
更多AI前沿科技资讯,请关注我们:
【closerAI ComfyUI】实时字幕、精准对齐、方言识别, 阿里 Qwen3-ASR 震撼发布,AI 语音交互的最后一块拼图齐了!支持 52 种语言方言

大家好,我是Jimmy。qwen3TTS刚开源不久后:3秒音频克隆声音!支持10大语种!Qwen3-TTS重塑语音合成:声音复刻、声音设计、多人音频等,comfyui部署使用简单高效!自媒体必备神器!又迎来了一波增强,ASR模型一个语音转文本的模型开源,至此,一个完整的音频到文本,文本到音频的解决方案已出现。
我们先来介绍下Qwen3-ASR
🚀 Qwen3-ASR 完整生态
Qwen3-ASR 是由阿里巴巴 Qwen 团队最新推出的开源语音识别(ASR)模型家族。该项目基于其强大的多模态基座模型 Qwen3-Omni 构建,旨在提供高性能、低延迟且多语言支持的语音转文字解决方案。
以下是该项目的主要核心亮点:
1. 模型成员
- Qwen3-ASR-1.7B:旗舰版本,旨在达到开源界的 SOTA(州级)性能,并能与顶尖的商业 ASR API 竞争。
- Qwen3-ASR-0.6B:轻量化版本,主打极速推理。在 128 并发下,其吞吐量可达 2000 倍速。
- Qwen3-ForcedAligner-0.6B:专门用于强制对齐的模型,能够精确预测词级或字符级的时间戳(支持 11 种语言)。

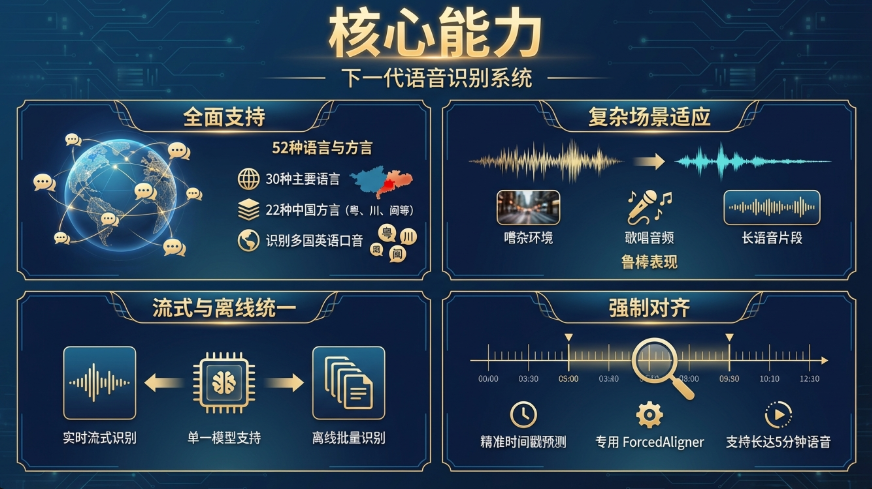
2. 核心能力
- 全能支持:支持 52 种语言和方言,包括 30 种主要语言和 22 种中国方言(如粤语、四川话、闽南语等),还能识别各国的英语口音。
- 复杂场景适应:在背景噪音、歌唱音频、长音频等复杂声学环境下表现稳健。
- 流式与离线统一:单个模型即可支持流式实时识别和离线批量识别。
- 强制对齐:通过专门的 ForcedAligner,支持长达 5 分钟语音的精准时间戳预测。
3. 技术优势与推理框架
- 架构优势:继承了 Qwen3 系列强大的语言理解能力。
- 高效推理:深度集成 vLLM 和 FlashAttention 2,显著降低显存占用并提升推理速度。
- 工具链完备:提供官方 Python 包 qwen-asr,支持一键部署 Gradio Web Demo、API 服务或 Docker 容器镜像。
项目链接:https://github.com/QwenLM/Qwen3-ASR
🚀 Qwen3-ASR comfyUI中的实现
ComfyUI-Qwen3-ASR 是由社区开发者提供的适配插件,它将 Qwen3-ASR 的强大能力引入到了目前最流行的可视化 AI 工作流平台 ComfyUI 中。
项目链接:https://github.com/DarioFT/ComfyUI-Qwen3-ASR
如何开始使用 ComfyUI 插件?
- 安装:通过 ComfyUI Manager 搜索 ,ComfyUI-Qwen3-ASR 或手动将项目 clone 到 custom_nodes文件夹。
- 模型下载:插件通常会自动或引导你从 HuggingFace/ModelScope 下载 Qwen3-ASR-1.7B权重。
- 连接节点:在搜索菜单中输入 "Qwen3" 找到对应节点,输入音频(Load Audio),输出文本(STRING)。
安装后,打开示例工作流,如下图示:
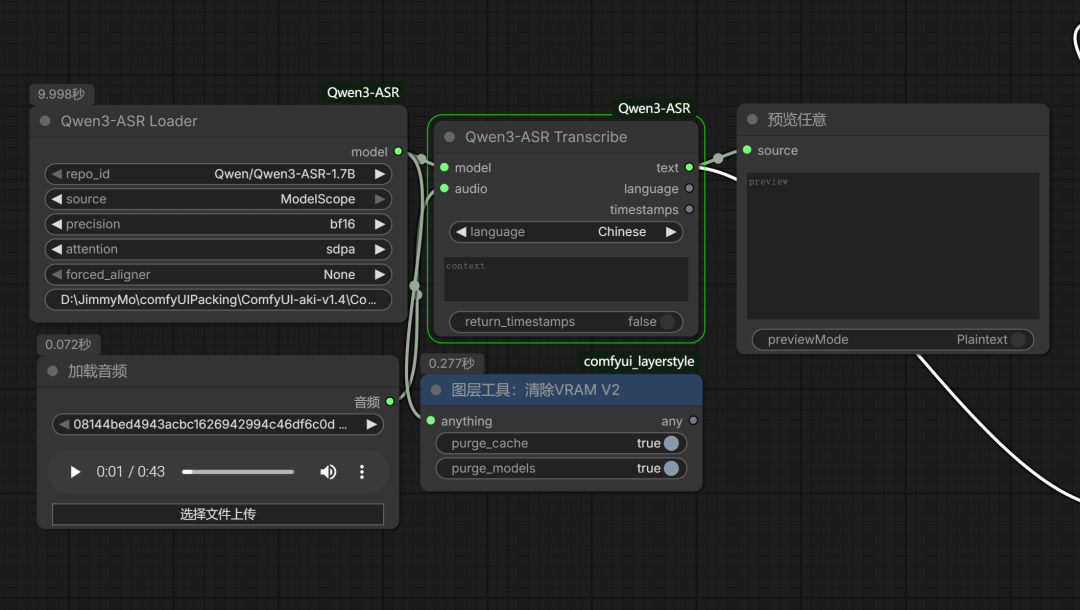
模型会自动下载,下载后就能正常使用。
加载一个音频:
然后执行工作流:
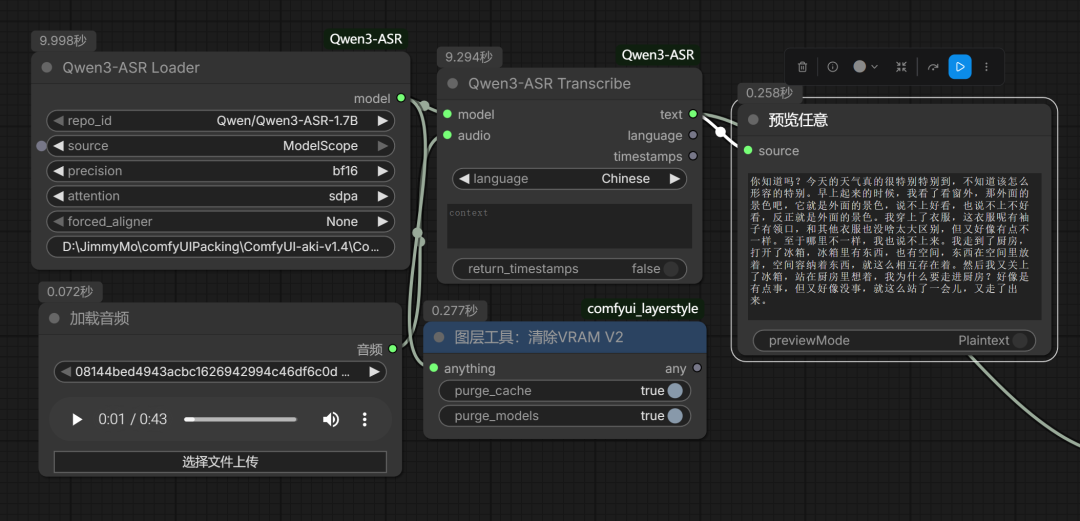
就能转换成文本:
你知道吗?今天的天气真的很特别特别到,不知道该怎么形容的特别。早上起来的时候,我看了看窗外,那外面的景色吧,它就是外面的景色,说不上好看,也说不上不好看,反正就是外面的景色。我穿上了衣服,这衣服呢有袖子有领口,和其他衣服也没啥太大区别,但又好像有点不一样。至于哪里不一样,我也说不上来。我走到了厨房,打开了冰箱,冰箱里有东西,也有空间,东西在空间里放着,空间容纳着东西,就这么相互存在着。然后我又关上了冰箱,站在厨房里想着,我为什么要走进厨房?好像是有点事,但又好像没事,就这么站了一会儿,又走了出来。
这个时间再接入qwen3TTS 克隆节点
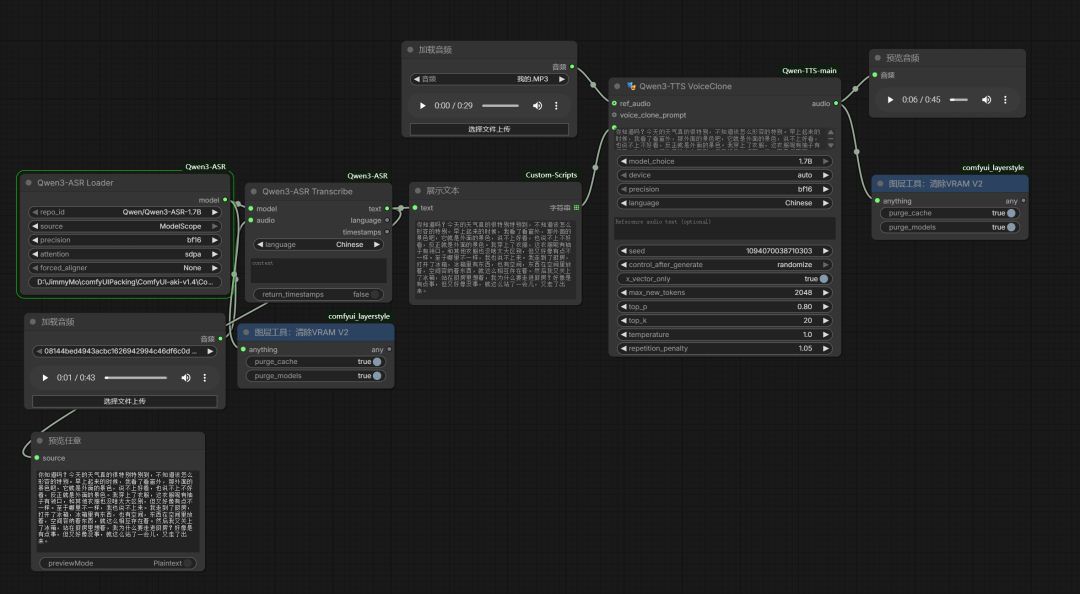
执行后输出克隆声音与合成内容:
这就是完整的音频转文本,文本转音频的实现过程。
虽然在comfyUI不能做到实时字幕,受形态限制。 其实qwen3 ASR 是能做到实时字幕的效果,即所说即所见。那官方也提供了实现的方法,具体看其github。
为了方便在comfyUI将语音转换文本,我开发了个qwen3TTS 助手:
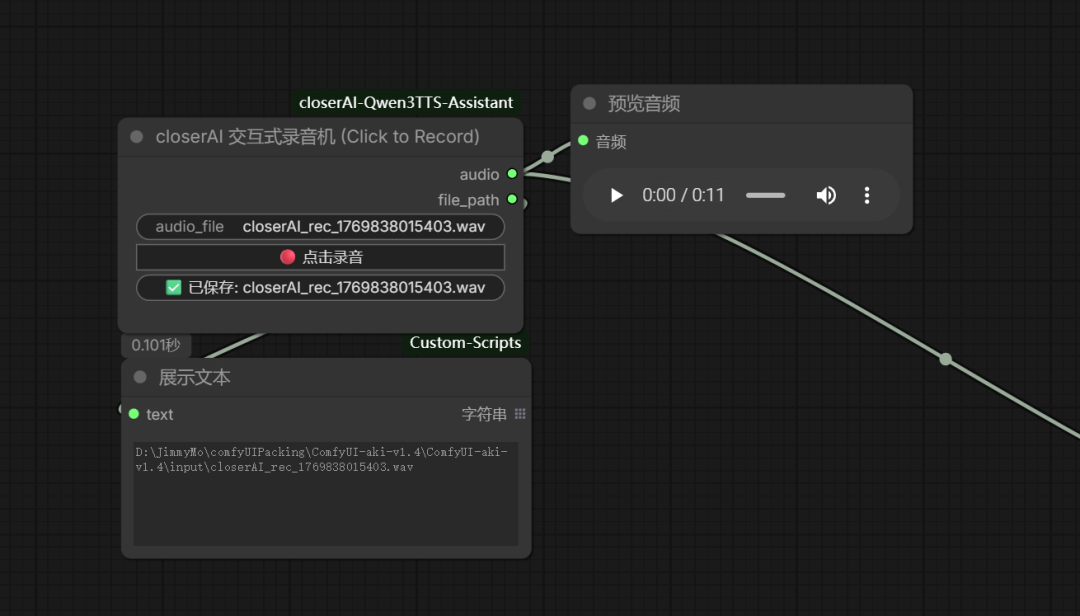
交互式录音,直接点击录音,录完就能转成文本。
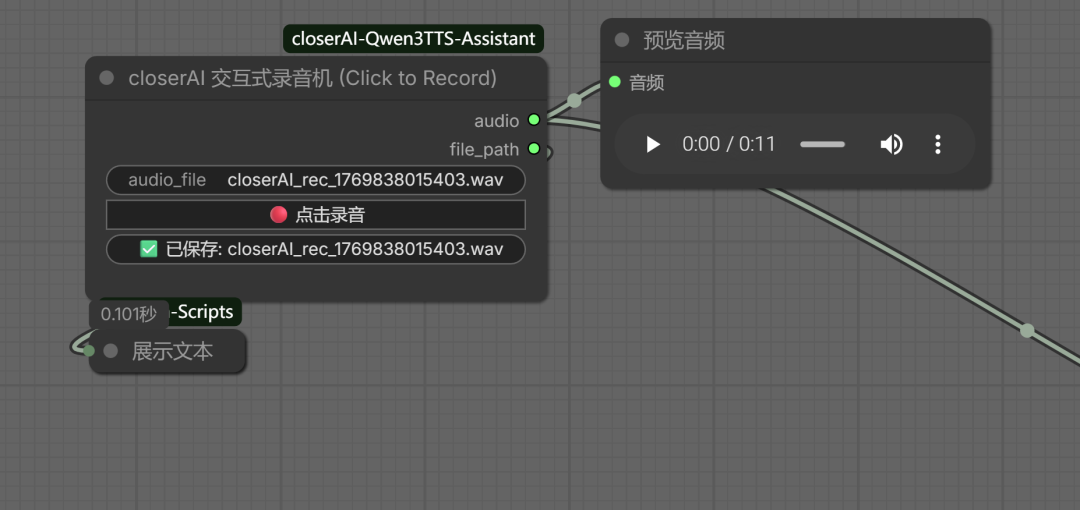
然后工作流如下:
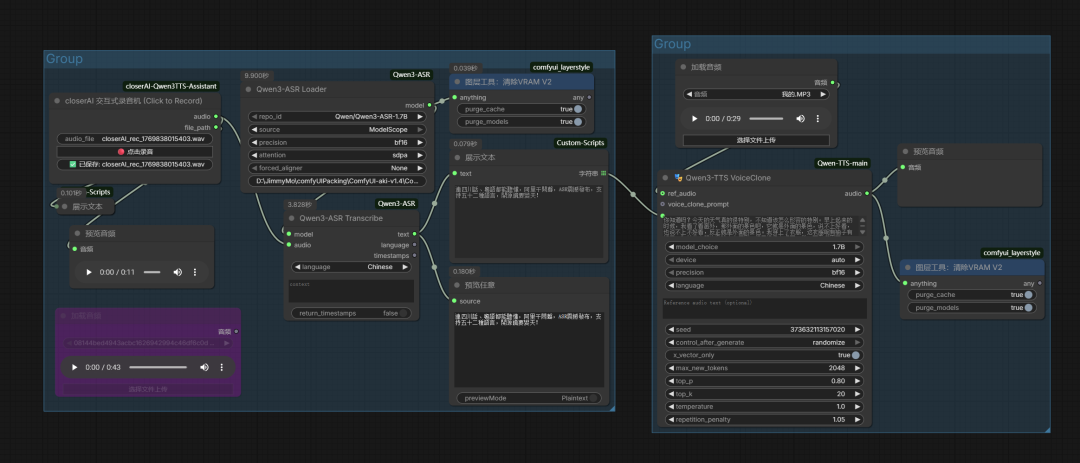
除了交互式录音功能,在Qwen3TTS中,特别为声音设计开发了一个参数与智能提示词的节点,用于声音设计提示词的撰写:
closerAI Qwen3TTS-designAssistant
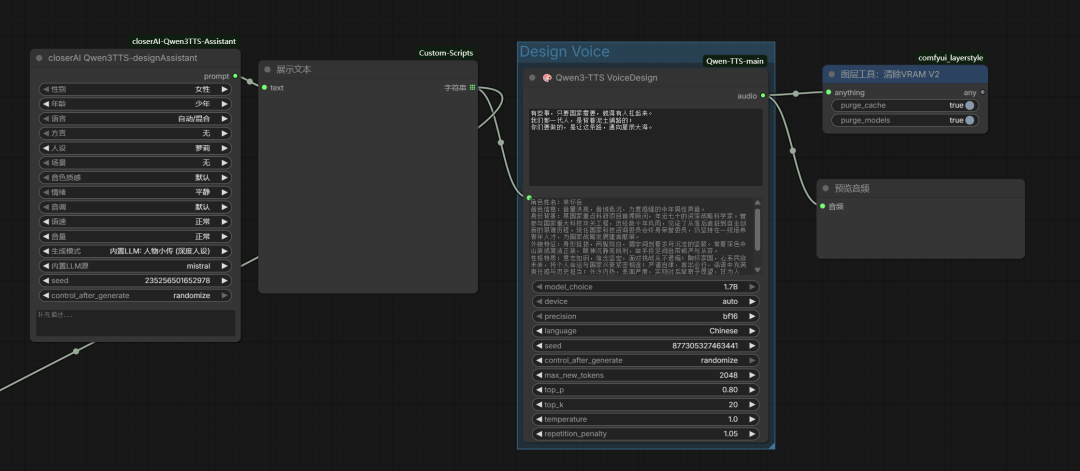
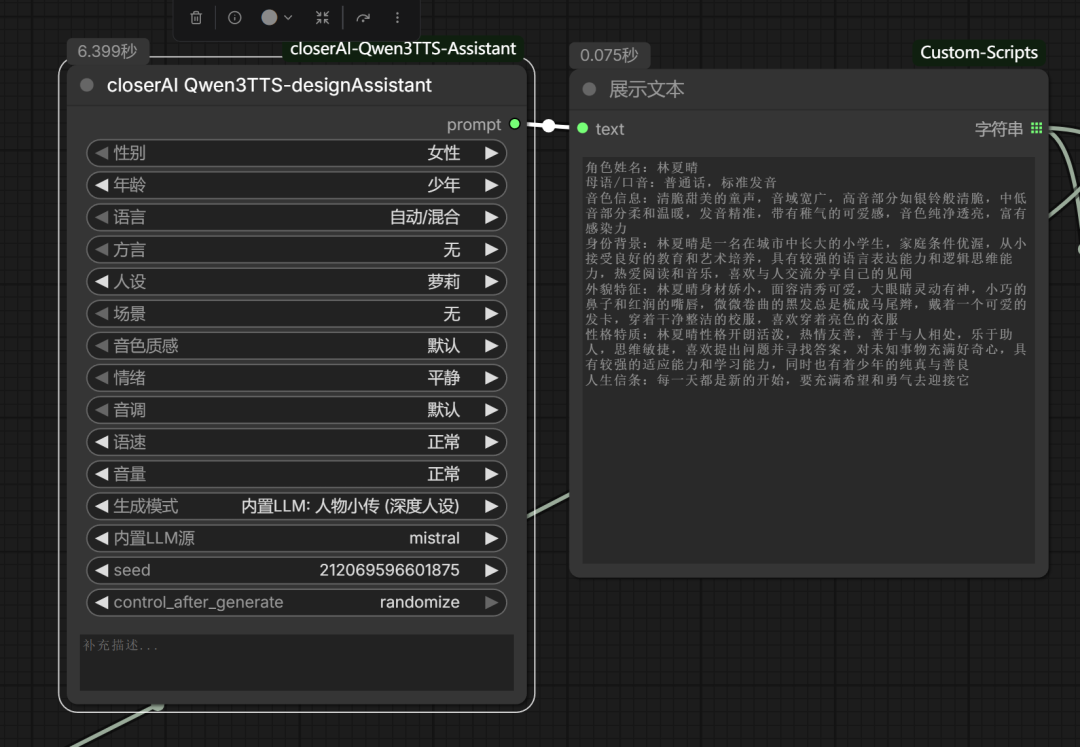
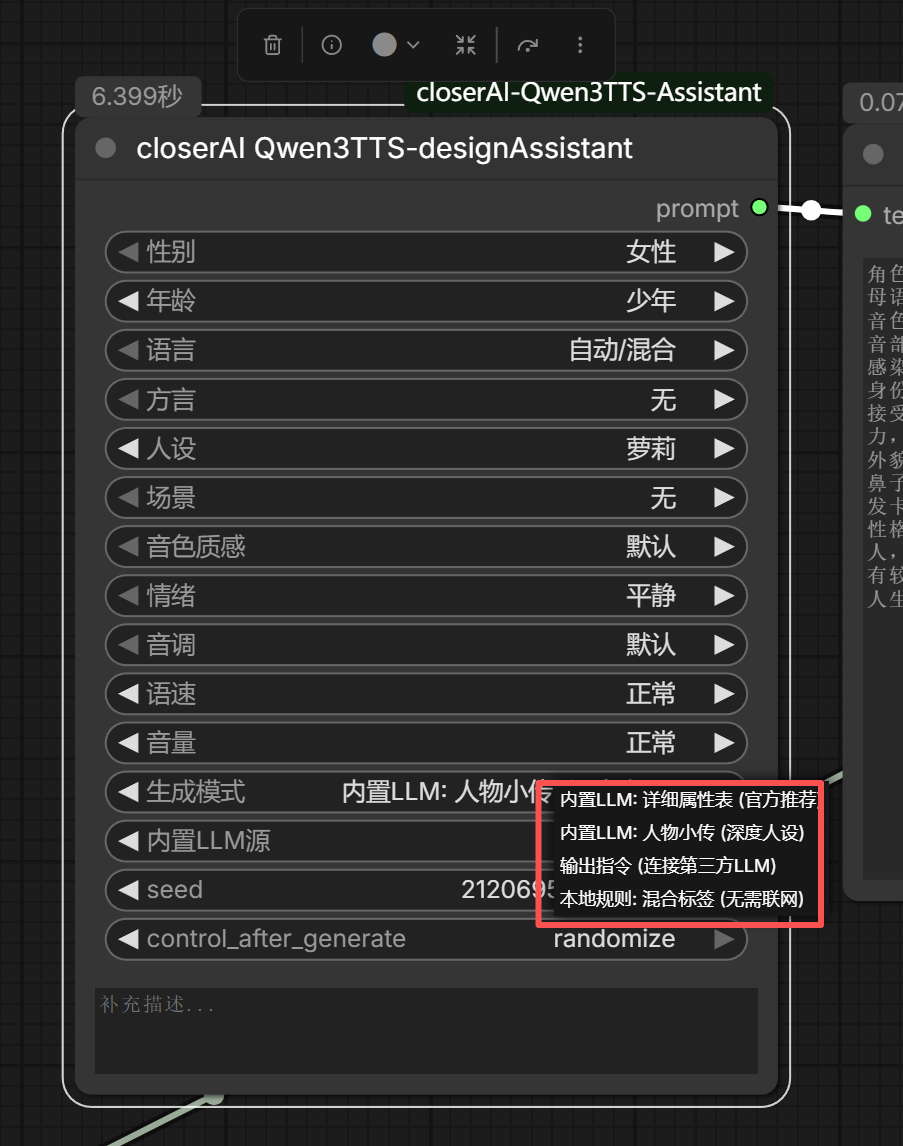
支持多种模式,内置LLM,也支持第三方LLM,
这是通过它生成的声音设计提示词:
角色姓名:林夏晴
然后通过声音设计节点生成:
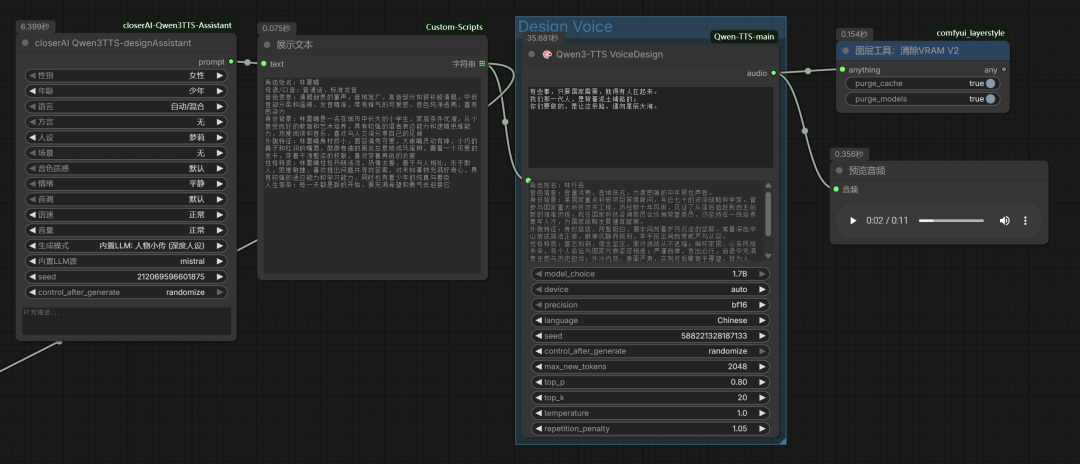
最后合成的音频如下:
以上就是关于qwen3TTS\ASR的全部解决方案工作流的内容。它是开源界音频转文本、文本转语音的性价比高的模型。
本地算力不够怎么办?
如果本地设备算力不好的小伙伴,推荐使用线上comfyUI来运行体验:runninghub.cn
qwen3TTS+InfiniteTalk数字人应用体验地址:
https://www.runninghub.cn/ai-detail/2015656735674998786
注册地址:https://www.runninghub.cn/?utm_source=kol01-RH151
通过这个链接第一次注册送1000点,每日登录送100点
最后几句:
如果对你有帮助,请一键三连支持下我,感谢
CloserAI 3D Pose Editor:
http://aigc.douyoubuy.cn/2025/12/03/3448/
closerAI-nanoPrompts:
http://closerai.douyoubuy.cn/2025/11/24/3396/
closerAI 分镜设计 软件(exe)本地运行版
http://aigc.douyoubuy.cn/2025/11/22/3350/
以下是closerAIwater节点:
http://aigc.douyoubuy.cn/2025/10/22/3121/
分镜分词器节点:
http://aigc.douyoubuy.cn/2025/10/11/3080/
json结构化提示词
http://aigc.douyoubuy.cn/2025/11/05/3242/
以上是closerAI团队制作的stable diffusion comfyUI closerAI-qwen3TTS+ASR音频转文本+文本转音频工作流,我们closerAI会员站上获取(查看原文)。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。
>/ 作者:JimmyMo
更多AI前沿科技资讯,请关注我们:

主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网

评论(0)