
更多AI前沿科技资讯,请关注我们:
closerAI-一个深入探索前沿人工智能与AIGC领域的资讯平台
【closerAI ComfyUI】NanoBanana/flux2klein+Ltx2.3实现AI短剧、视频、动漫、漫剧的内容生产!可本地运行的工作流方案!

大家好,我是Jimmy。
开年至今,AI视频模型特别是闭源模型seedance2.0刮起一阵热潮,大家都在感叹没有开源的事,社区与网络上热烈的讨论众说纷纭,不久的3月,开源界终于有了一个音频同步生成的开源模型LTX2.3,它似乎在告诉我们,开源还在努力地追赶与进步着。无论开源还是闭源的模型,模型的进步,带来的是生产力与生产关系的变化。我们要找到适合企业本身自身情况的生产方式去使用。
而我也走在了探索本地使用开源模型去做内容生产的这条路中。
LTX2.3的分享从8G显存可行性部署方案:【closerAI ComfyUI】“开源天花板”LTX2.3重磅发布:音视频同步、原生 4K!全网最全的comfyUI GGUF低显存方案! 8G 显存也能飞!
到提示词优化对于LTX2.3生成的影响:【closerAI ComfyUI】从平庸到炸裂!结构化提示词大法,让 LTX2.3 生成效果更炸裂!这一招直接让画质翻倍,视频质感拉满!
再到多画面内容生成的尝试:【closerAI ComfyUI】LTX2.3 多画面视频生成创作思路:多分镜多层次打造,提升视频质量与叙事表达张力
也给出了对应的方案。
那,LTX2.3能生产内容吗?能讲好故事吗?
其实之前整理的优秀的LTX2.3内容来看,答案很明显,它能用于生产,并讲好故事,是一个本地化的目前来讲最好的选择。

但你要得到更好的生成内容,硬件设备决定上限,我们是要在有限条件下完成符合自身的内容创作。
下面是我的一个小案例,分享下创作的思路。如果对你有帮助,请一键三连支持下我。
虽然LTX2.3能直接20秒长的内容,但这是高配置玩家的选项。而我的想法是利用图像模型生成一致性的分镜画面,然后用LTX2.3单独生成对应画面的内容。每个画面的内容少于等于5秒。
那在图像生成方面选择开源模型就有flux2klein、qwenEdit2511、redfire等,闭源有NanoBanana等。在效率方面,我更倾向于flux2klein和最强的NanoBanana。
开始,直接先脑补一张图,用图作为故事开端。

这是当时开发closerAI_flow节点时在测试时生成的一张图,非常有意思,所以想拿来制作关于游乐场的视频内容。
直接用LLM设计一个故事大纲。
直接使用Gemini生成:

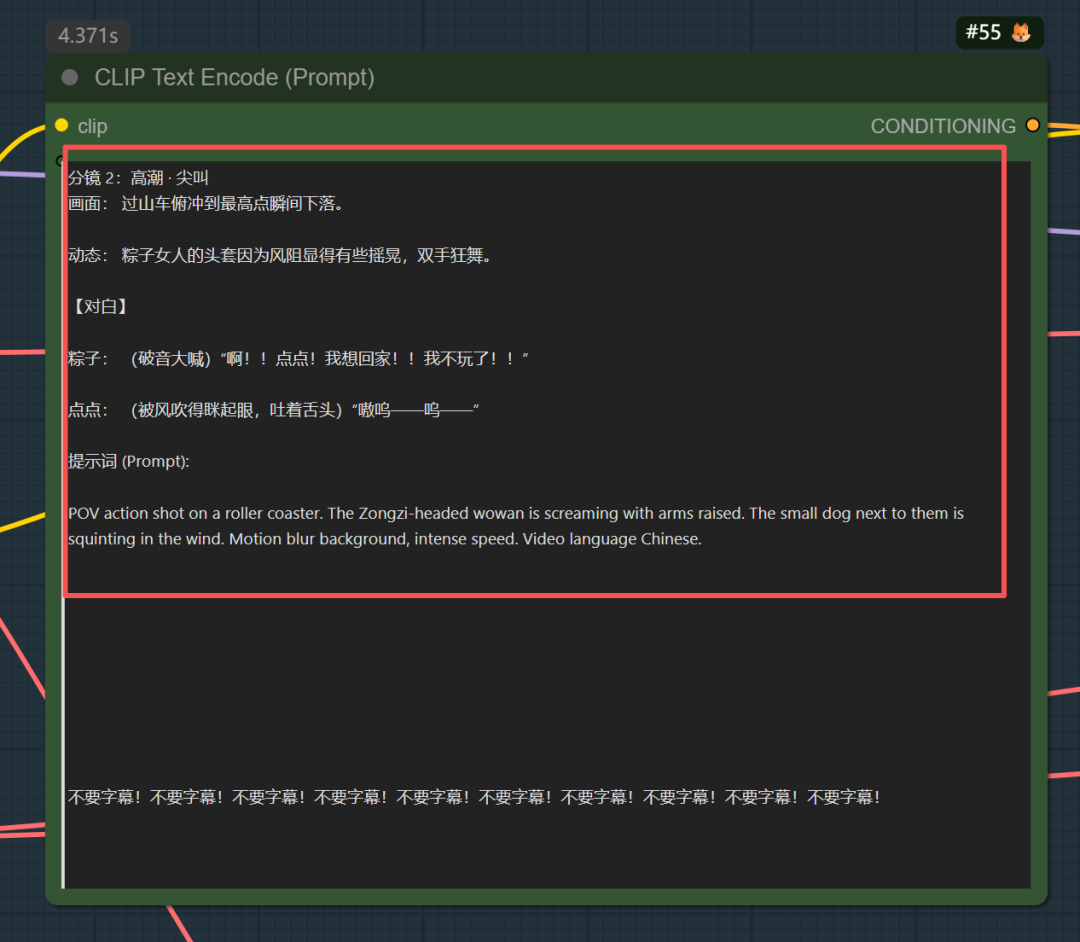
🎬 视频脚本:粽子人的乐园漫游记 角色: 粽子人(简称:粽子)、柯基犬(简称:点点) 📹 分镜详细描述与对白 分镜 1:序幕 · 约定 画面: 阳光穿过树叶。粽子人低头看着点点。 动态: 粽子人拍了拍大腿,点点兴奋地叫了一声。 【对白】 粽子: “点点,说好了,今天不准乱跑,我们就玩最刺激的。” 点点: (汪!汪!) 提示词 (Prompt): A person with a realistic Zongzi head and green vintage outfit sitting on a park bench. They turn to the dog and pat their lap. The dog barks excitedly. In the background, a Ferris wheel. Cinematic sun-drenched lighting. Video language Chinese. 分镜 2:高潮 · 尖叫 画面: 过山车俯冲到最高点瞬间下落。 动态: 粽子人的头套因为风阻显得有些摇晃,双手狂舞。 【对白】 粽子: (破音大喊)“啊!!点点!我想回家!!我不玩了!!” 点点: (被风吹得眯起眼,吐着舌头)“嗷呜——呜——” 提示词 (Prompt): POV action shot on a roller coaster. The Zongzi-headed person is screaming with arms raised. The small dog next to them is squinting in the wind. Motion blur background, intense speed. Video language Chinese. 分镜 3:过渡 · 晚霞 画面: 摩天轮缓慢上升。夕阳把座舱染成橘色。 动态: 粽子人靠在窗边,看着远方,手轻轻抚摸狗狗。 【对白】 粽子: (语气变温柔)“你看,刚才在下面,它们看起来像不像一个个小糯米团子?” 点点: (安静地靠在人腿边,发出满足的呜咽声) 提示词 (Prompt): Inside a Ferris wheel cabin at golden hour. The Zongzi-headed person looks out at the park, stroking the dog. The sun reflects off the glass. Soft, cinematic atmosphere. Video language Chinese. 分镜 4:尾声 · 璀璨 画面: 夜晚。第一束烟花升空炸开。 动态: 两人并排坐着,烟花的光在粽子头套上变幻颜色。 【对白】 点点: (歪头看着天空) 粽子: (轻声说)“点点,端午节快乐。明年,我们还来。” 提示词 (Prompt): Rear view of the Zongzi-headed person and dog on a bench at night. Massive fireworks exploding over a Ferris wheel. Colorful lights illuminating their silhouettes. Video language Chinese. 🛠️ 制作小贴士 声音处理: 粽子人的声音可以带一点点闷,模拟隔着头套说话的效果,这样更有真实感。 后期文字: 您可以考虑在视频下方加上中文字幕,增强叙事感。
然后的话,我是在comfyUI中直接使用closerAI_flow生成对应的分镜
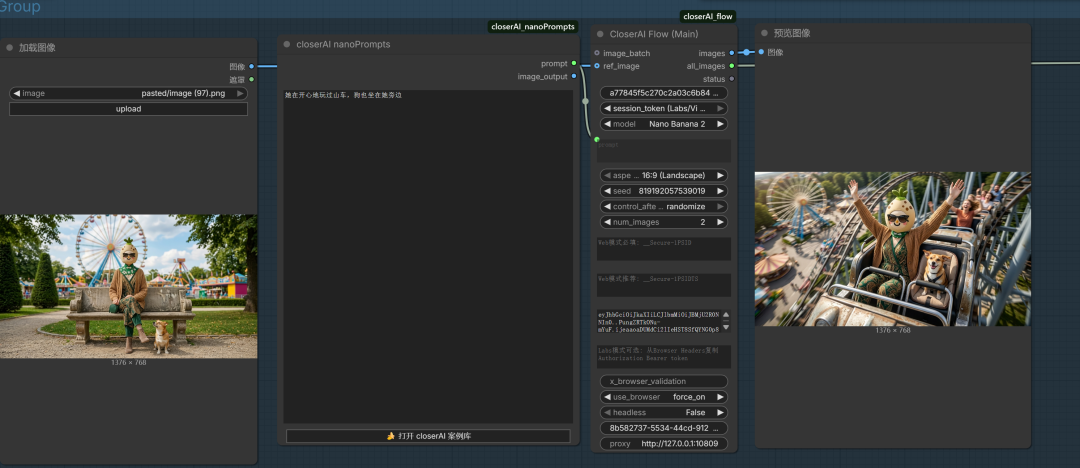
这是闭源产品的生成效果,当然这是最好的。那本地模型呢,使用flux2klein 9B ,当然这里是GGUF版本:
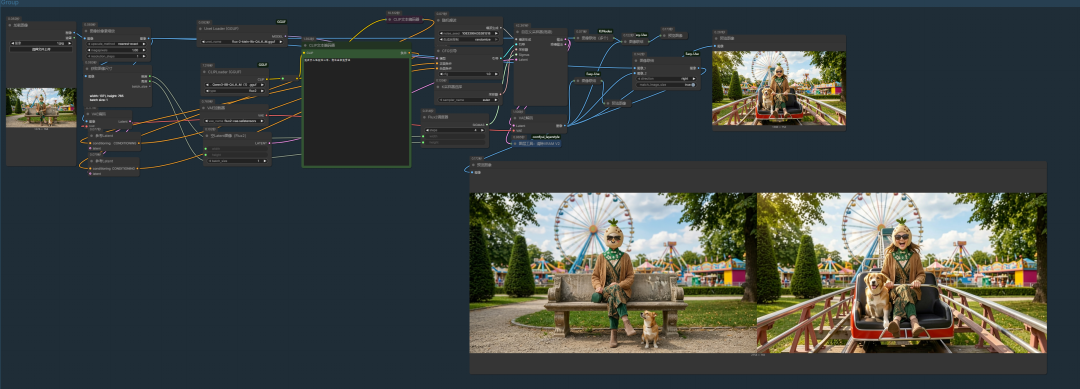
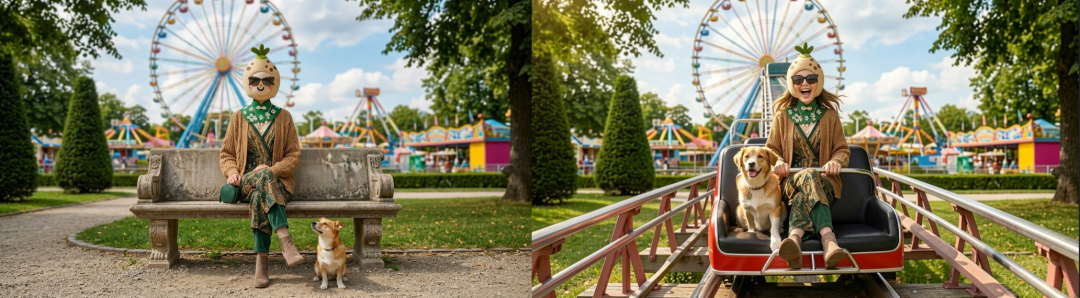
那它的效果当然与NanoBanana是没得比的。
通过这样的方式,生成四张分镜图,最终确定是以下四张:




然后将每个分镜的文生视频的提示词,扔进LTX2.3工作流中进行生成:
将对应分镜的图片与提示词填进去:
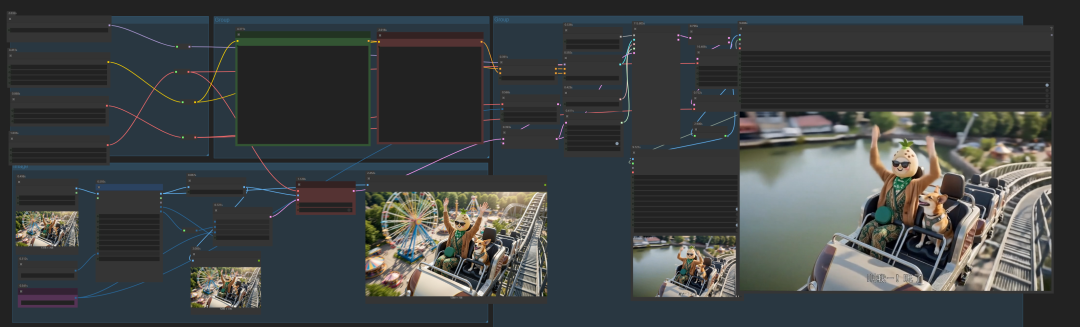
然后将生成的四个视频,扔进剪辑软件拼接,最后形成成品:
在创作过程中,我发现,LTX2.3很稳定地生成,这抽卡概率比闭源产品低。
效果我是很满意的,我也拿grok制作了一个:
然后我发现,LTX2.3真的为开源做了很大努力,模型的能力很强,虽有瑕疵,但闭源也有啊,最重要一点,它都不用钱,最多是花点电费。而我更希望它后面的迭代中,能提高生成效率。昨天看到了一篇论文是关于一个对角蒸馏的技术能让视频在秒级间生成高质量的视频,这十分让人激动:对角蒸馏:实时AI视频!2.61秒生成5秒短片,我也很期待那一天很快会到来!
本地算力不够怎么办?
如果本地设备算力不好的小伙伴,推荐使用线上comfyUI来运行体验:runninghub.cn

LTX2.3图生视频应用体验地址:
https://www.runninghub.cn/ai-detail/2029776111051214850
注册地址:https://www.runninghub.cn/?utm_source=kol01-RH151
通过这个链接第一次注册送1000点,每日登录送100点
最后几句:
如果对你有帮助,请一键三连支持下我,感谢
以上是closerAI团队制作的stable diffusion comfyUI closerAI LTX-2.3 GGUF+提示词优化视频生成工作流(8G可运行版本)0307的介绍,当然,也可以在我们closerAI会员站上获取(查看原文)。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。
>/ 作者:JimmyMo
更多AI前沿科技资讯,请关注我们:
closerAI-一个深入探索前沿人工智能与AIGC领域的资讯平台
主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网

评论(0)