
更多AI前沿科技资讯,请关注我们:
【closerAI ComfyUI】本地推理的轻量级标杆视觉模型:腾讯优图发布 Youtu-VL,40 亿参数开启“全能视觉”轻量化新时代

大家好,我是Jimmy。
在多模态大模型(VLM)领域,性能与体量往往难以兼得。然而,腾讯优图实验室(Tencent Youtu Lab)近期推出的 Youtu-VL 正在打破这一僵局。作为一个仅拥有 40 亿(4B)参数的轻量级模型,它凭借创新的架构设计,在视觉感知和通用理解上展现出了挑战巨头模型的实力。
项目地址:https://huggingface.co/tencent/Youtu-VL-4B-Instruct
🚀 核心突破:视觉与语言的“深度融合”
传统的视觉语言模型往往将视觉信号视为“被动”的输入条件,这导致模型在处理细节时容易产生偏见。Youtu-VL 的强大源于其核心技术:视觉语言统一自回归监督(VLUAS)。
- 统一词汇表:它不仅学习文字,还通过视觉码本将视觉信号转化成“词汇”,纳入统一的多模态词汇表中。
- 自回归预测:模型在训练时会像生成文字一样“重构”视觉标记。这种机制让模型不再只是走马观花,而是能够显式地保留和理解细粒度的视觉信息。
✨ 全能表现:不仅是聊天,更是视觉专家
Youtu-VL 最令人惊艳的地方在于它的通用性。无需为特定任务添加额外的功能模块,它就能在标准架构下完成多种高难度动作:
1. 极强的视觉中心能力
不同于只能“看图说话”的普通模型,Youtu-VL 具备深度的空间感知能力,支持:
- 目标检测与定位(Detection & Grounding)
- 图像分割(参考分割、语义分割)
- 深度估计与目标计数
- 人体姿态估计
2. 卓越的多模态理解
在通用任务中,它同样表现稳健:
- OCR 识别:精准读取图像中的文本。
- 复杂推理:处理数学问题及多图关联理解。
- GUI 代理:具备理解图形用户界面并执行操作的潜力。
- 低幻觉:显著降低了多模态模型常见的“胡言乱语”现象。
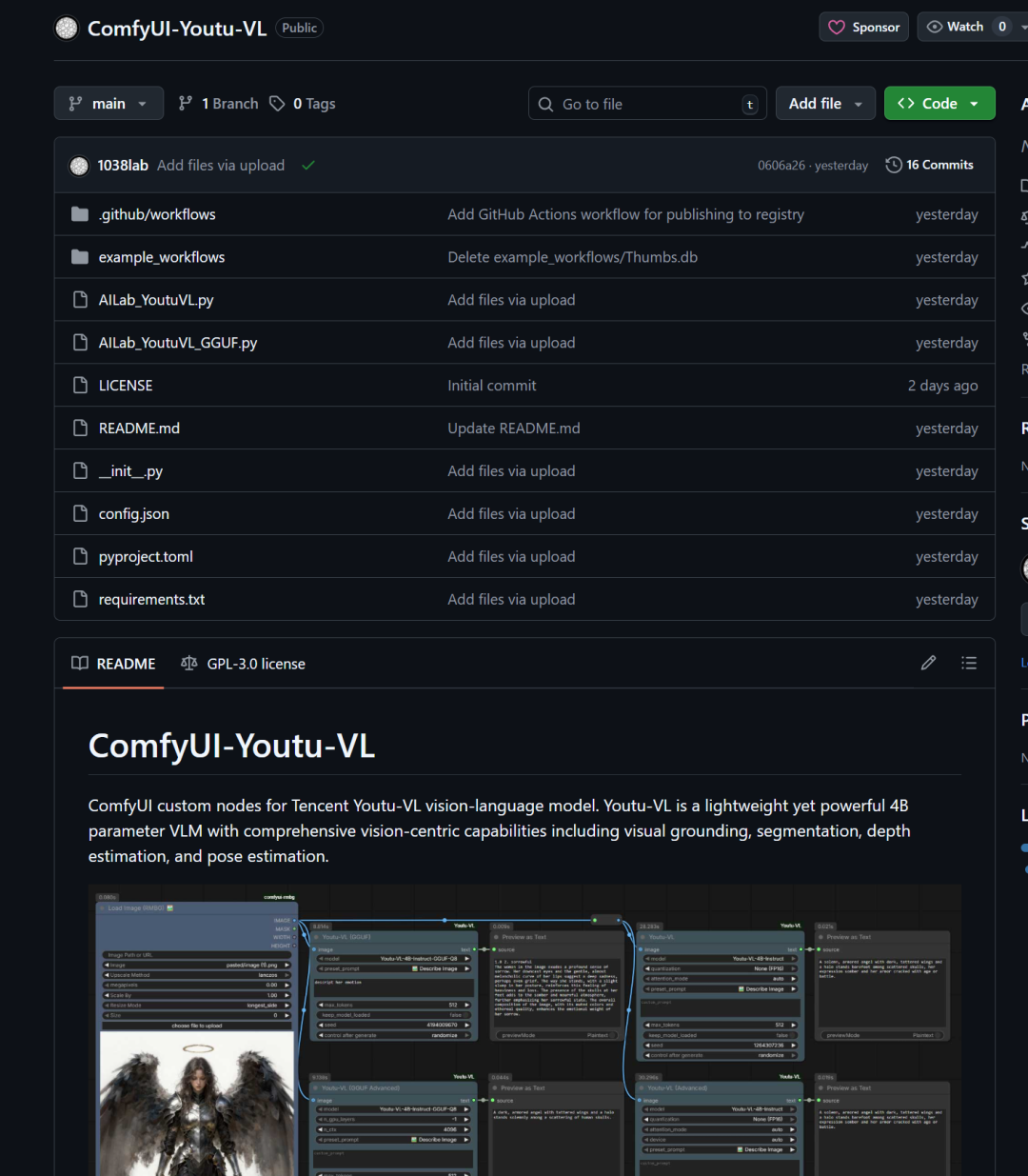
comfyUI中的实现与体验
目前已有社区作者开发了对应的comfyUI插件
comfyUI插件:https://github.com/1038lab/ComfyUI-Youtu-VL
一、手动安装
- 打开终端,进入你的 ComfyUI 插件目录:cd ComfyUI/custom_nodes/
- 克隆仓库:git clone https://github.com/1038lab/ComfyUI-Youtu-VL.git
- 安装依赖:cd ComfyUI-Youtu-VL pip install -r requirements.txt
拖出示例工作流,直接执行,会自动下载,当然你的设备如果在8G以下,可使用GGUF节点:
启用 GGUF 支持(显存优化)
如果你希望在消费级显卡(6GB+)上获得更快的速度,建议安装 llama-cpp-python:
# 请根据你的 CUDA 版本替换 cu121 (例如 cu118) pip install llama-cpp-python --extra-index-url https://abetlen.github.io/llama-cpp-python/whl/cu121
下载GGUF模型的话,可以在以下链接下载:
https://huggingface.co/mradermacher/Youtu-VL-4B-Instruct-GGUF/tree/main
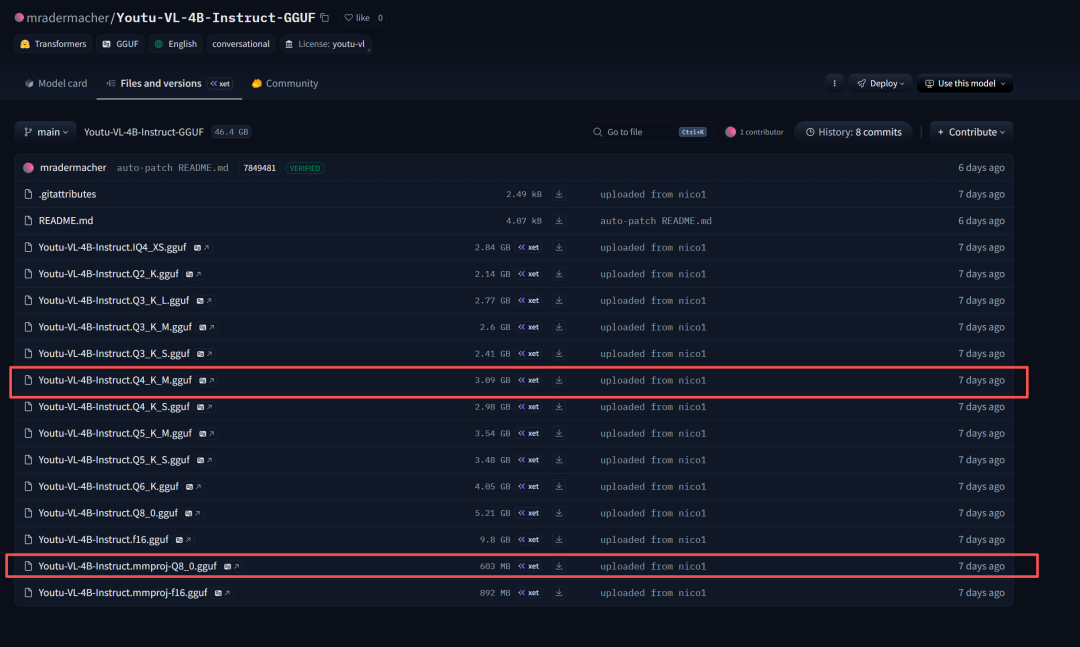
二、GGUF模型的选择与下载
根据您的显存大小,下载以下两个文件(主模型 + 视觉投影器):
1. 主模型(大脑 - 负责处理文本和逻辑):
- 推荐(平衡速度与质量): Youtu-VL-4B-Instruct.Q4_K_M.gguf (约 3.09 GB) ——适合 6GB-8GB 显存。
- 高性能(质量稍好): Youtu-VL-4B-Instruct.Q5_K_M.gguf (约 3.54 GB) ——适合 8GB+ 显存。
- 极致速度(质量较低): Youtu-VL-4B-Instruct.Q3_K_M.gguf (约 2.6 GB) ——适合低显存设备。
2. 视觉投影器(眼睛 - 负责看图):
- 必须下载:Youtu-VL-4B-Instruct.mmproj-f16.gguf(892 MB) 或者 mmproj-Q8_0.gguf(603 MB)。
- 注意:通常视觉大模型(VLM)的 GGUF 版本需要这个 mmproj 文件来处理图像输入。如果节点无法自动识别,请确保它与主模型在同一目录下。
第三步:文件放置位置
将下载好的 .gguf 文件移动到 ComfyUI 的模型目录下。
- 目标路径: ComfyUI/models/LLM/(如果 LLM 文件夹不存在,请手动创建一个)
然后重启comfyUI
我用的是Youtu-VL (GGUF),因为目前这个插件在使用其它版本GGUF模型时有问题,不能自动扫描本地模型。我修改了下节点代码,使之能正常使用其它版本的GGUF,如果大家行就直接自动下载它的Q8模型使用。我们的会员小伙伴直接在网站下载修改后的插件使用。
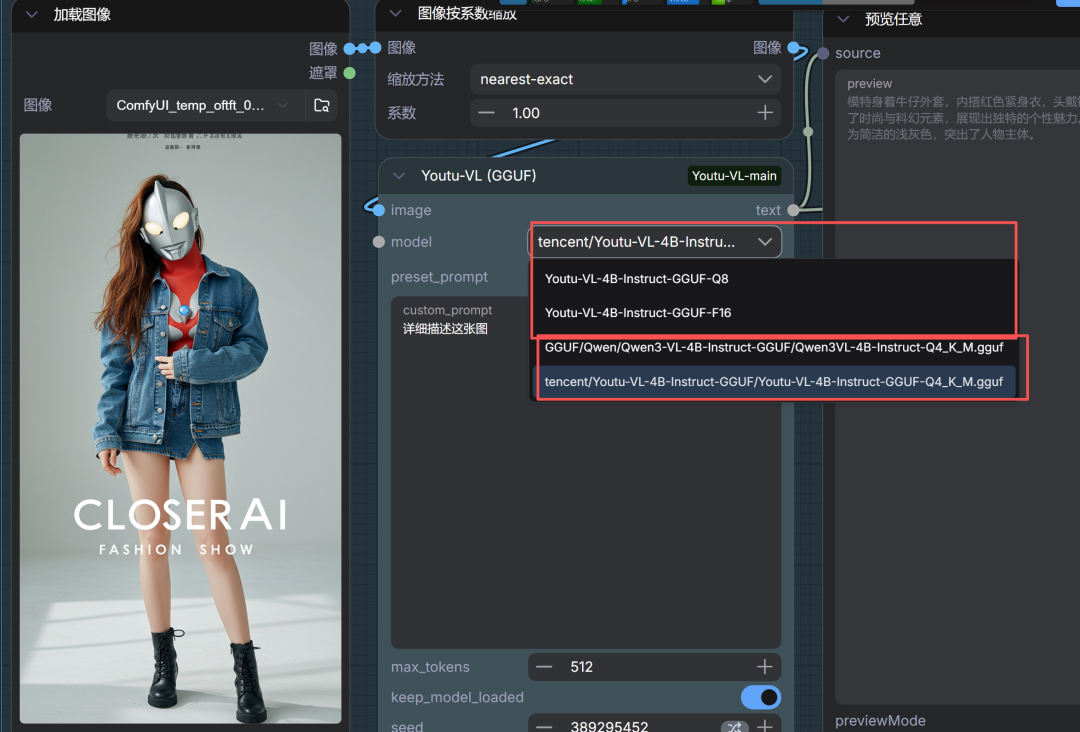
comfyUI中的体验
直接输入节点名称,然后搭建如下工作流:
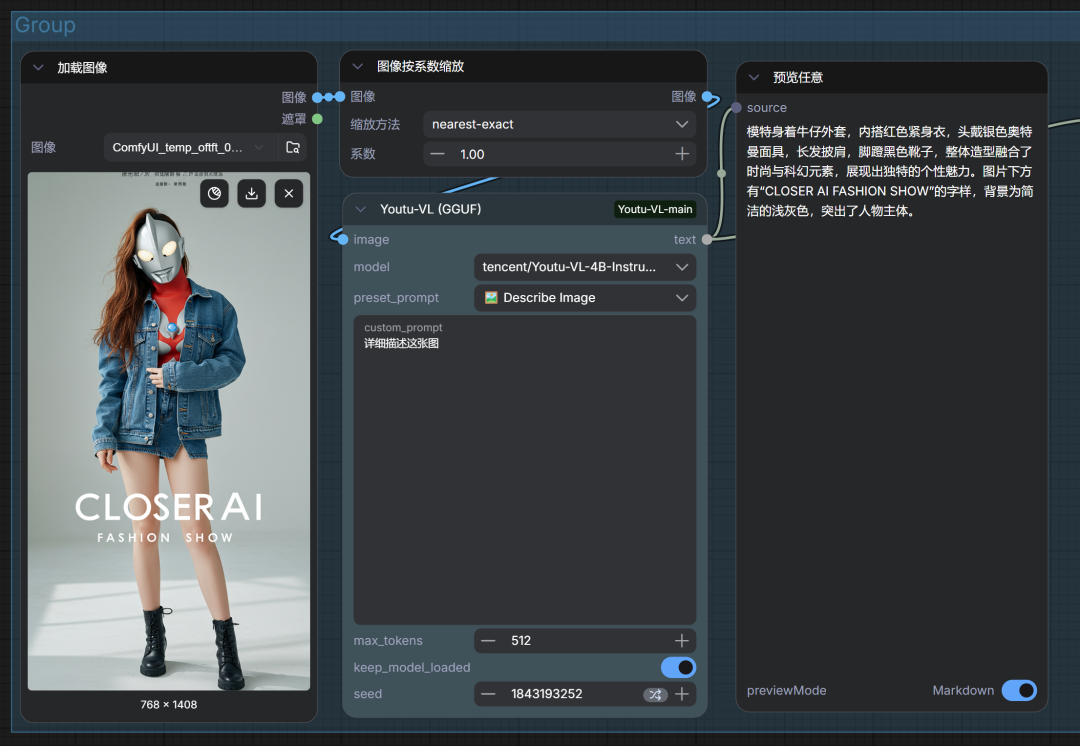
目前节点预设以下功能:
在节点设置中,你可以通过内置的 Preset Modes(预设模式) 快速执行任务:
| 预设模式 | 功能描述 |
|---|---|
| 📝 详细描述 | 生成长段落,涵盖光线、构图及主体细节(适合反推提示词)。 |
| 🏷️ 生成标签 | 创建逗号分隔的标签(Danbooru 风格,适合 LoRA 训练打标)。 |
| 📄 OCR 文本 | 自动读取并提取图像中的可见文字。 |
| 🎨 艺术风格 | 识别并描述作品的媒介、技法和艺术家风格。 |
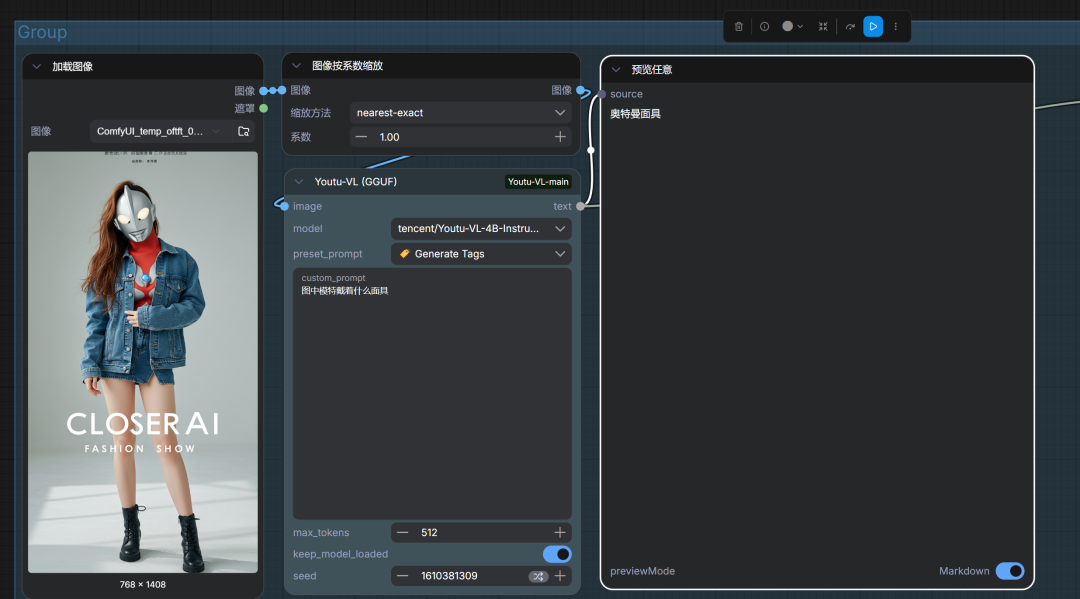
| ❓ 视觉问答 | 通过自定义问题与图片“聊天”(如:问“图中人物穿什么颜色?”)。 |
1)详细描述
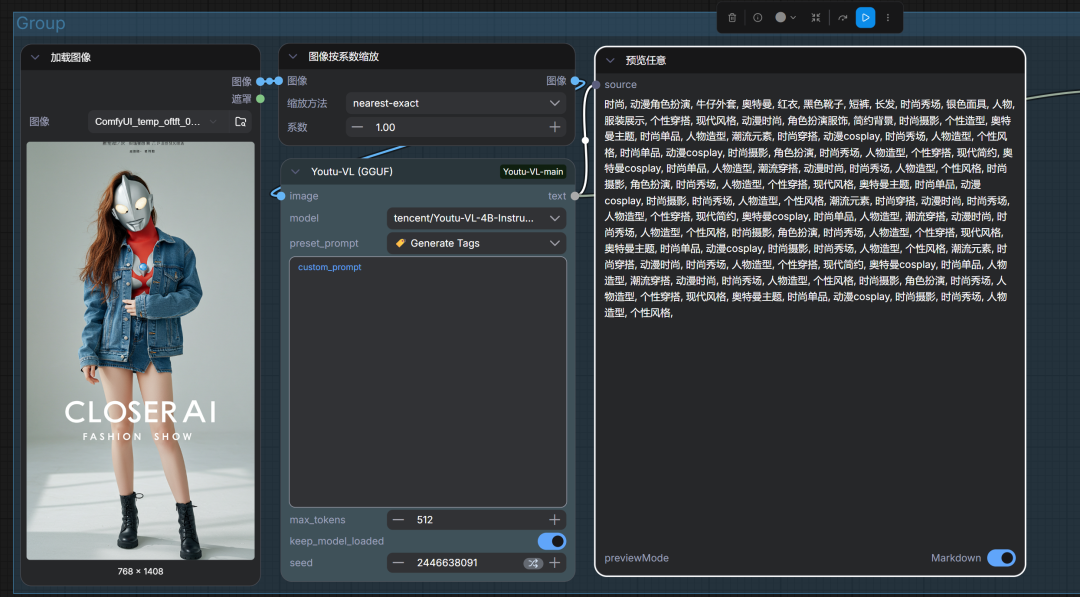
2)生成标签
3)视觉问答
4)OCR文字
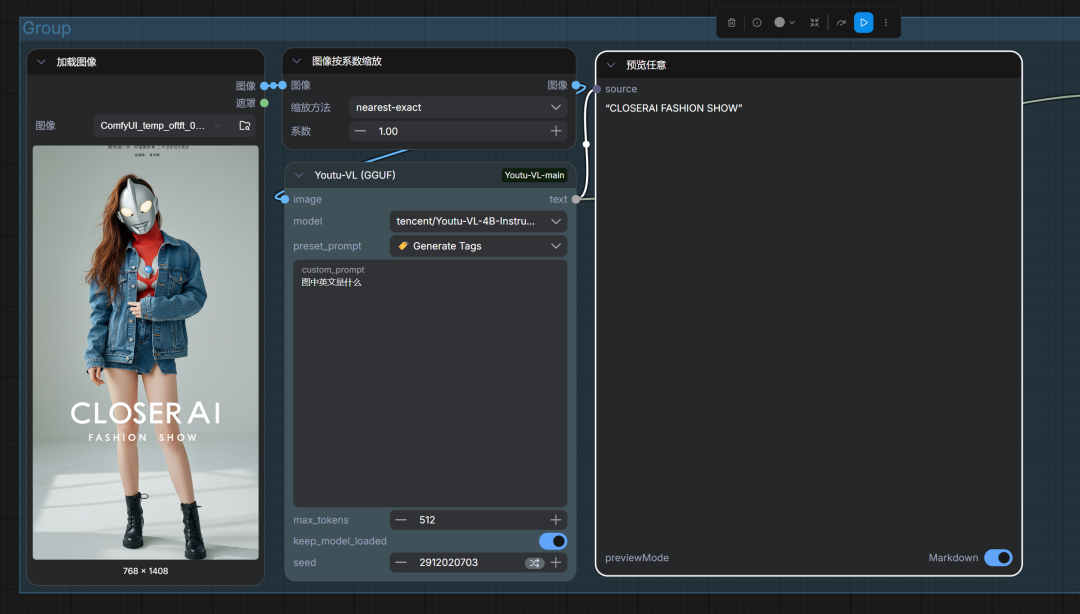
对于本地而言,这是除了qwen3-VL的另一个全能型多模态模型!作为端侧推理模型,在comfyUI中绝对够用且稳定。是一个非常不错的选择!
本地算力不够怎么办?
如果本地设备算力不好的小伙伴,推荐使用线上comfyUI来运行体验:runninghub.cn
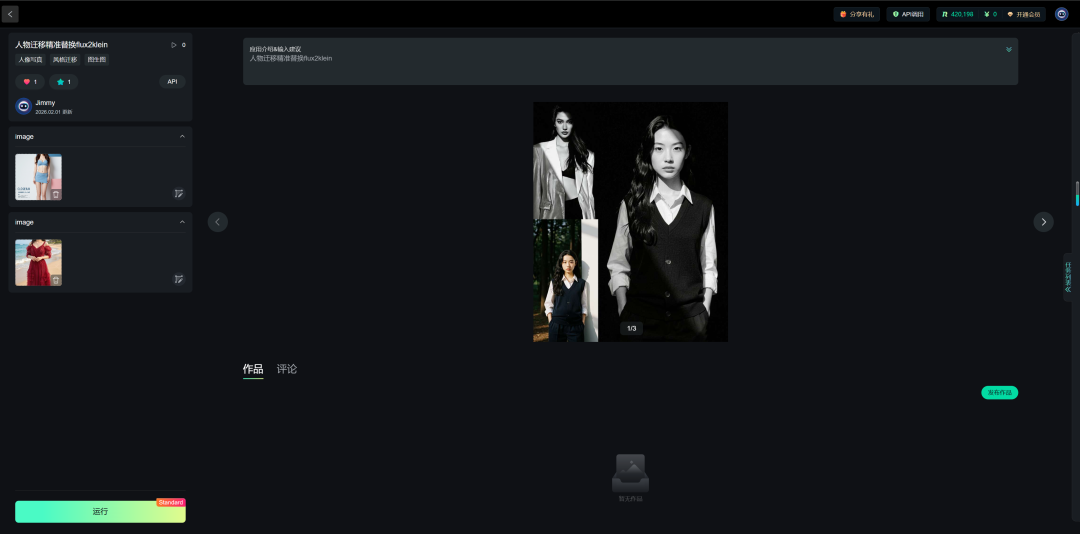
人物迁移精准替换flux2klein应用体验地址:
https://www.runninghub.cn/ai-detail-new/2017945754324705281
注册地址:https://www.runninghub.cn/?utm_source=kol01-RH151
通过这个链接第一次注册送1000点,每日登录送100点
最后几句:
如果对你有帮助,请一键三连支持下我,感谢
CloserAI 3D Pose Editor:http://aigc.douyoubuy.cn/2025/12/03/3448/ closerAI-nanoPrompts: http://closerai.douyoubuy.cn/2025/11/24/3396/ closerAI 分镜设计 软件(exe)本地运行版closerAI 分镜设计 软件(exe)本地运行版 操作说明文档以下是closerAIwater节点:closerAIsorawater Sora 水印移除 ComfyUI 节点分镜分词器节点:closerAI分词器节点说明json结构化提示词 http://aigc.douyoubuy.cn/2025/11/05/3242/
以上是closerAI团队制作的stable diffusion comfyUI closerAI youtu-VL工作流0204的介绍,当然,也可以在我们closerAI会员站上获取(查看原文)。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。
>/ 作者:JimmyMo
更多AI前沿科技资讯,请关注我们:

主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网

评论(0)