


更多AI前沿科技资讯,请关注我们:
【closerAI ComfyUI】flux kontext dev 多图融合进阶技巧!提高融合概率的方法技巧,建议收藏学习!赞!
大家好,我是Jimmy。本期继续带来一些在flux kontext模型的使用技巧。单图编辑不用多说,详细描述即可,上期也讨论过:
【closerAI ComfyUI】flux kontext dev提示词指南,同时探索controlnet控制一起生成的可行性
上期探索了controlnet控制,让多图融合时能作为条件引导flux kontext生成对应动作。理论上是可行的,在一定程度上是作用明显的。
这期,同样围绕flux kontext多图融合编辑上的能力分享我在使用过程中,探索出来的提高融合概率的技巧,可能有不对的地方,仅供参考。我们已经知道,kontext多图融合是玄学,难控制,一次出不了满意的结果,需要多抽卡。这期我们探索出来的结果,能够极大概率地融图,我们先看效果:



控制在哪一个场景下合照都行:



我们优化后的closerAI flux kontext多图融合工作流:
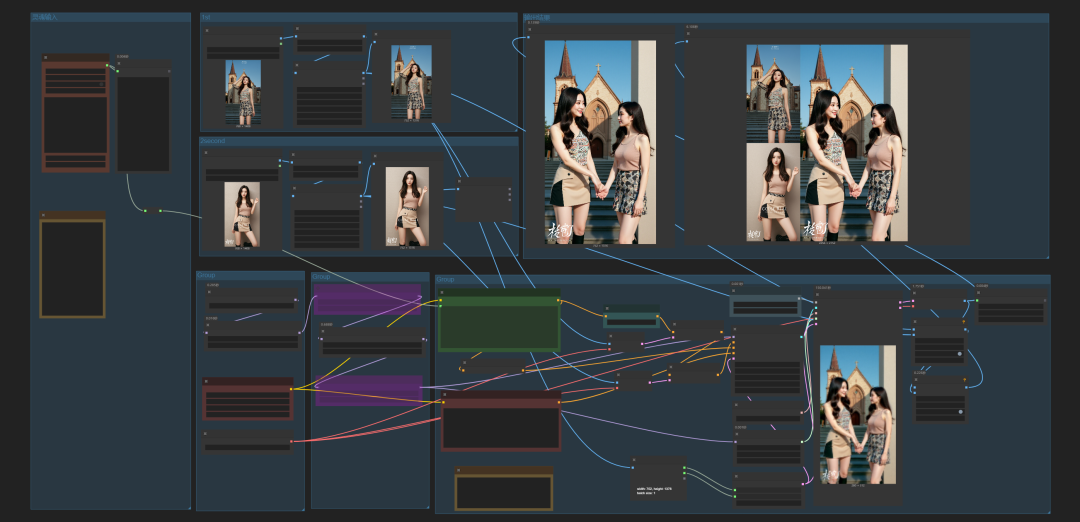
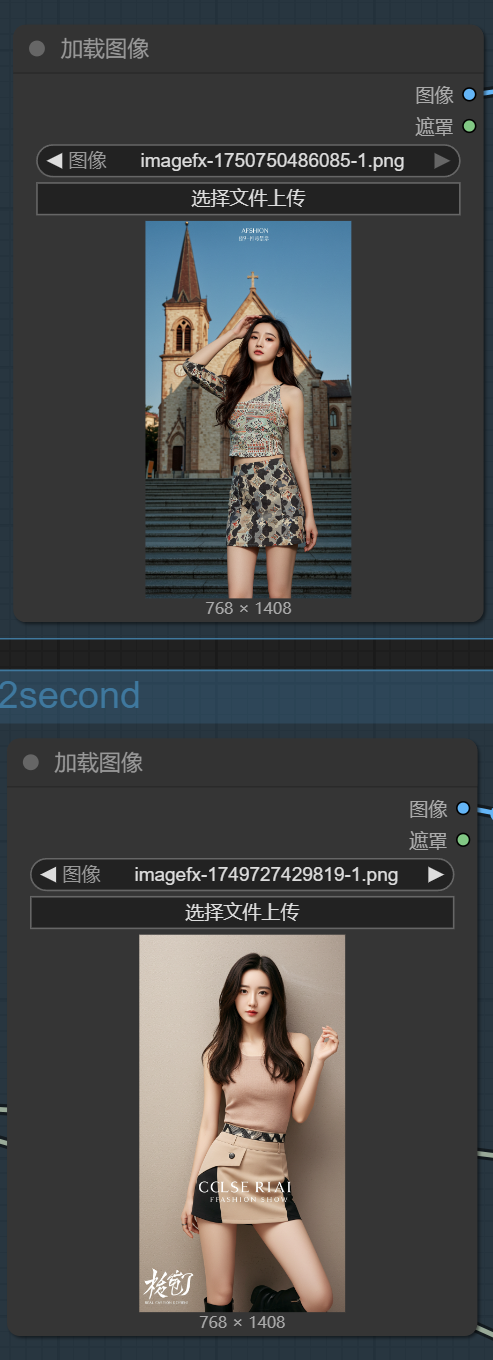
在此之前,我们加载两张图,进行融图:
我们使用comfyUI官方提供的工作流来进行对比。以下是comfyUI官方的flux kontext工作流:
我们需要他们做什么?我们让这两张图的美女在第一张图的背景中进行握手。
这里第一步就是提示词的技巧优化。
提示词我们要描述清楚,一般我们都会写“两张图的美女在第一张图的背景中进行握手,保持人物外貌、服饰不变”大概这样的描述。相信我们大多数都会类似描述,我们都会为提示词焦头烂额,像我语文不好,形容词量不多,要详细描述也只能请LLM帮忙。一是自己写麻烦,二是惰性。所以,我想直接LLM解决提示词。
于是我用cursor开发一个简单kontext生成器
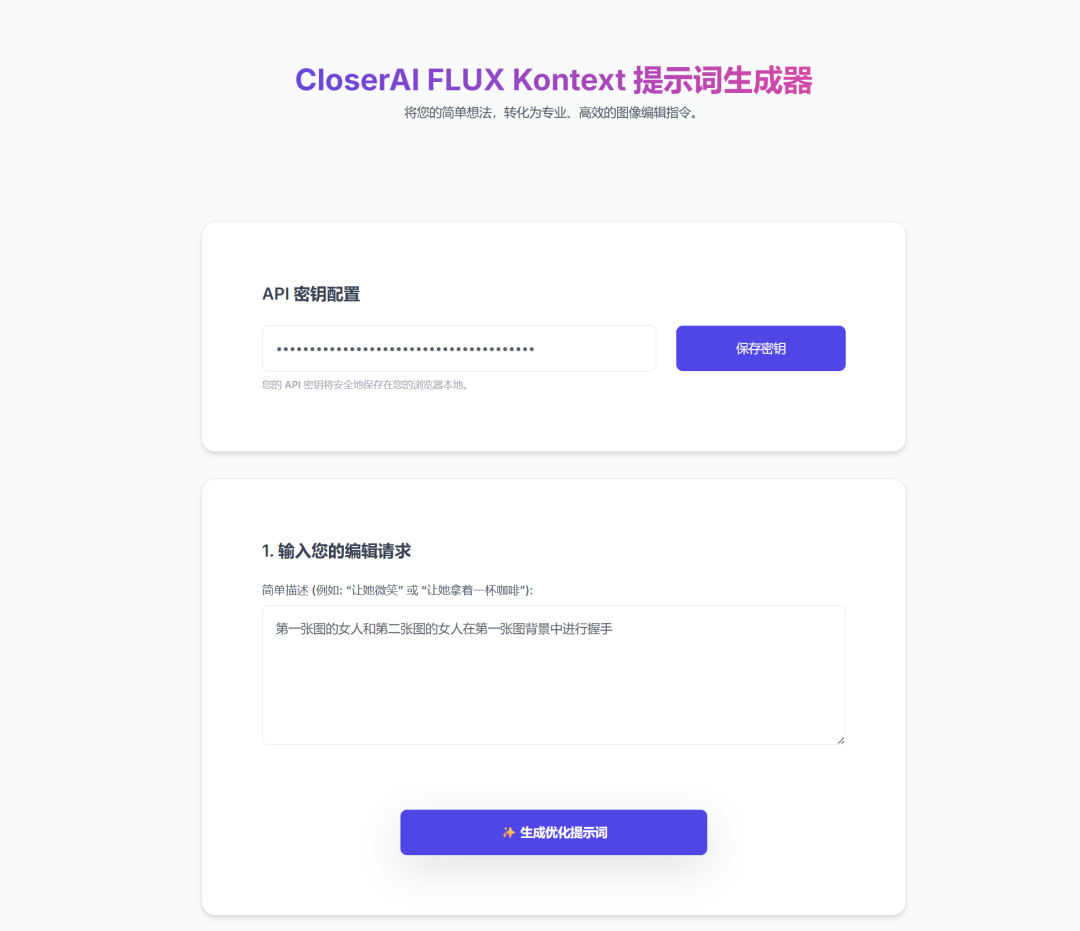
这个生成提示词的逻辑就是黑森林官方对于kontext的说明文档:https://docs.bfl.ai/kontext/kontext_image_editing
让LLM学习这个模型的提示词规则,将用户输入后的内容转换成模板化的提示词。
这里我是直接使用gemini来实现。使用它的API来完成的。
我将这个提示词生成器已经放这里了:http://aigc.douyoubuy.cn/closerai-flux-kontext/
打开就能用。当然,大家可以自己写,有条件的,能用gemini的小伙伴可以尝试下用。
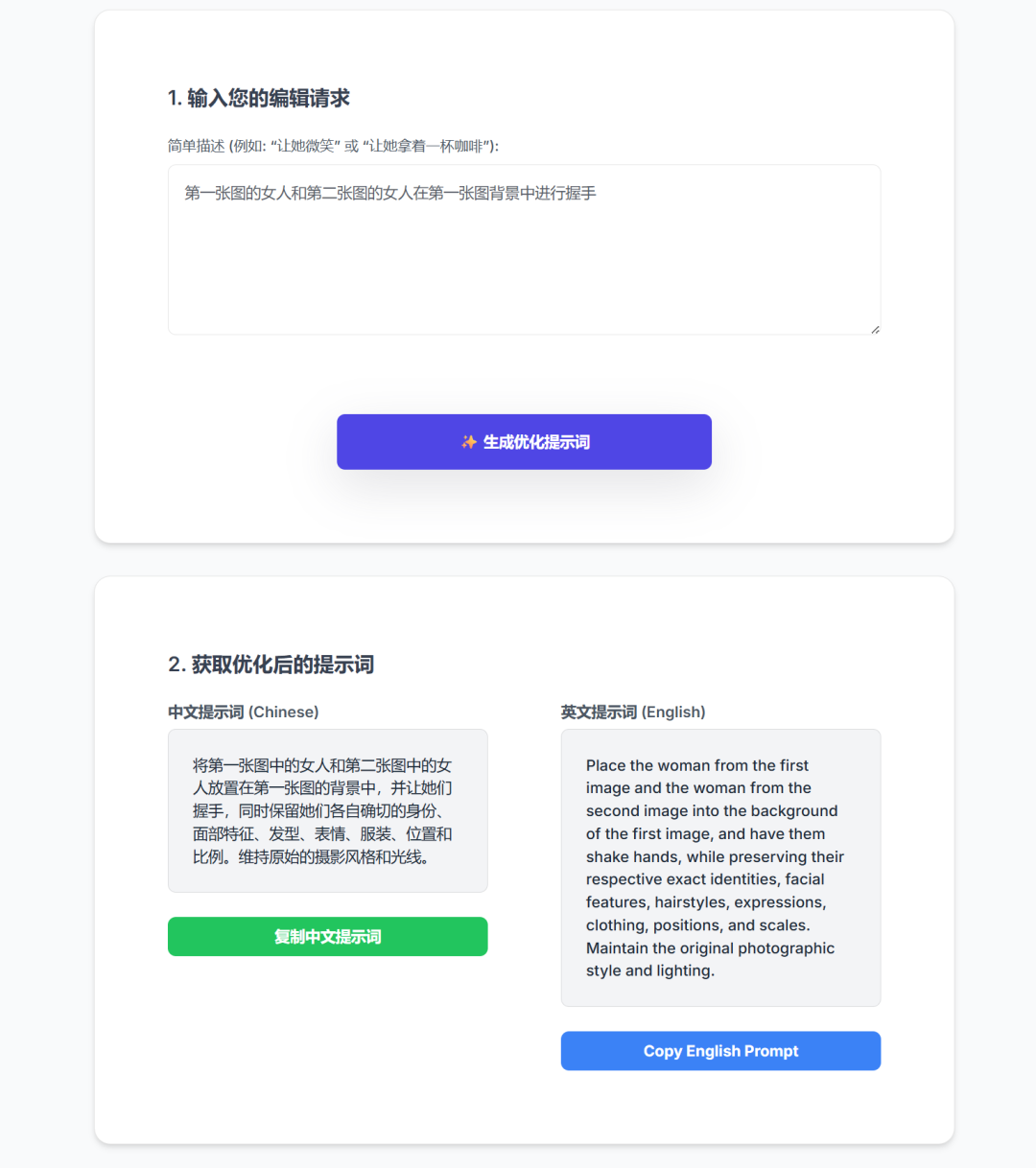
输入:第一张图的女人和第二张图的女人在第一张图背景中进行握手
得出中英文提示词:
将第一张图中的女人和第二张图中的女人放置在第一张图的背景中,并让她们握手,同时保留她们各自确切的身份、面部特征、发型、表情、服装、位置和比例。维持原始的摄影风格和光线。
Place the woman from the first image and the woman from the second image into the background of the first image, and have them shake hands, while preserving their respective exact identities, facial features, hairstyles, expressions, clothing, positions, and scales. Maintain the original photographic style and lighting.
当然,大家可以让AI助手像豆包来学习后进行输出,一样的。在豆包让它学习官方文档,给它任务,你输入什么,就让它学习规则后输出对应的提示词即可。
知识库的原理。没什么难度的。
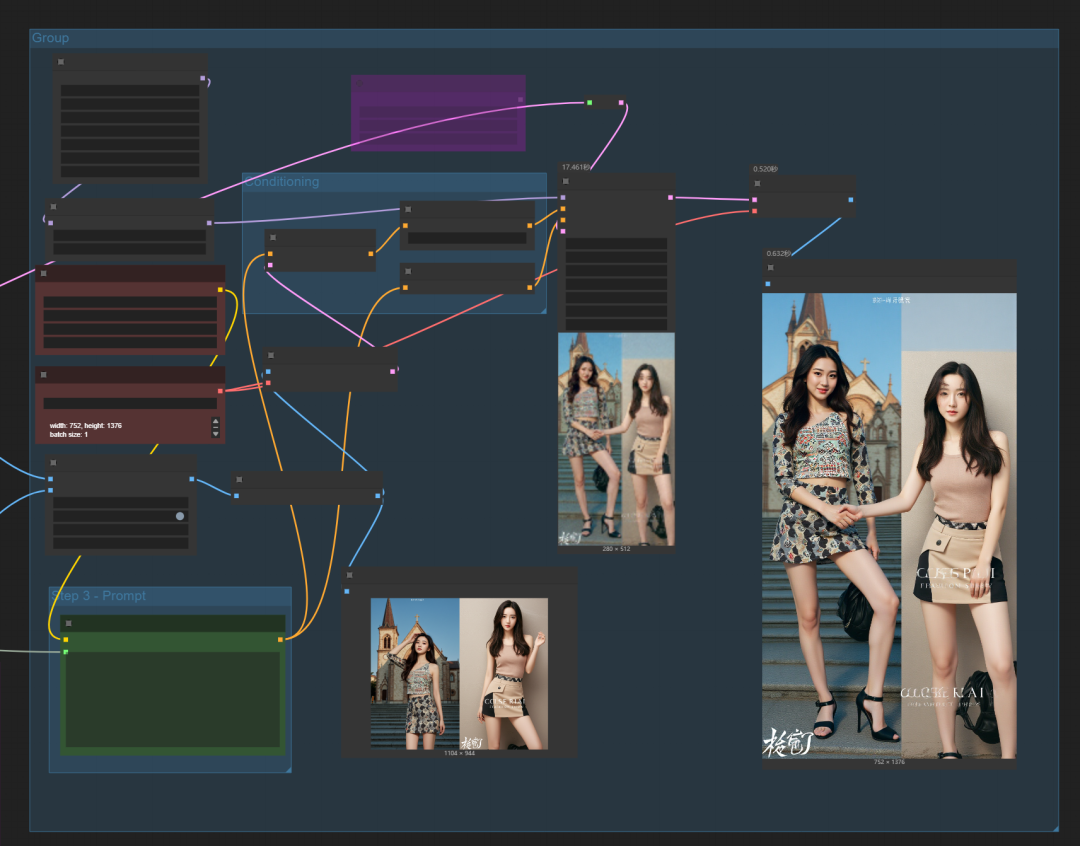
执行后:这是抽卡多次后稍微满意的,但又不怎么符合我们需求的。



我们可见,基本很抽卡出满意的,老是会分割图片。
官方的工作流中原理是将两张图联结起来形成一张图。这是之前我们FLUX模型作万物迁移的重要控制原理之一。同一张图,能重绘出类似的元素。
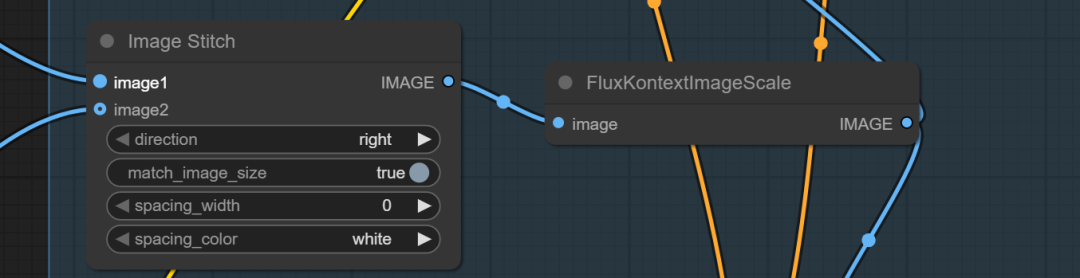
联结后的图,经过referenclLatent,将提示词条件和图像编码形成条件加入K采样器中。
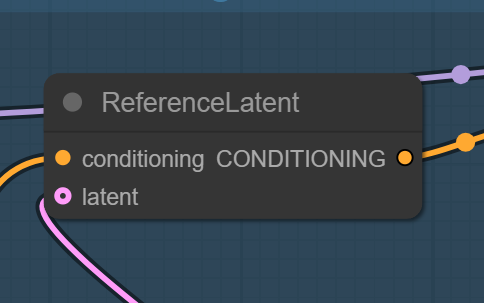
但在kontext中好像时好时坏,不太可控。
那我们是不是可以将N张图分开串联起来再让它进入潜空间?
重要调整如下:
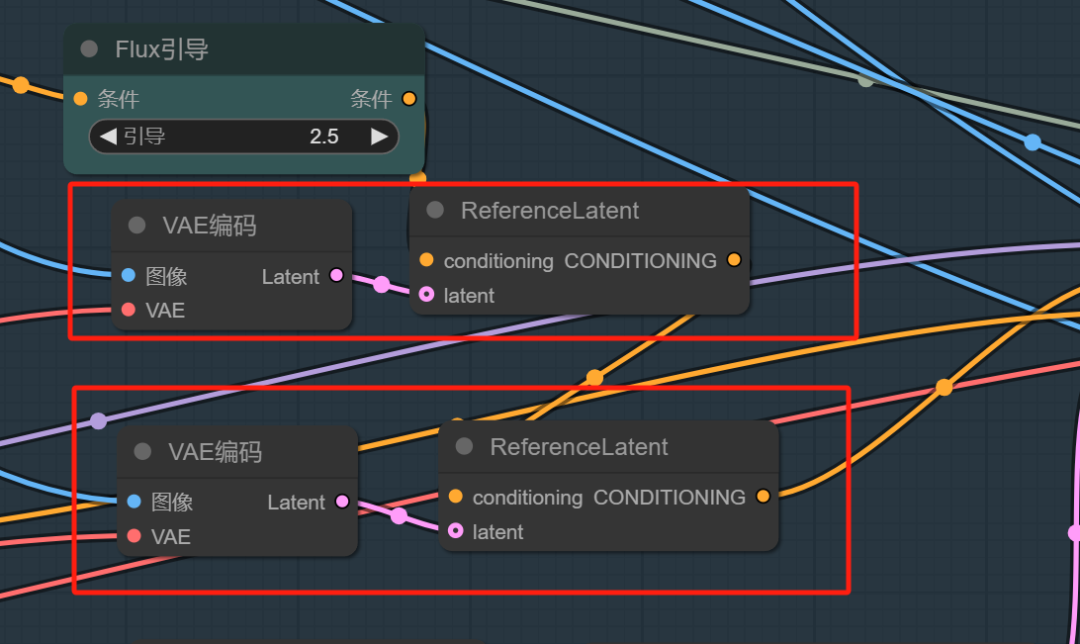
第一张图的VAE编码接上referenclLatent再串上第二张图的VAE编码接上的referenclLatent,如上图示。串联接入。
我们再执行一次。我们会发现,它更容易合成了。


这是技巧之一,分开串联!
技巧二:NAG的加入。
NAG 是不是很熟悉?之前介绍过,KJ大佬应用到wan2.1中了。但是FLUX没支持:
【closerAI ComfyUI】注意力引导开外挂!NAG:归一化注意力引导,让扩散模型效果又准又稳,可控性直接拉满!
这个节点的作用就是让负面提示词在少步推理中也起作:
少步扩散模型有助于快速推理,但通常缺乏对CFG的支持,使负面指导无效。
NAG恢复有效的负面提示,从而能够直接抑制视觉、语义和风格属性。这增强了可控性,并在构图、风格和质量方面扩大了创作自由。
但最近有个大佬,支持了FLUX生图!
ComfyUI-NAG
https://github.com/ChenDarYen/ComfyUI-NAG
直接安装节点就行了。
在上面分开串联的基础上,接入NAG这个灵魂的负面提示词引导,如下图示:
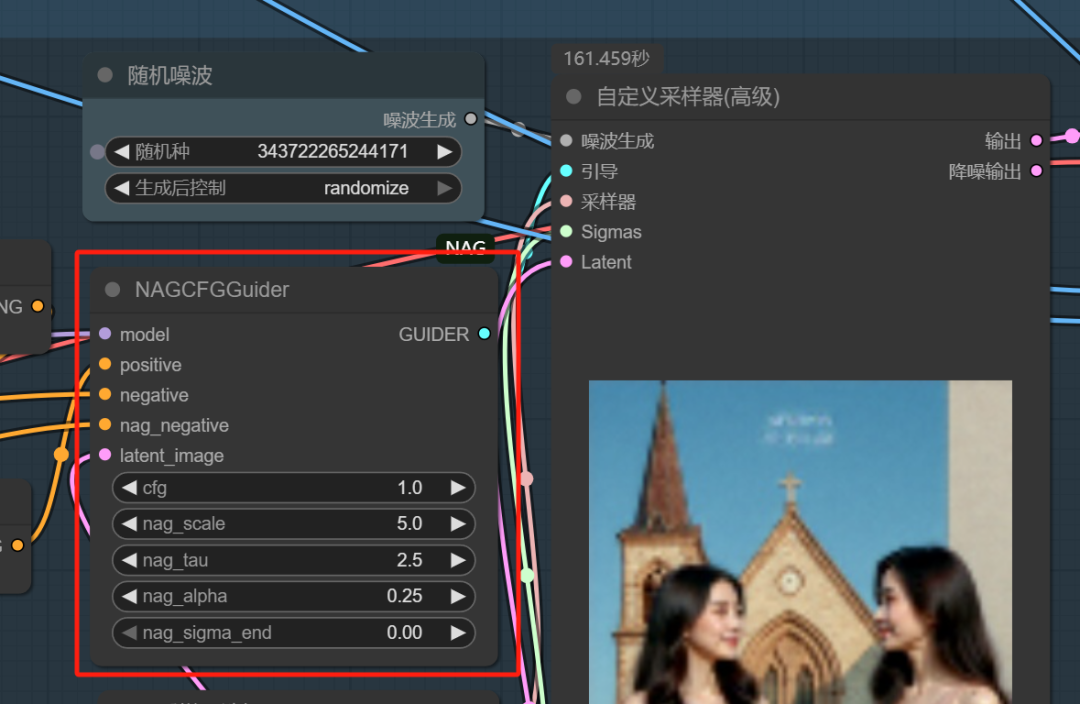
就算你不写负面提示词,它竟然能稳定地合成。
如下图示,就是分开串联+NAG后的工作流。



相对稳定在能合成图了。我们再尝试下,换两张图:
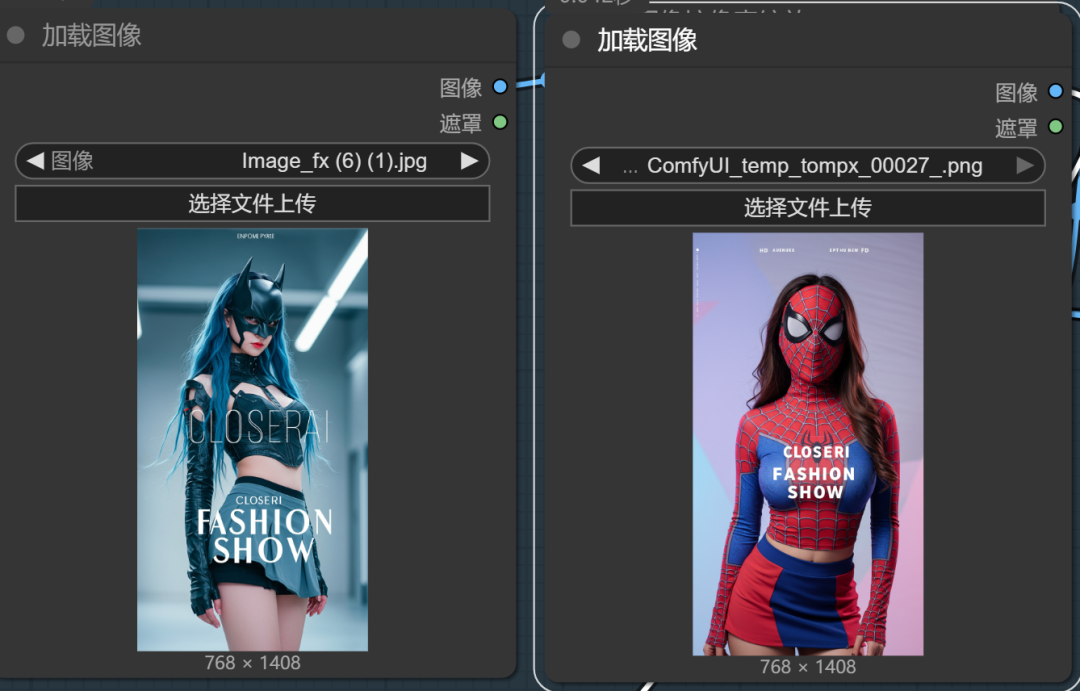
提示词不改了,还是上面的。执行后,真的超赞!

本地算力不够怎么办?
如果本地设备算力不好的小伙伴,推荐使用线上comfyUI来运行体验:runninghub.cn
Flux Kontext Dev动嘴P图流体验地址:
https://www.runninghub.cn/ai-detail/1938445554957639681
注册地址:https://www.runninghub.cn/?utm_source=kol01-RH151
通过这个链接第一次注册送1000点,每日登录送100点
最后几句:
kontext高级进阶使用技巧分享:
1、将图片分开串联而不是联结。
2、使用NAG。
3、提示词优化。
三点技巧,让flux kontext多图融合更符合我们想要的结果。
以上是closerAI团队制作的stable diffusion comfyUI closerAI搭建的closerAI flux kontext多图融合(非联结版)工作流介绍,大家可以根据工作流思路进行尝试搭建。
当然,也可以在我们closerAI会员站上获取对应的工作流(查看原文)。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。
>/ 作者:JimmyMo
更多AI前沿科技资讯,请关注我们:

主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网
评论(0)