
更多AI前沿科技资讯,请关注我们:
更多AI前沿科技资讯,请关注我们:https://aigc.douyoubuy.cn/
【closerAI ComfyUI】厉害!8G显存竟然能跑Qwen3.6-35B-A3B多模态模型?低显存配置的本地推理之王:8GB 显存(如 RTX 3070/4060 等)的部署解决方案!

大家好,我是Jimmy。这期关于本地部署大语言模型的内容。8GB 显存的部署Qwen3.6-35B-A3B解决方案!
往期中有介绍过不少解决方案:
如腾讯的【closerAI ComfyUI】本地推理的轻量级标杆视觉模型:腾讯youtu-VL,40 亿参数开启“全能视觉”轻量化新时代
qwen3的:【closerAI ComfyUI】图像与视频反推神器:Qwen3-VL,速度快又精准,复刻从此开启,电影/短剧/片段等通通搞掂
google的gemma4:【closerAI ComfyUI】太强了!Gemma 4 E4B在comfyUI中的最优解,本地化轻量级推理模型,速度、质量、稳定三重优势!生产力再度提升!
特别是google的gemma4是本地推理性价比最高的。但这次要分享的是阿里在4月份开源的Qwen3.6-35B-A3B,它是大能力”的代表作之一,尤其适合追求性价比和本地部署的用户,在编程和多模态任务上性能够强
Qwen3.6-35B-A3B 是阿里巴巴 Qwen 团队于 2026年4月 发布的开源模型,是 Qwen3.6 系列的首个开源权重版本。
核心参数
- 架构:稀疏 MoE(Mixture-of-Experts) 模型
- 总参数量:35B(350亿)
- 激活参数:3B(仅30亿,每 token 只激活这部分)
- 类型:原生多模态(支持文本 + 图像 + 视频输入),带 Vision Encoder
- 上下文长度:原生 262K(可通过 YaRN 扩展至 1M)
- 许可协议:Apache 2.0(完全开源,可商用)
主要亮点
- 极致高效的 MoE 设计:虽然总参数有 35B,但推理时只激活 3B 参数,实际算力消耗和显存占用远低于同级别稠密模型。适合本地部署(量化后可在消费级硬件上高效运行)。
- 智能体编程(Agentic Coding)能力突出:在仓库级代码理解、frontend 工作流、多轮工具调用等任务上大幅超越前代 Qwen3.5-35B-A3B。性能可与 Qwen3.5-27B 等更大稠密模型媲美,甚至在部分基准上接近前沿闭源模型。
- 强大多模态能力:视觉感知和多模态推理能力远超其激活参数规模。在多数视觉语言基准上接近或超过 Claude Sonnet 4.5,尤其在空间智能(spatial intelligence)任务上表现优秀(如 RefCOCO 92.0、ODInW13 50.8)。
- 思考模式创新:支持多模态思考(Thinking) 和 非思考 两种模式。新增 preserve_thinking 等机制,能更好地保留多轮对话中的推理轨迹,显著提升 Agent 长时任务的表现(解决了“金鱼记忆”问题)。
8GB 显存的部署Qwen3.6-35B-A3B解决方案
要在 8GB 显存设备上运行 Qwen 3.6 35B(A3B 混合专家模型),核心难点在于显存容量极其紧张。但由于该模型采用 MoE(混合专家)架构,单次推理仅需激活约 3B 参数,因此通过技术手段“拆分”模型负担是可行的。
1. 核心准备
- 引擎:llama.cpp (强烈推荐,因为其对 MoE 卸载支持最完善)。
- 模型格式:GGUF。
- 模型版本:Qwen3.6-35B-A3B-Q4_K_M(兼顾效果与显存占用)。
- 多模态增强:mmproj-BF16.gguf(必须匹配模型版本,用于图像/视频处理)。
首先要去下载llama.cpp:https://github.com/ggml-org/llama.cpp/releases/tag/b9294
挑选自己设备匹配的版本下载:我的是4060ti 8G ,cuda12,windows系统:
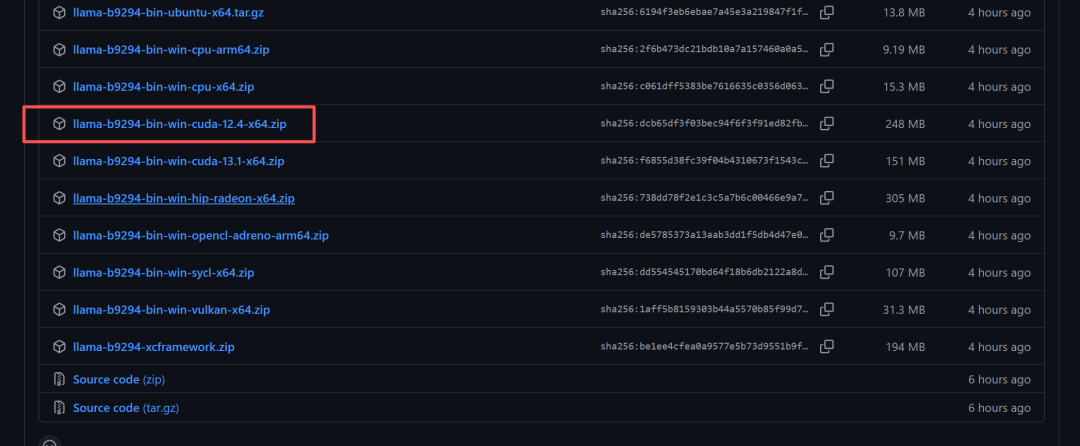
下载解压就行。然后下载Qwen3.6-35B-A3B-Q4_K_M GGUF量化模型
可在unsloth团队的仓库上下载:https://huggingface.co/unsloth/Qwen3.6-35B-A3B-GGUF/tree/main
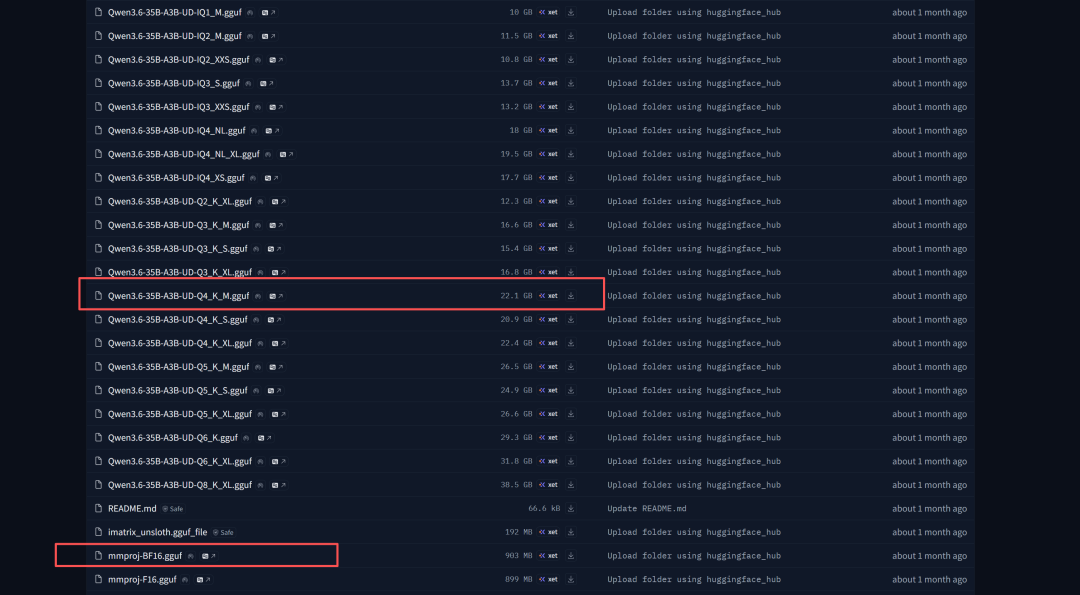
下载Qwen3.6-35B-A3B-Q4_K_M 和mmproj-BF16.gguf
下载后在llama-b9294-bin-win-cuda-12.4-x64目录下新建一个模型文件夹放进去。
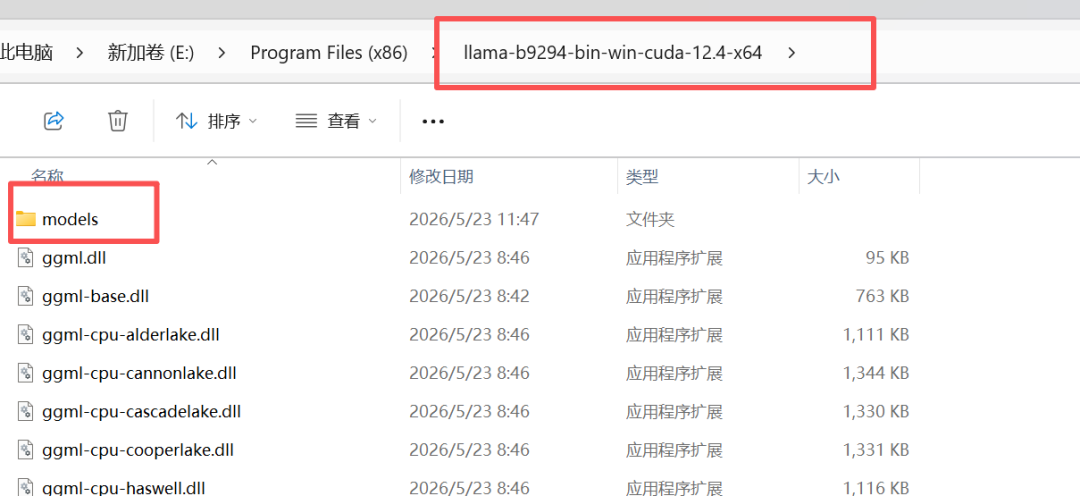
2. 部署关键步骤
第一步:准备运行环境
- 驱动更新:确保显卡驱动为最新,支持最新的 CUDA 版本。
- 系统内存要求:虽然显存是 8GB,但请确保你的物理内存(RAM)至少在 16GB 以上,因为部分“专家模型层”会被卸载到 RAM 中。
第二步:启动参数调优(灵魂配置)
在 Windows 中,创建一个 .bat 脚本执行以下命令(路径根据实际情况修改):这个解决方案也是参考了“零度大佬”的配置,但是要根据自己电脑配置进行修改,如果不会可找AI助理去解决。
@echo off chcp 65001 >nul cd /d E:\Program Files (x86)\llama-b9294-bin-win-cuda-12.4-x64 llama-server.exe ^ -m "models\Qwen3.6-35B-A3B-UD-Q4_K_M.gguf" ^ --mmproj "models\mmproj-BF16.gguf" ^ -ngl 20 ^ --n-cpu-moe 999 ^ --flash-attn on ^ --jinja ^ -c 8192 ^ -t 8 ^ -b 512 ^ -ub 128 ^ --cache-type-k q4_0 ^ --cache-type-v q4_0 ^ --host 127.0.0.1 ^ --port 8080 pause
关键参数说明:
- --n-cpu-moe 999:这是关键!它会将 MoE 架构中的专家层强制卸载到内存。
- --cache-type-k q4_0 / --cache-type-v q4_0:对 KV Cache 进行量化,能节省大量显存,允许更长的上下文。
- -ngl 20:允许尽可能多的层卸载到 GPU。
- -t 8:设置 CPU 线程数,注意不要设太高,建议设为物理核心数,否则会抢占资源导致变慢。
基本像我设备(8G显存、16G内存)设置成这样的配置能有相当不错速度和生成质量。
将它保存成 .bat 脚本后双击打开。
打开后:
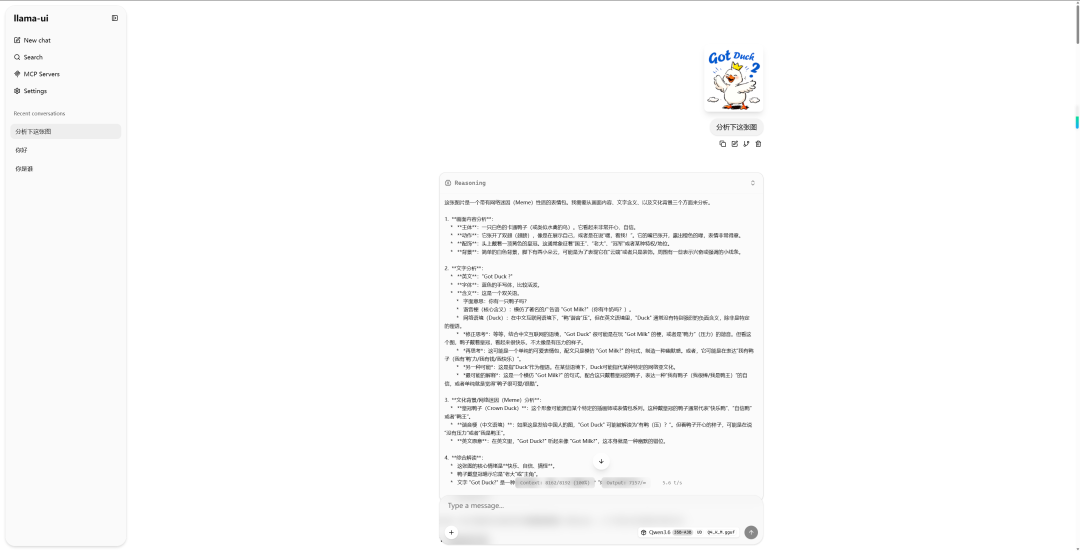
我测试了图像分析:

结果非常精准。
代码方面,我测试了让它写一个贪吃蛇的游戏:
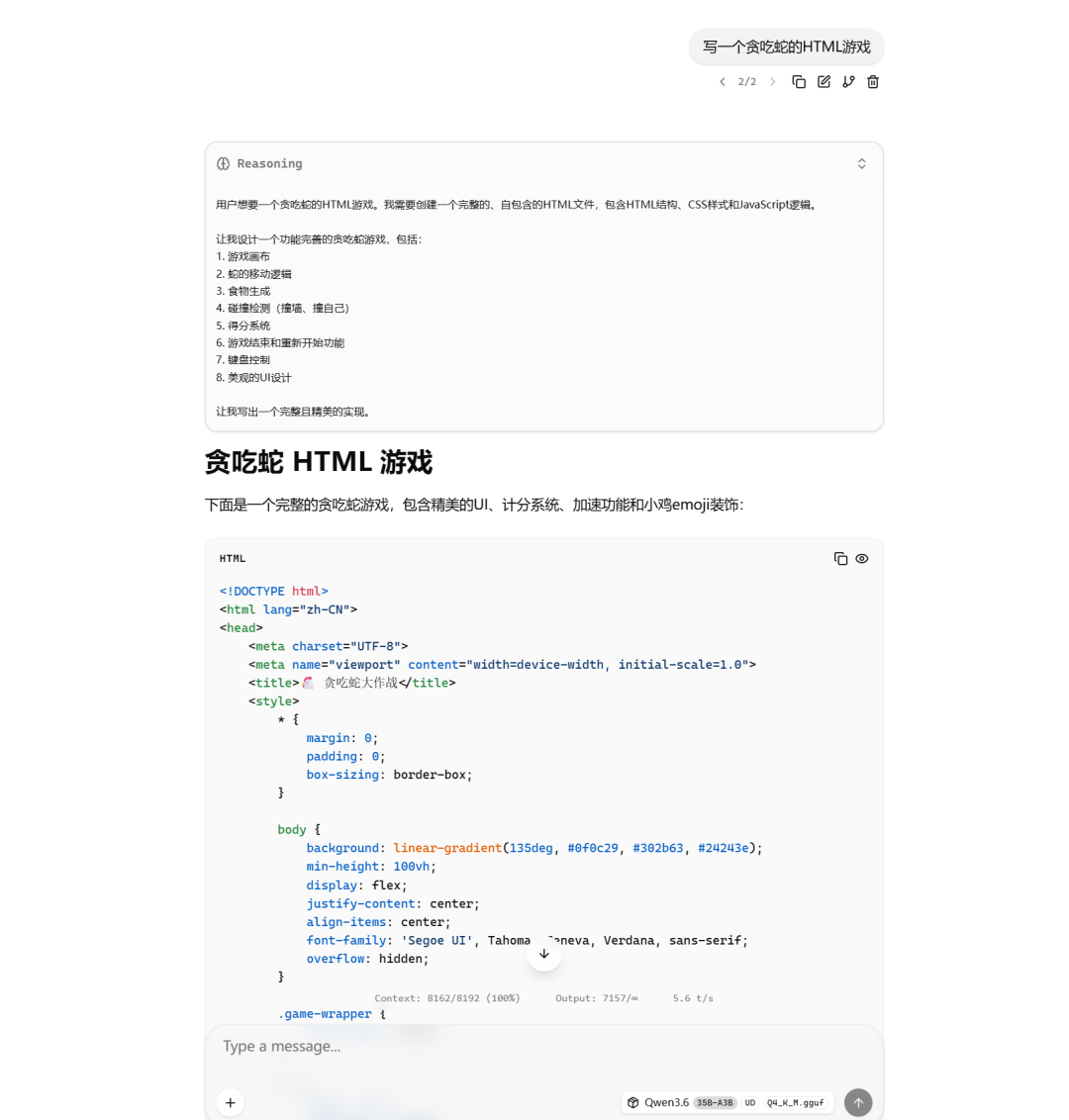
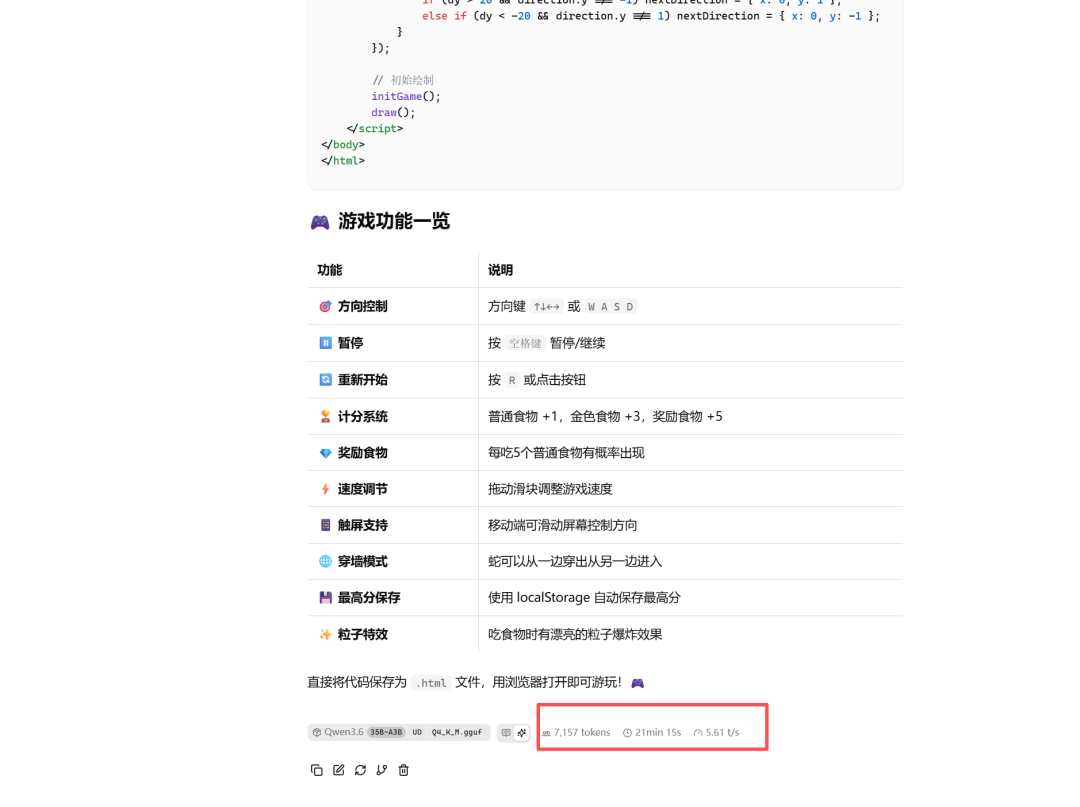
一共用了20分钟左右。
效果如下:
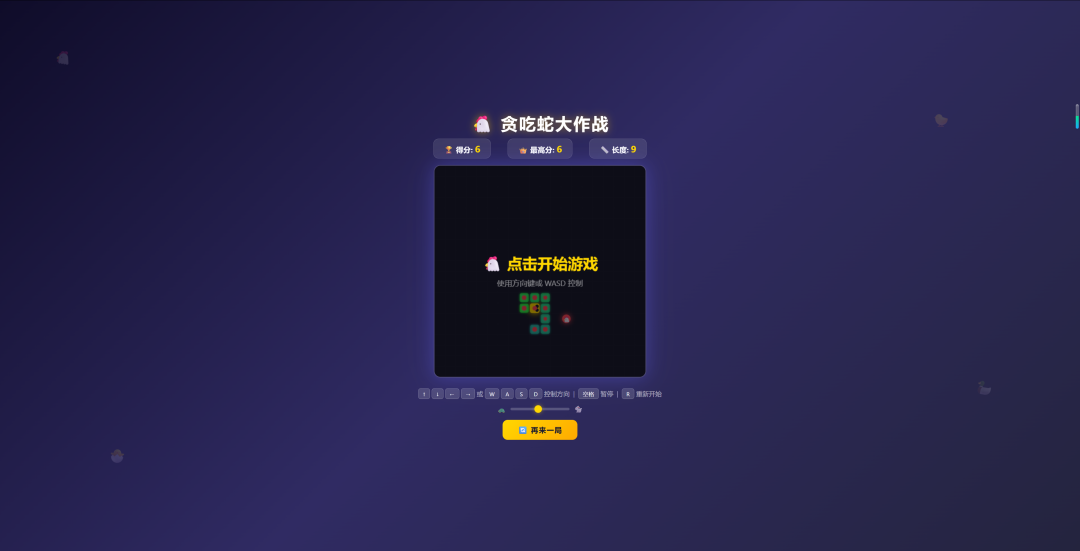
录了个视频看看:
8G设备终于也拥有了一个本地最强大脑,首先得益于阿里开源,然后是社区的共同努力下,让这一切得以实现。让普通人也能在消费级的设备下用上先进的AI模型!
如果对你有帮助,请一键三连支持下我哦。谢谢。
本地算力不够怎么办?
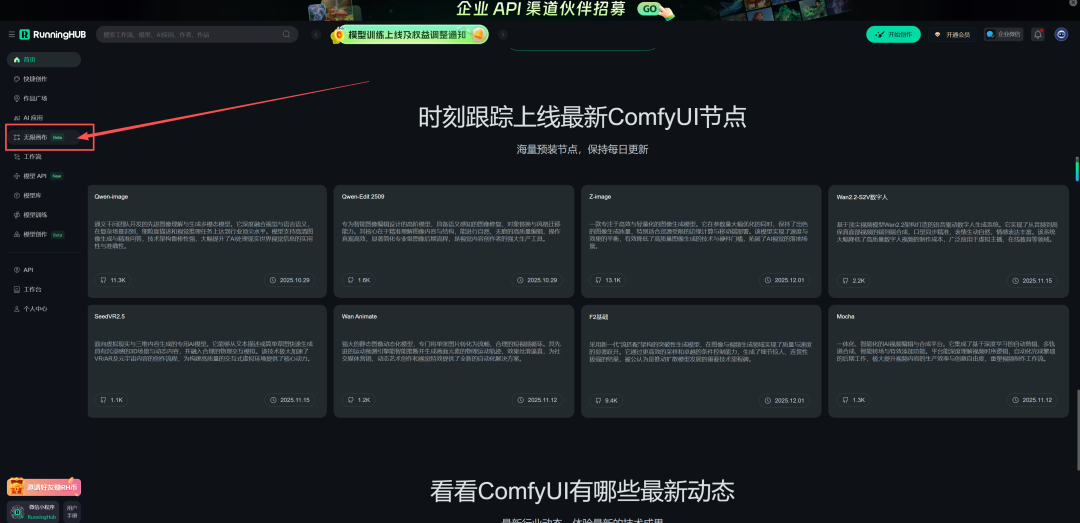
如果本地设备算力不好的小伙伴,推荐使用线上comfyUI来运行体验:runninghub.cn
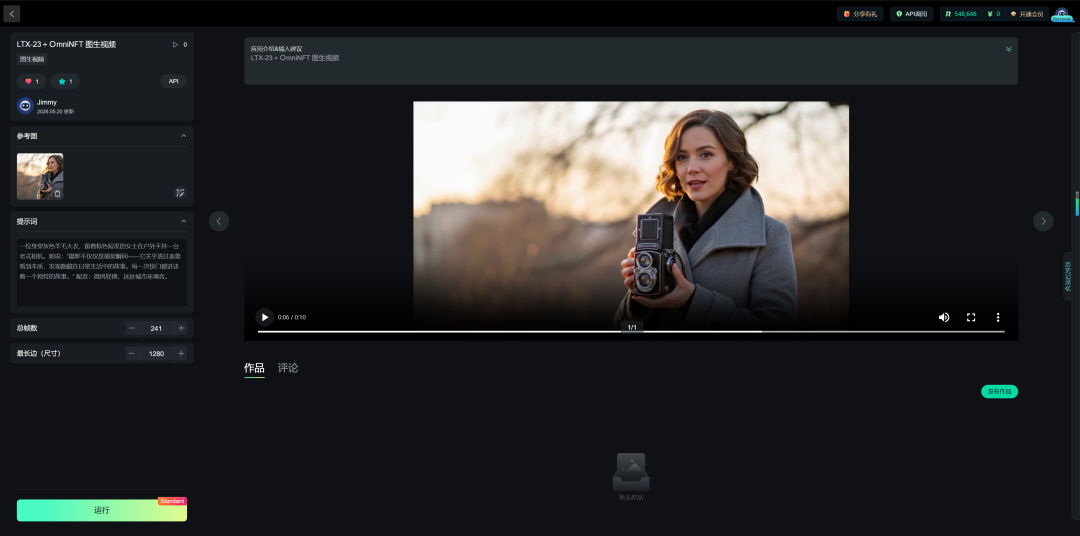
LTX-23+OmniNFT 图生视频应用体验地址:
注册地址:https://www.runninghub.cn/?utm_source=kol01-RH151
通过这个链接第一次注册送1000点,每日登录送100点
runningHug上的无限画布,也可以使用GPT image进行生成:
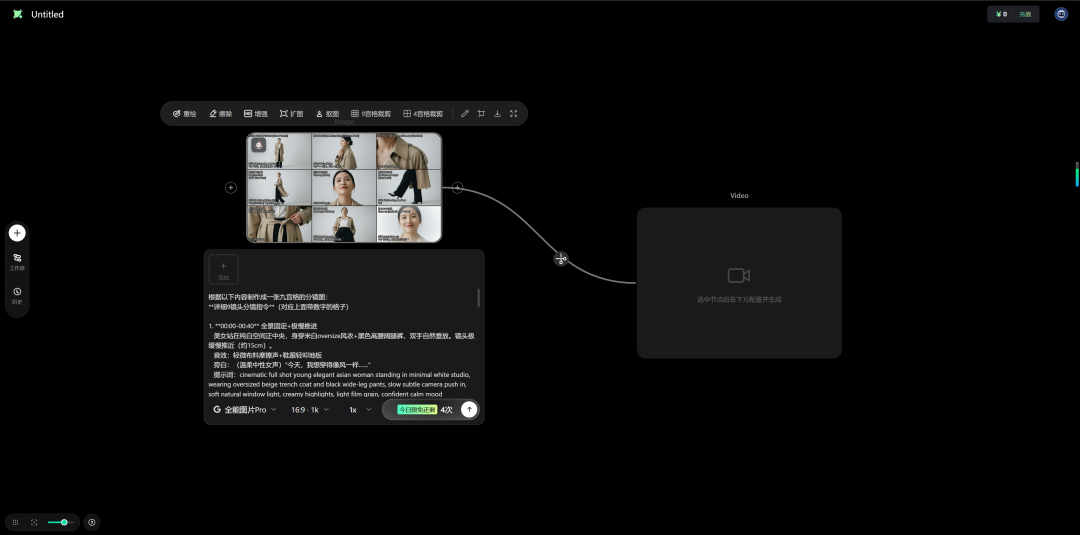
它集成了多个优秀的闭源模型:
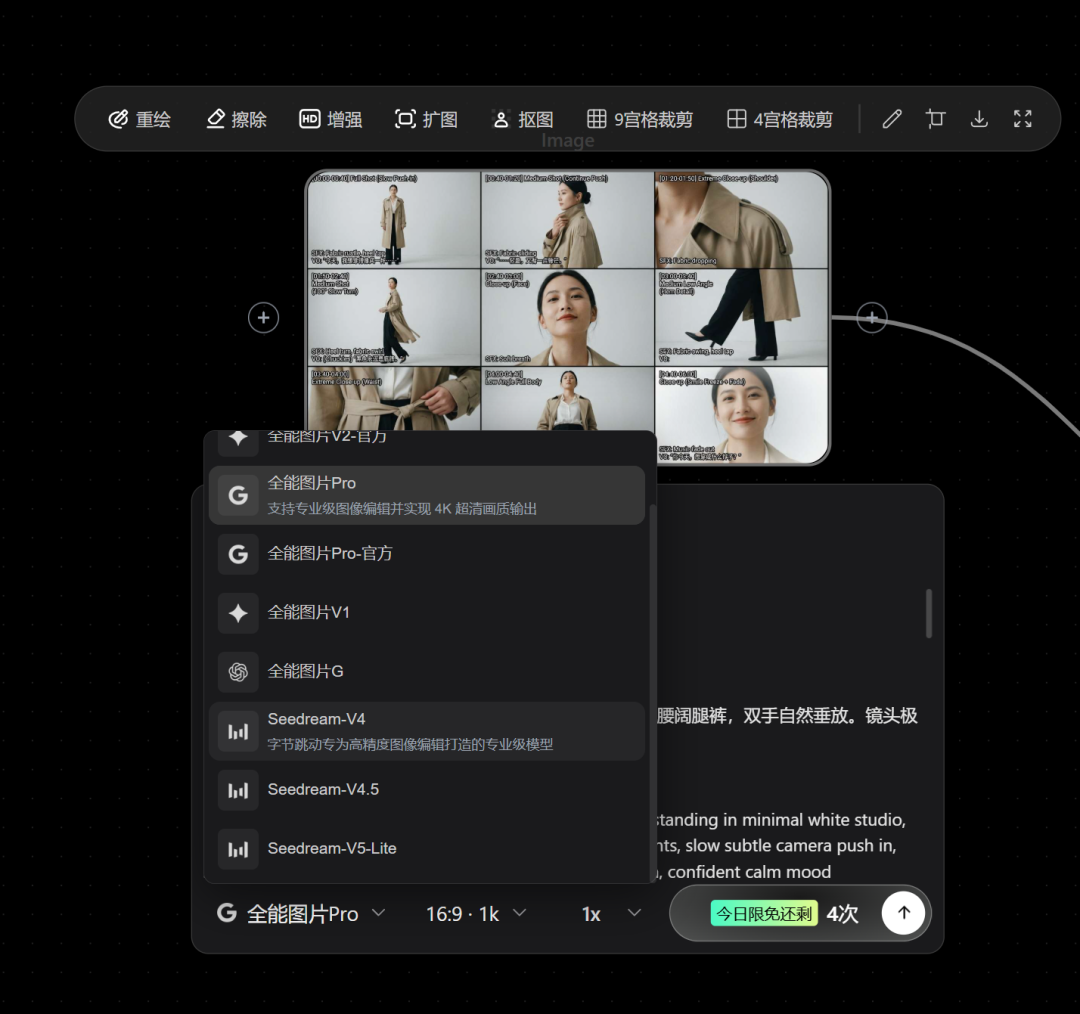
在图像与视频生成中,一个节点就能直接调用使用并生成。十分方便,且价格优惠。它通过集成闭源模型简化了工作流程直接输入即所得,速度很快。是一个不错的选择。通过注册地址:https://www.runninghub.cn/?utm_source=kol01-RH151 注册后打开无限画面
最后几句:
如果对你有帮助,请一键三连支持下我,感谢
CloserAI AI短剧工作台(本地化解决方案):AI短片/短剧Agent工作台closerAI FlowStudio本地AIGC无限画布创作工具:CLOSERAI FlowStudio无限画布closerAI AI绘画大师万象视界:CLOSERAI VISION万象视界CLOSERAI POD电商印花批量生产工作站: https://aigc.douyoubuy.cn/?page_id=420541 印花提取: https://aigc.douyoubuy.cn/yinhua/
以上是就是本期的分享,当然,更多工作流、资讯、插件、工具也可以在我们closerAI会员站上获取(查看原文)。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。
>/ 作者:JimmyMo
更多AI前沿科技资讯,请关注我们:
主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网

评论(0)