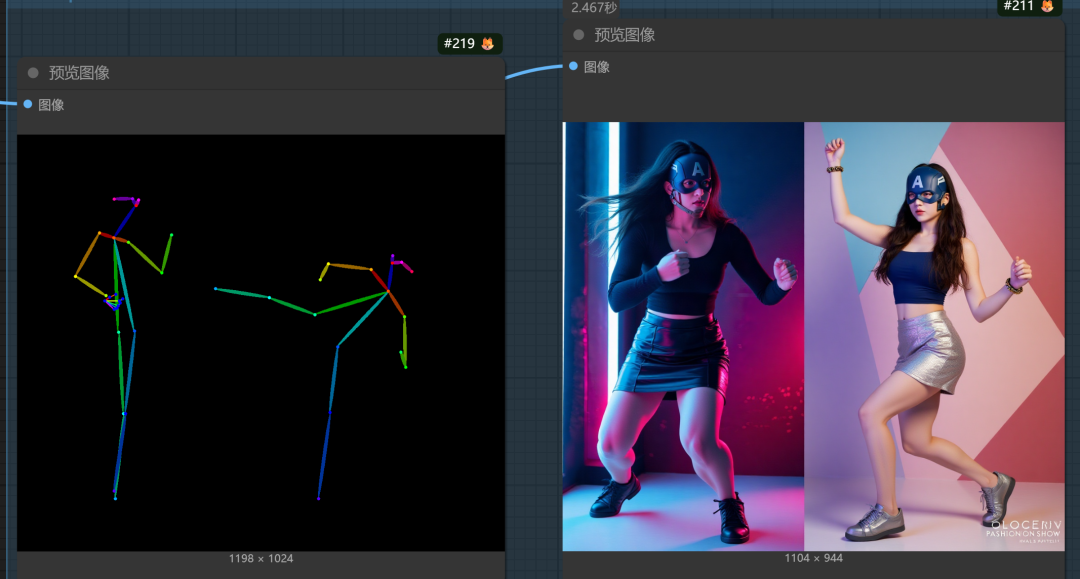
所以,我们索性,形成姿势参考来控制生成。我们观察提示词它是通过条件加入采样器的,所以,我们可以使用controlnet来尝试形成合并条件,一起加入采样器,用姿势控制+提示词描述来尝试精准控图。
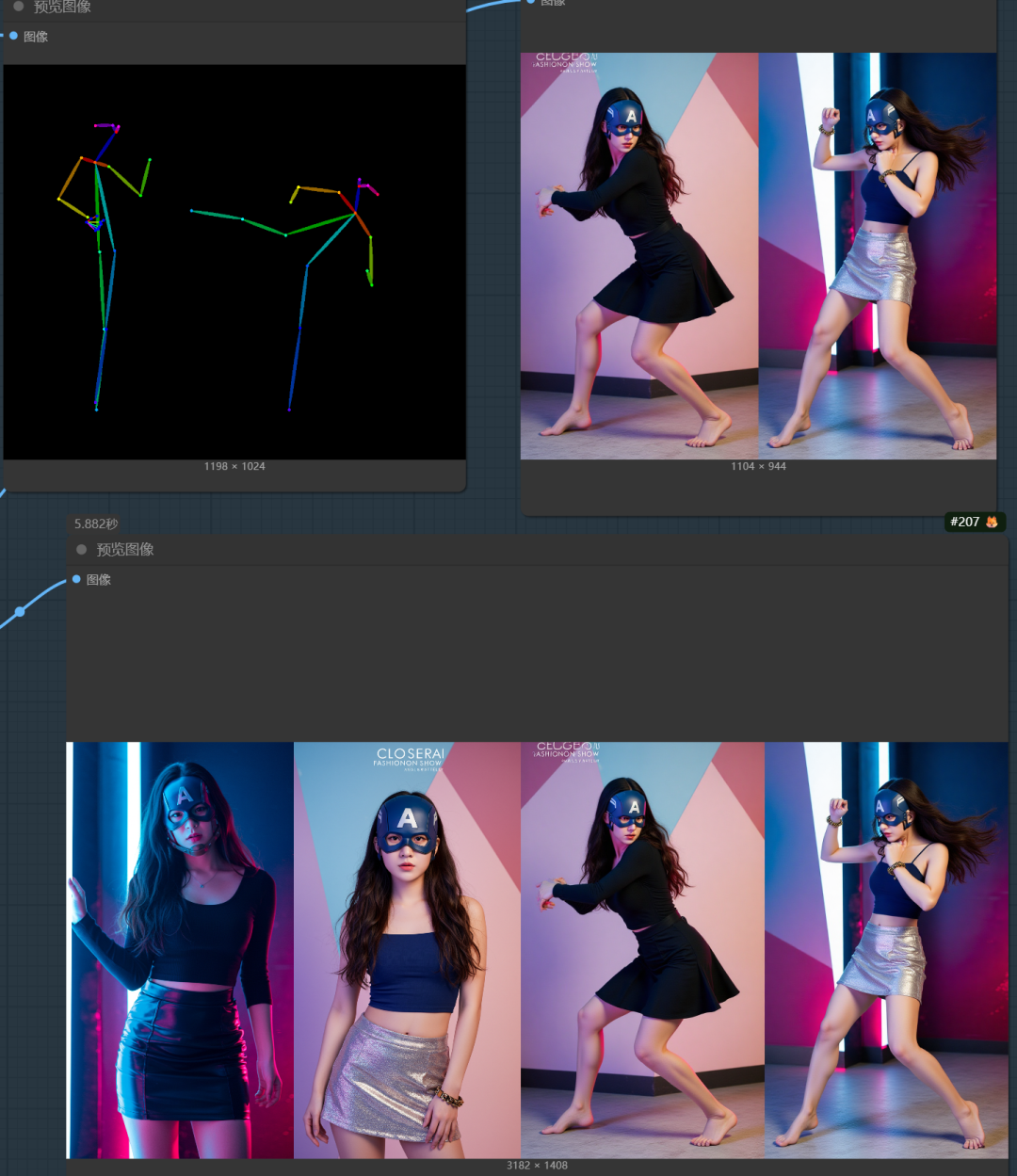
我们这样接入姿势控制:
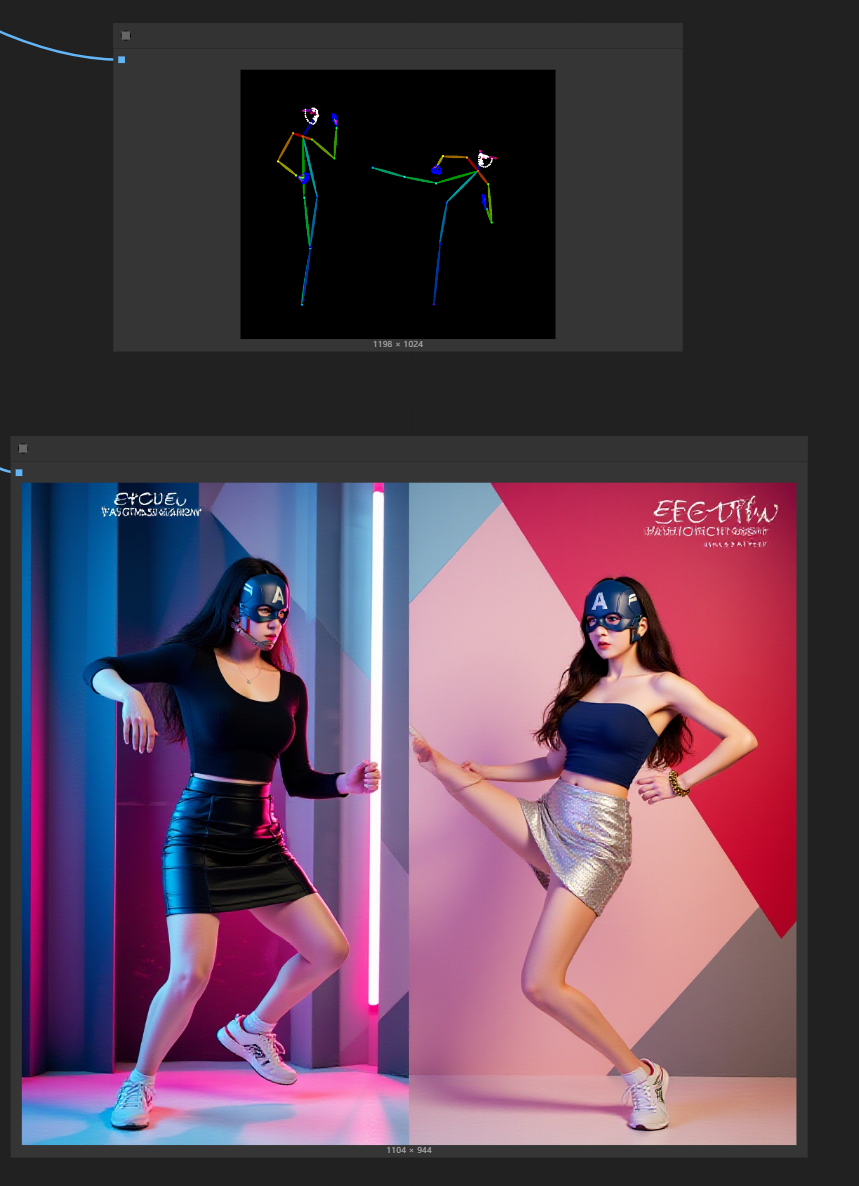
尝试后的生图结果。
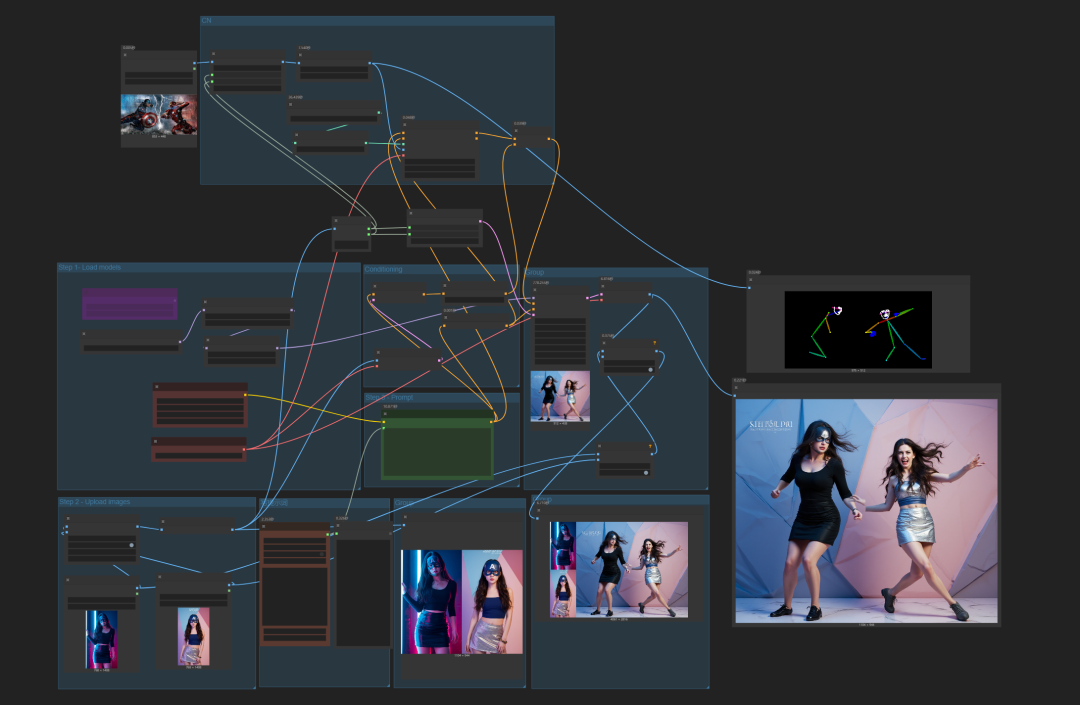
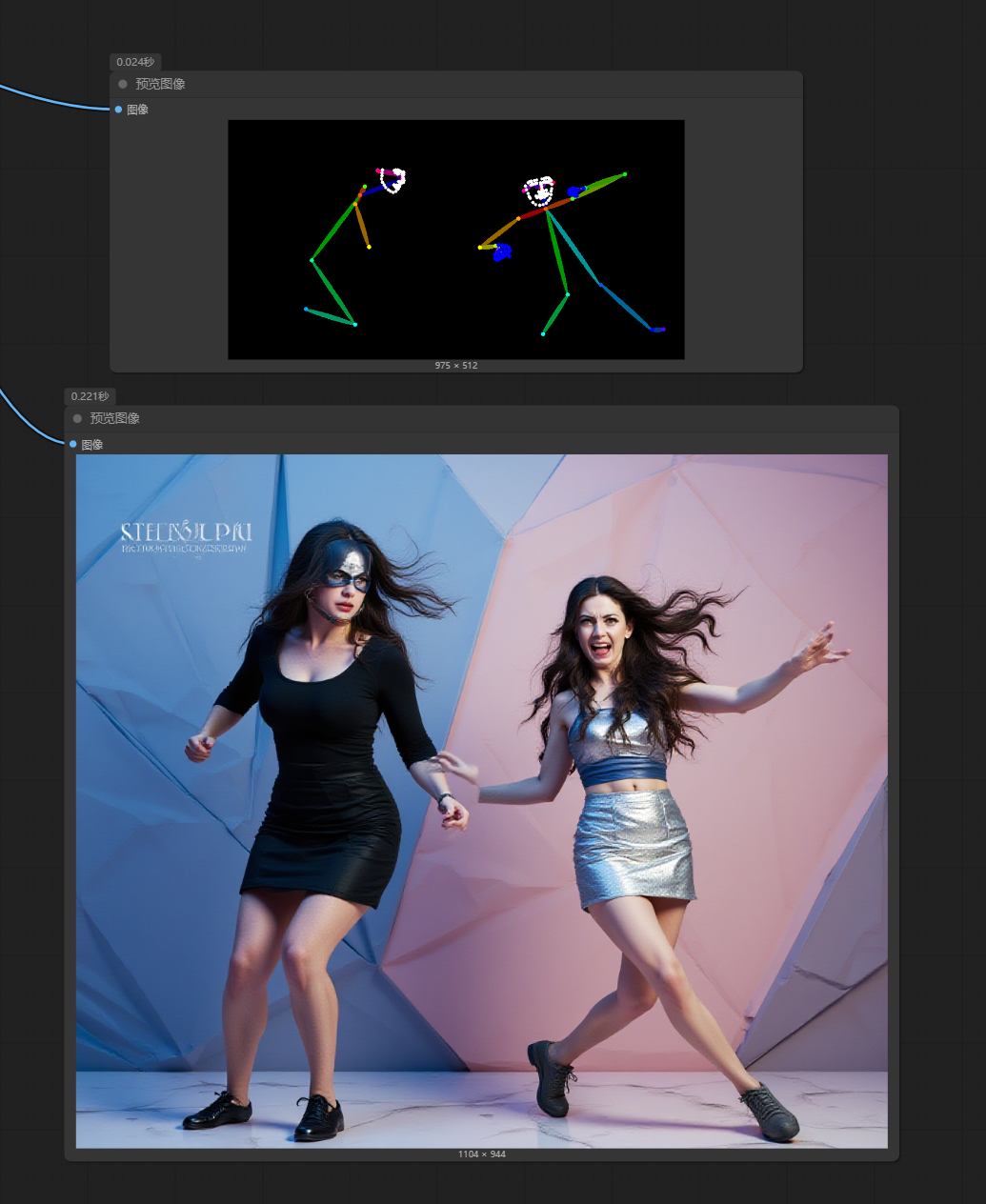

当然,第一次生图,我没有控制参考图尺寸,但我们从结果来看,我们的想法验证是成功的,它能通过加入姿势控制条件与kontext一起生图。
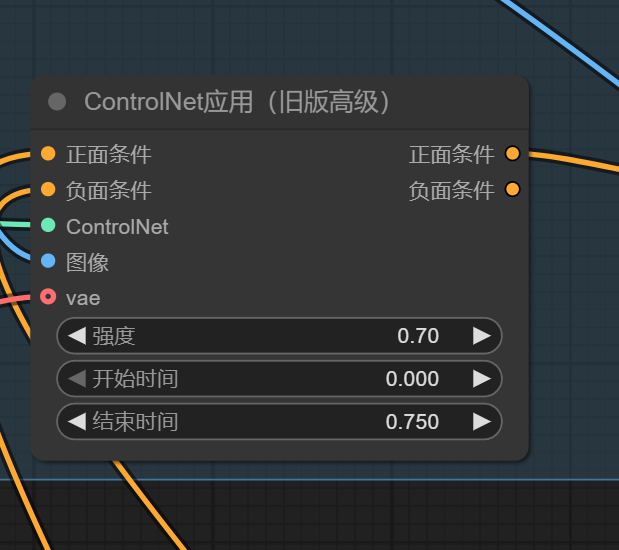
只不过我这张参考图,姿势不够明了,但我们能看出它是遵循姿势控制来生图,但在人物控制中差了点,我猜应该是控制强度的问题,强度和开始结束时间调小一点,如下图示,
我同时再优化下传入的图像姿势尺寸跟我们生图尺寸一样,再试下。
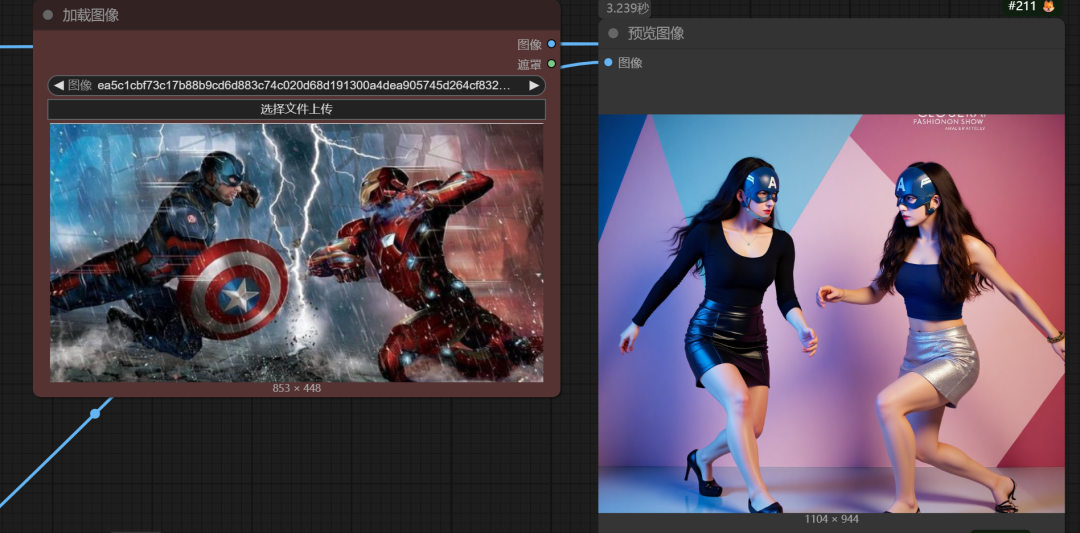
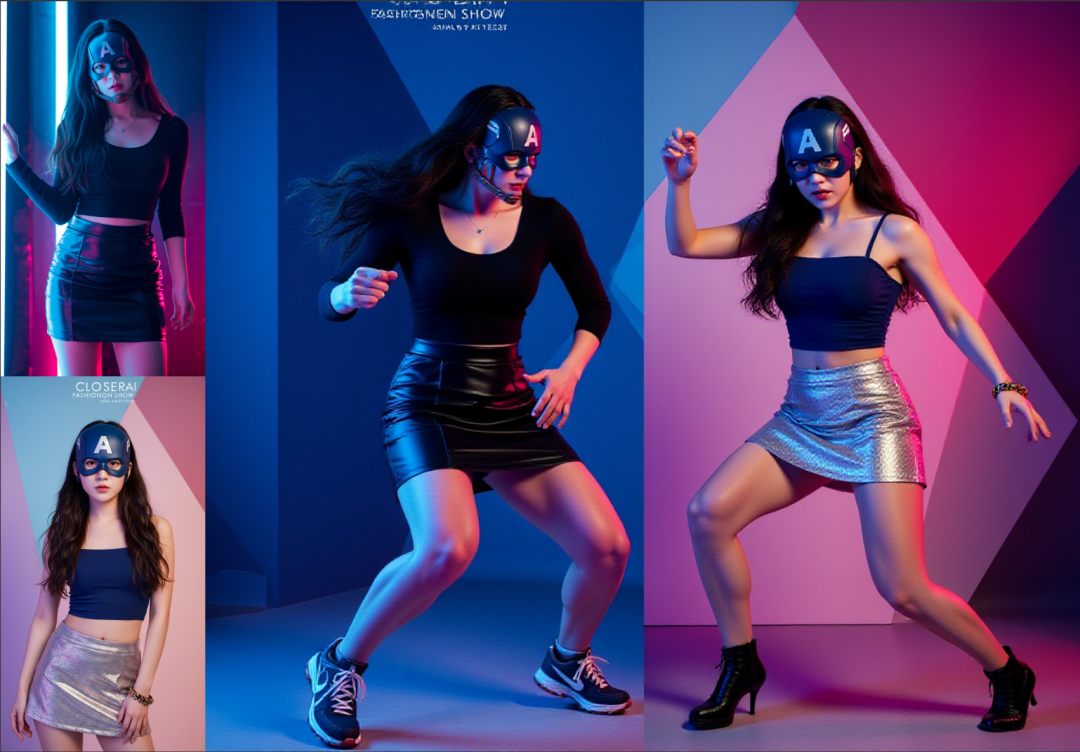
有点那个意思了吧。
这里主要是姿势参考图不够好,我觉得能更好的还原,我再尝试下。
找一张姿势明显的图:
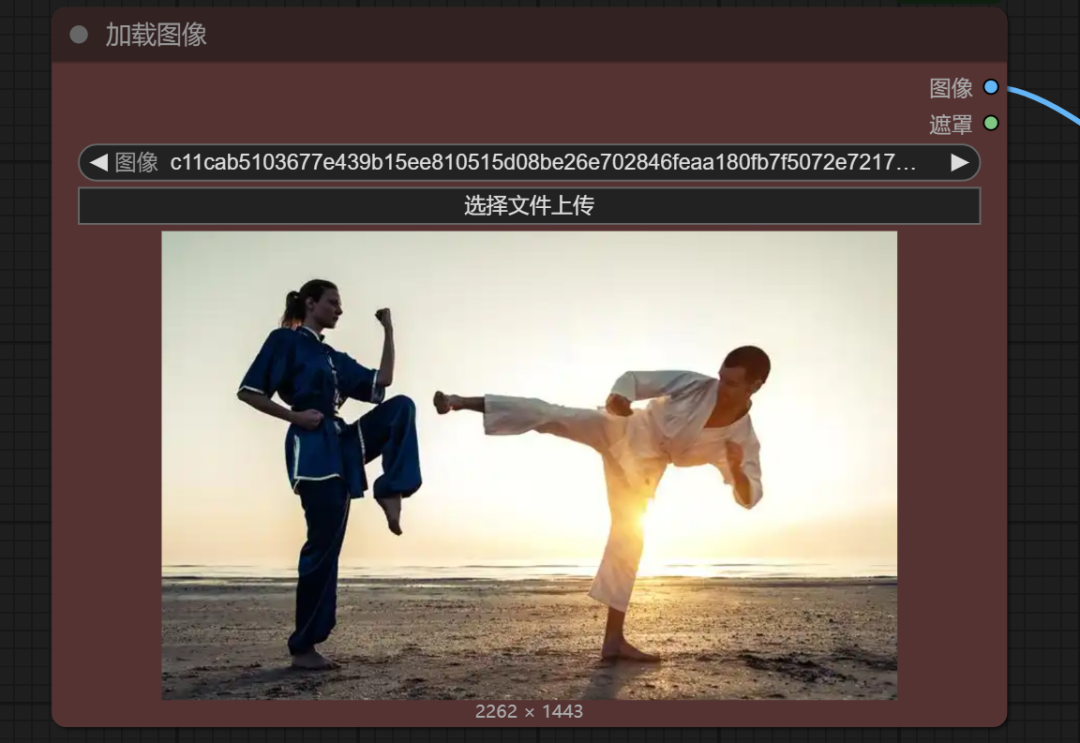
同样LLM描述详细动作:
左侧身着黑裙美女,呈现出战斗准备姿态。她左腿稳稳站立于地面,支撑身体重心,右腿屈膝上抬,脚悬于半空,膝盖朝向身体侧前方,蓄势待发。她右手握拳置于腰间,左手握拳高举至肩部侧上方,拳心向内,目光专注地看向对手,透着一股坚定与警觉 。
右侧银裙美女,正施展一个高踢动作。他左腿直立于地,脚尖朝前,稳稳支撑身体;右腿用力上抬,伸直且与地面平行,脚尖绷直,力量感十足。他的右手握拳收于腰间,左手握拳抬起,小臂与大臂呈一定角度,置于胸前,上半身微微侧倾,展现出动作的协调性与攻击性,阳光洒在他身上,勾勒出清晰的轮廓。
以下是尝试了不同条件强度参数跑。
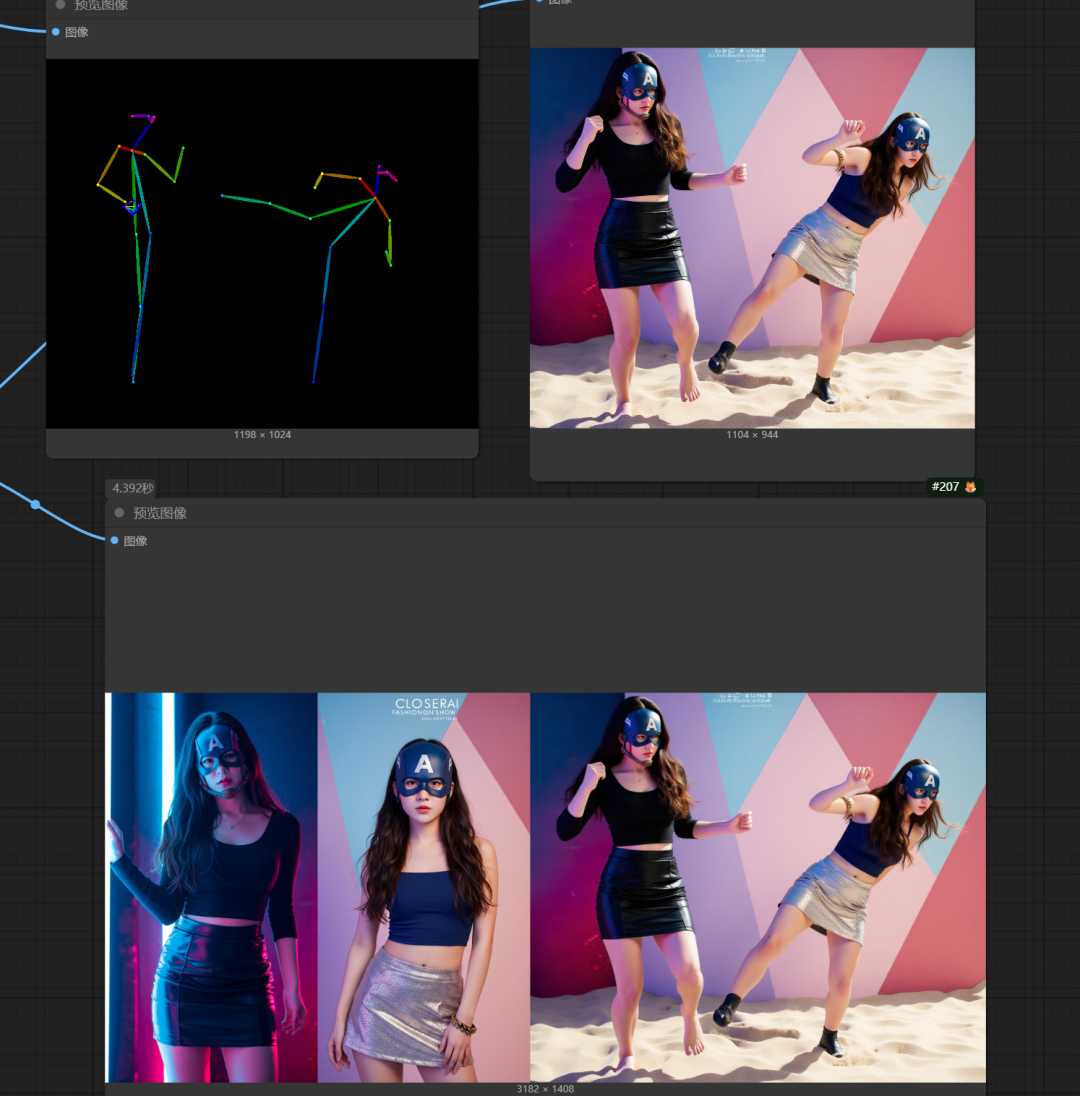
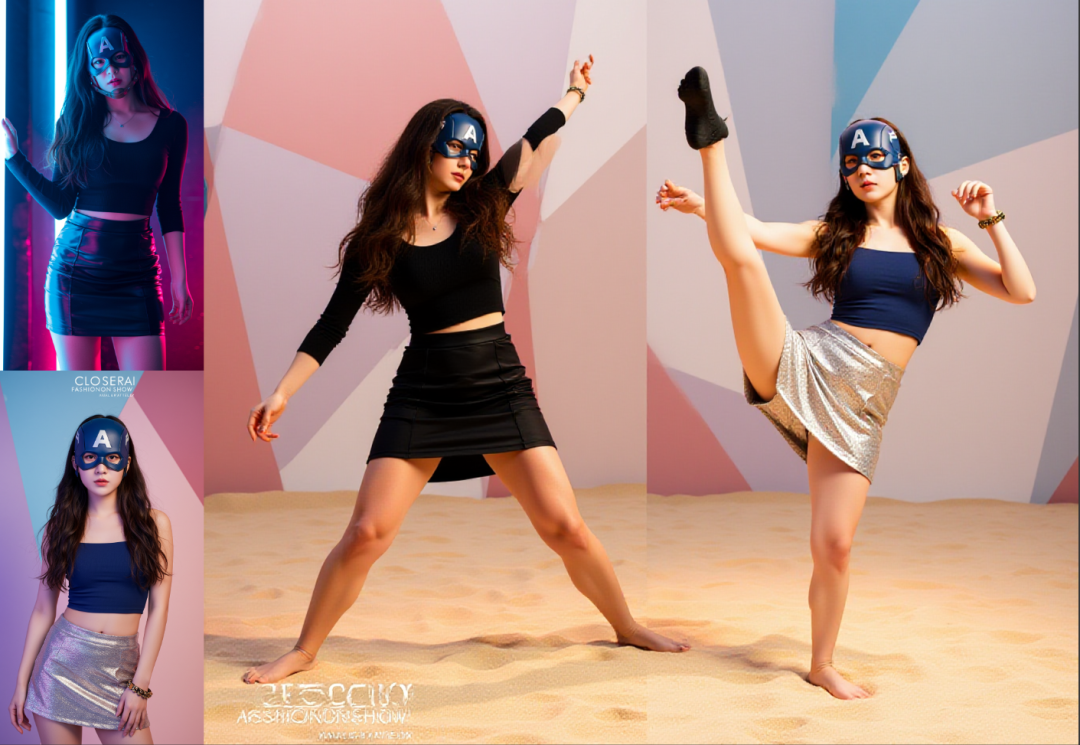
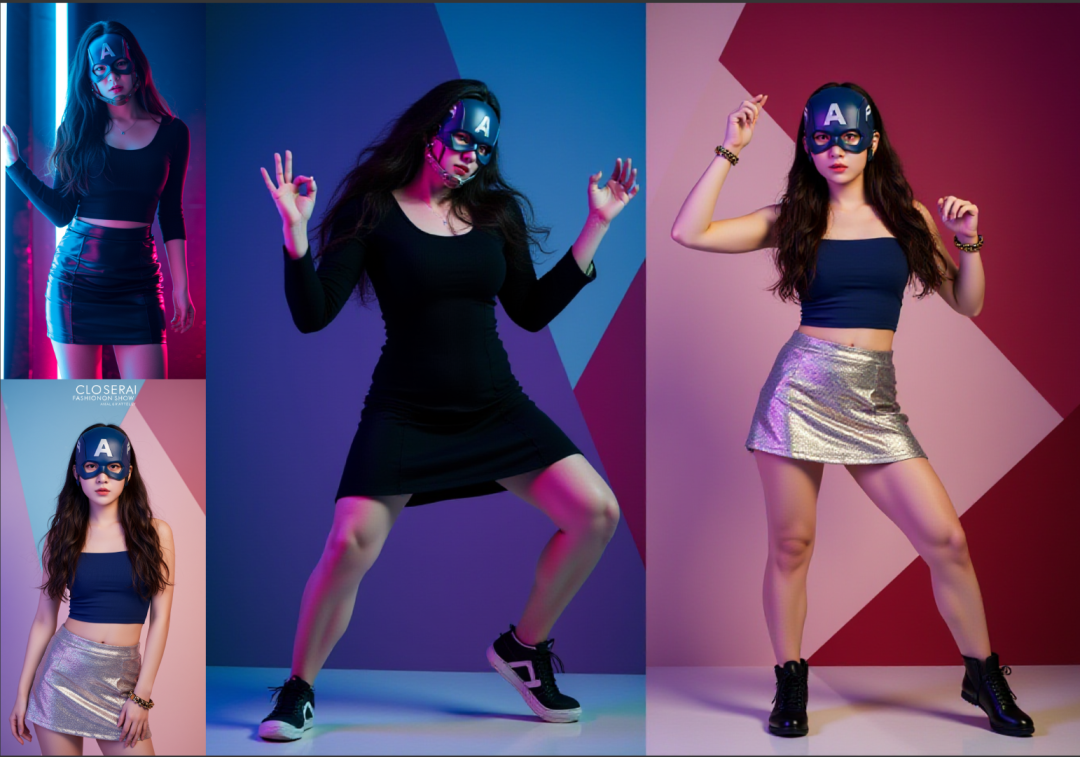

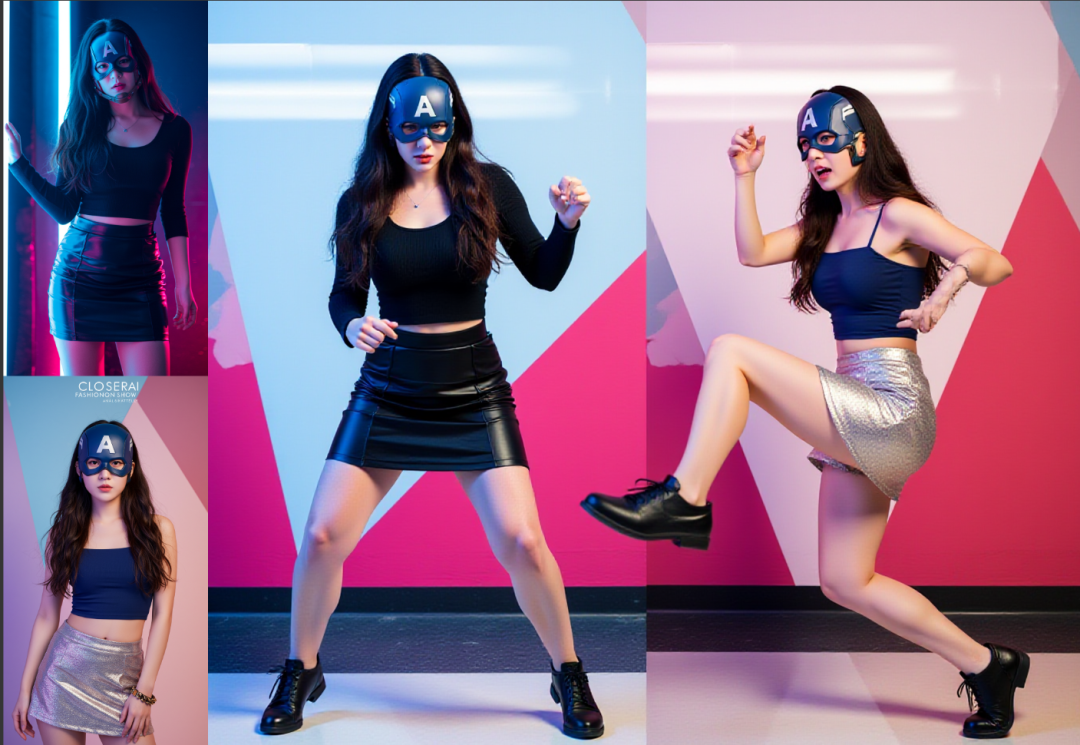
哈哈。我笑死了。
重新优化了一下工作流中条件的链接。
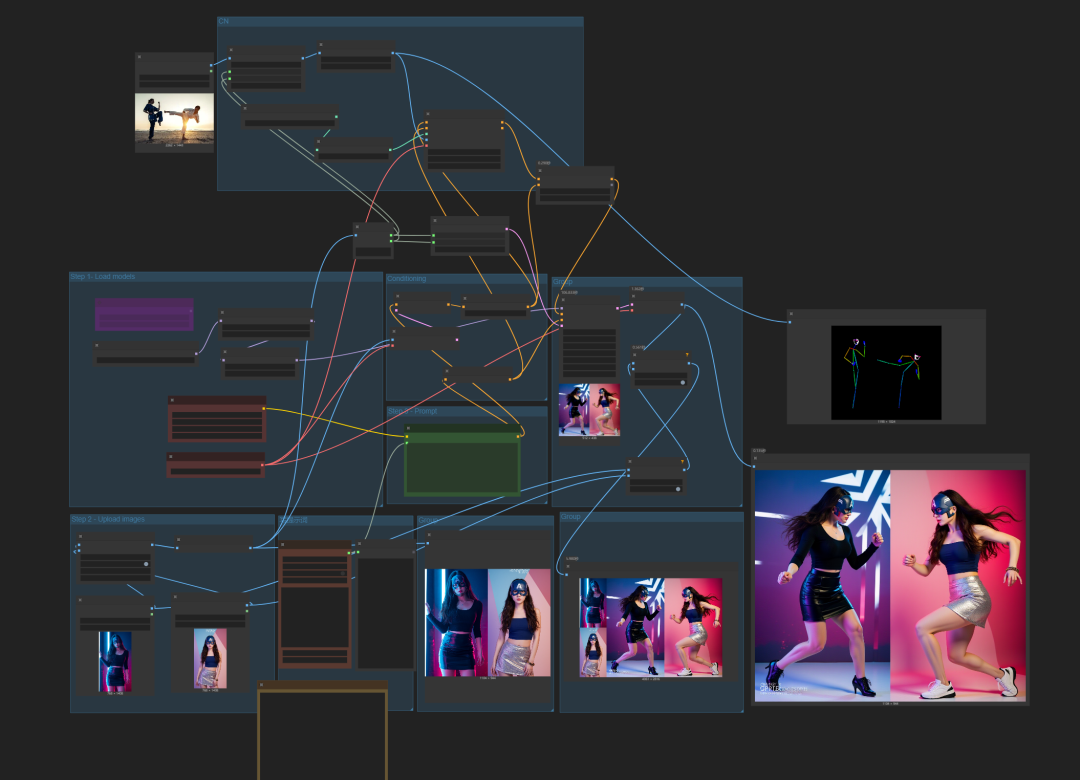
这个是目前感觉最优的,既能提示词控制,也能姿势控制,条件平均强度,同时保持出图质量。
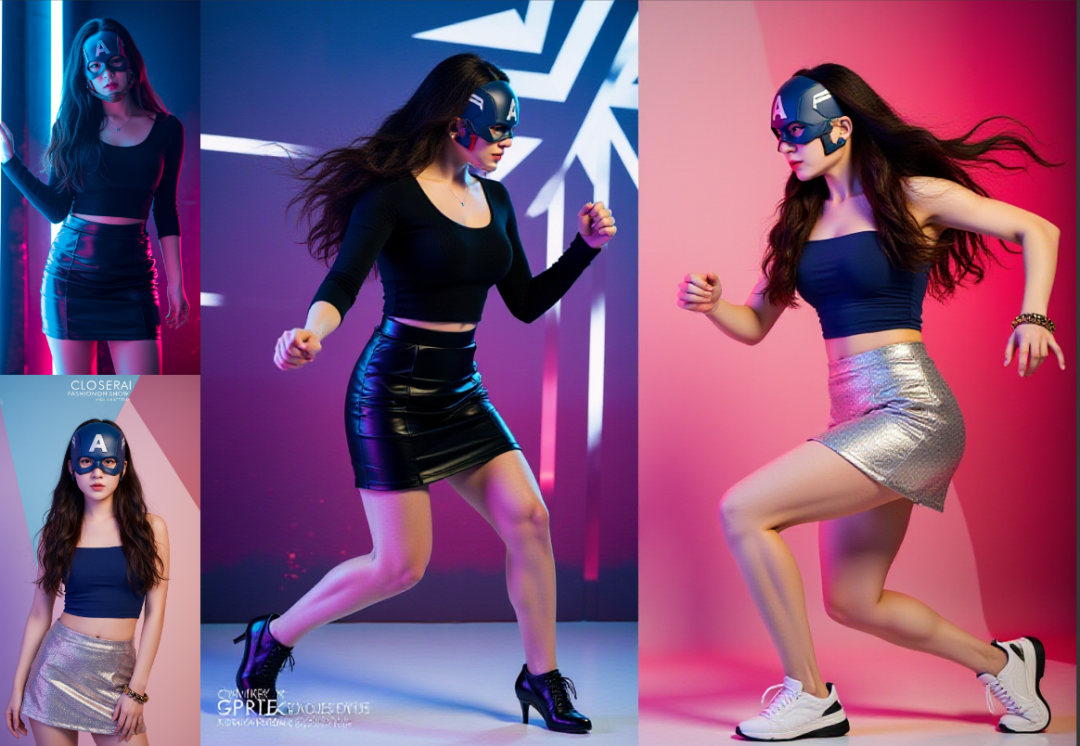

要完全一致的姿势,目前是有点难了。
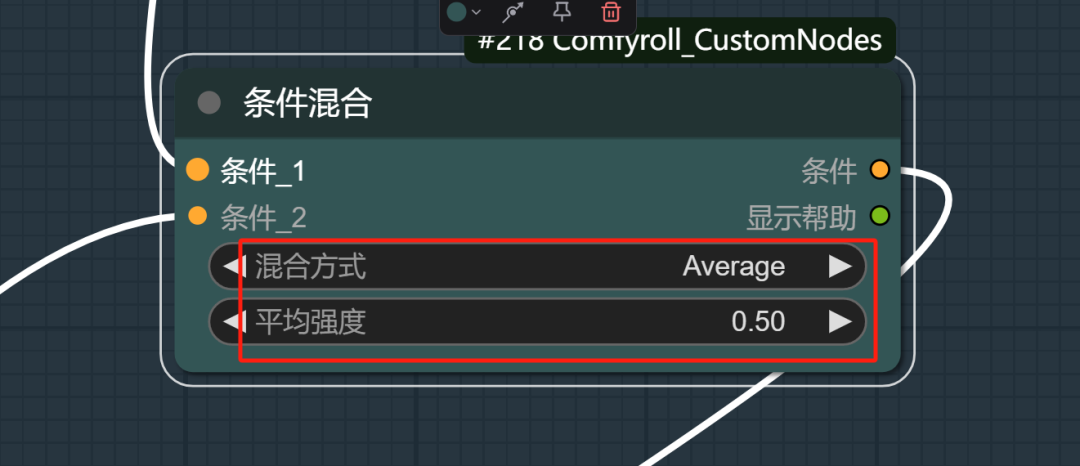
难度主要是这两个值了。变化多端。
本地算力不够怎么办?
如果本地设备算力不好的小伙伴,推荐使用线上comfyUI来运行体验:runninghub.cn
Flux Kontext Dev动嘴P图流体验地址:
https://www.runninghub.cn/ai-detail/1938445554957639681
注册地址:https://www.runninghub.cn/?utm_source=kol01-RH151
通过这个链接第一次注册送1000点,每日登录送100点
最后几句:
提示词详细描述就能很好的应用kontext,还有很多能探索,但我希望nuncahku快点支持!
以上是closerAI团队制作的stable diffusion comfyUI closerAI开发的closerAI flux kontext+controlnet工作流介绍,大家可以根据工作流思路进行尝试搭建。
当然,也可以在我们closerAI会员站上获取对应的工作流(查看原文)。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。
>/ 作者:JimmyMo
更多AI前沿科技资讯,请关注我们:

主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网
评论(0)