


更多AI前沿科技资讯,请关注我们:
closerAI-一个深入探索前沿人工智能与AIGC领域的资讯平台
【closerAI ComfyUI】高质量实时视频生成?Self Forcing:弥合自回归视频扩散模型中训练与测试差距的创新方法,高效高质量的视频生成模型,推荐!

大家好,我是Jimmy。万相视频wan2.1生态再迎来一名强将,在视频生成领域,自回归视频扩散模型一直面临着一个关键挑战:训练与测试过程中的分布不匹配问题。这一问题不仅影响了模型生成视频的质量,还限制了其在实时场景中的应用。如今,Adobe Research 和德克萨斯大学奥斯汀分校的研究团队带来了一项突破性成果 ——Self Forcing,为这一领域带来了新的解决方案。
Self Forcing:弥合自回归视频扩散模型中训练与测试差距的创新方法
项目链接:https://self-forcing.github.io/
1、核心创新:模拟推理过程的训练方法
Self Forcing 的核心创新在于其独特的训练策略。该方法通过在训练过程中模拟推理过程,并结合 KV 缓存技术进行自回归展开,成功解决了传统自回归视频扩散模型中训练与测试分布不匹配的问题。
这种训练方式使得模型在生成视频时能够更准确地捕捉时间序列的动态变化,从而生成更加自然、流畅的视频内容。与传统方法相比,Self Forcing 在保证生成质量的同时,还大幅提升了模型的推理效率,使得在单张消费级显卡上实现实时视频生成成为可能。

生成视频质量
从项目展示的示例来看,Self Forcing 生成的视频内容丰富、细节逼真。无论是陶瓷茶杯向玻璃杯倒水时水流的平滑流动和涟漪效果,还是暴雨中女孩在森林里狂奔的混乱而动态的场景,模型都能精准捕捉到场景中的各种细节和动态变化。
在一个示例中,模型生成了一只白色绵羊弯腰从平静的河流中饮水的场景。绵羊蓬松的羊毛、弯曲的长角和柔软的棕色眼睛都刻画得栩栩如生,河流轻轻流淌,倒映着周围的绿色植被和蓝天,整个画面营造出一种宁静的田园风光。
另一个有趣的示例是一只浣熊弹奏电子吉他的场景。浣熊独特的黑色面部标记和蓬松的尾巴清晰可见,它专注地弹奏着吉他,眼神中流露出喜悦和专注,背景中复古风格的房间和墙上的旧海报为整个场景增添了一种怀旧的氛围。

与其他模型的对比
在与其他先进视频生成模型的对比中,Self Forcing 展现出了明显的优势。与 CausVid 相比,Self Forcing 具有相同的速度,但生成的视频质量更好,没有过饱和的伪影,动作也更加自然。
而与 Wan、SkyReels 和 MAGI 等模型相比,Self Forcing 在延迟方面要快 150-400 倍,同时在视觉质量上达到了相当甚至更优的水平。这使得 Self Forcing 在实时视频生成、视频编辑等对延迟敏感的应用场景中具有巨大的优势。
在comfyUI中的实现与体验
1、模型下载:https://hf-mirror.com/gdhe17/Self-Forcing/tree/main

下载DMD的模型即可。模型放置在comfyui/models/diffusion-models文件夹内。
2、更新KJ wanvedio节点
项目页:https://github.com/kijai/ComfyUI-WanVideoWrapper
3、重启comfyUI
Self-Forcing模型是一个基于wan2.1的文生视频模型。它是一个1.3B T2V模型,它可以与Vace模块一起用于额外的输入。同时它是一个低步骤的模型,所以它的速度快,可能比使用Causvid lora(在1. 3 b模型上)更快,需要使用LCM采样器
工作流使用VACE工作流,模型加载self-forcing,外接一个1.3B T2V模型
如下图示:
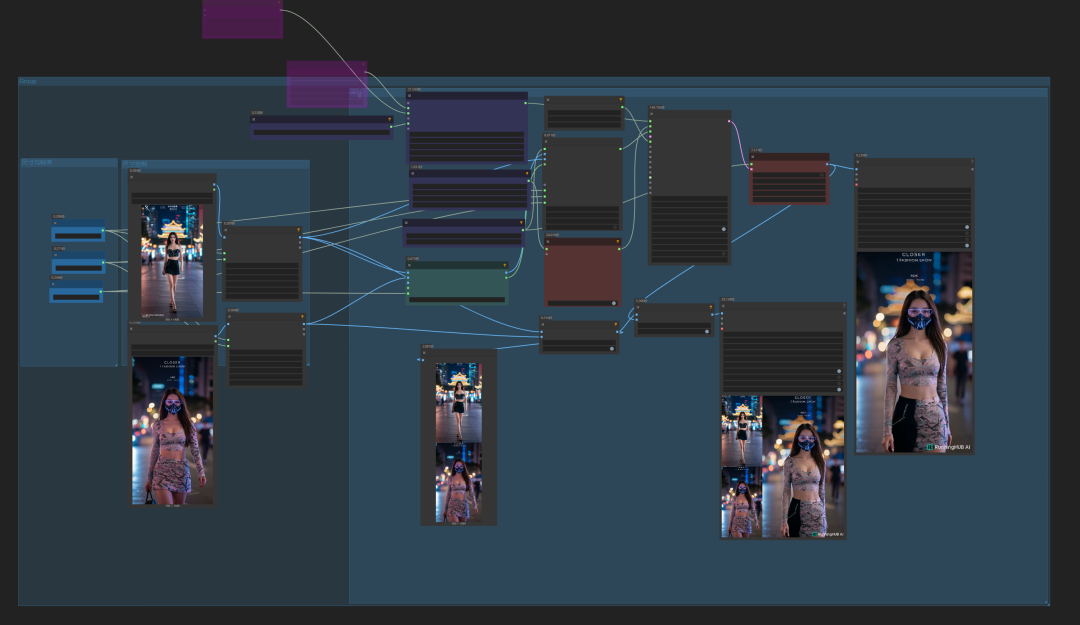
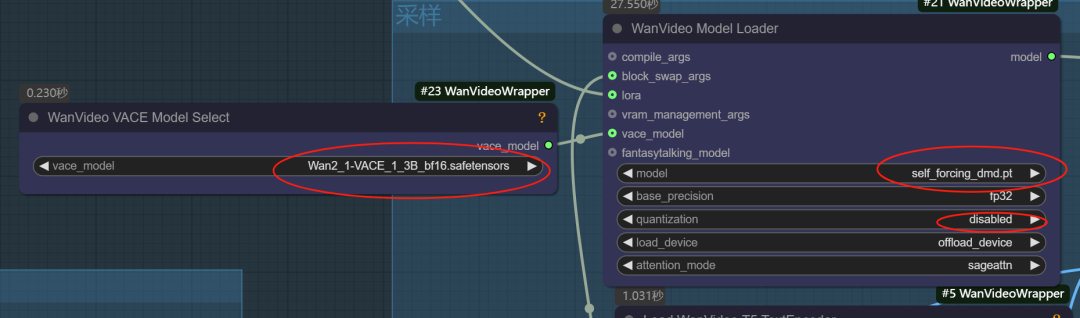
主要加载如上图示。
这里我们搭建的是VACE的首尾帧工作流:
输入首尾两张图:
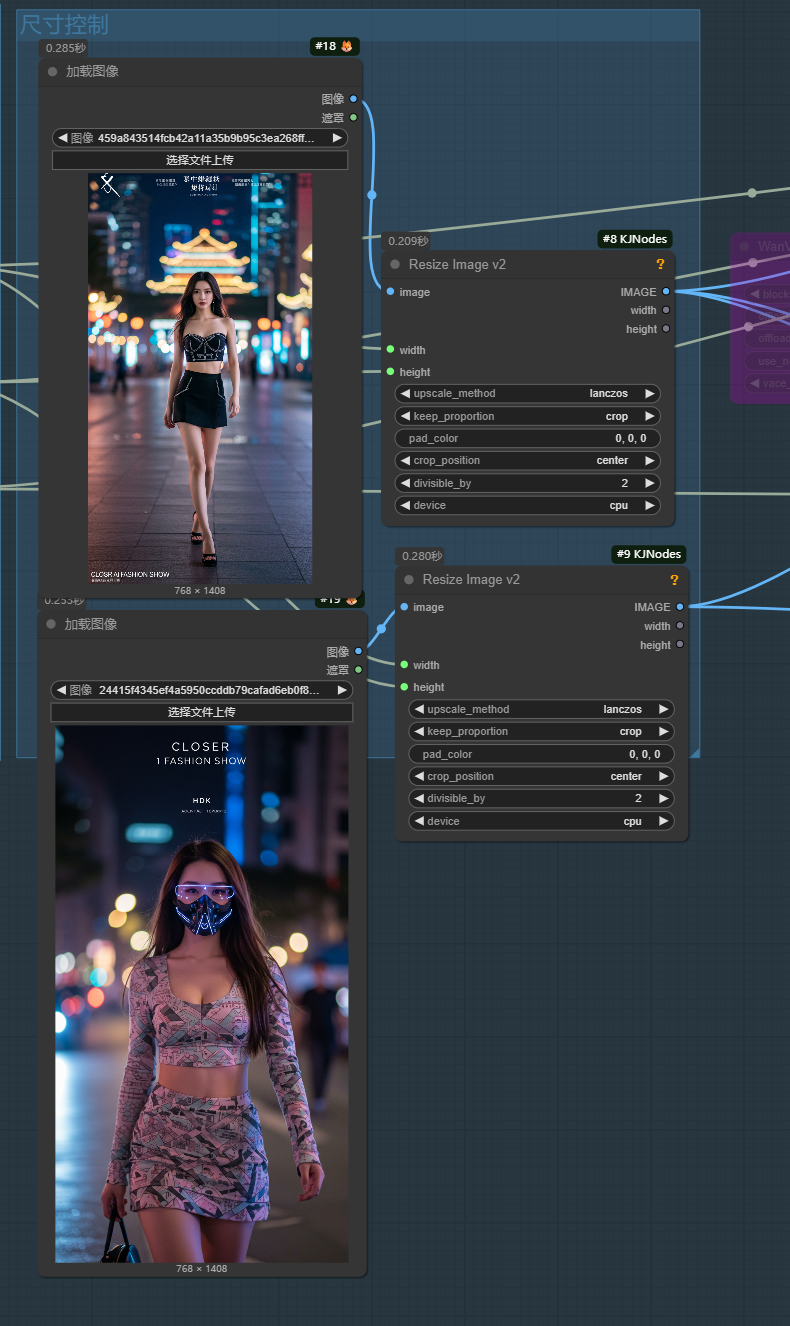
调整尺寸和帧率:
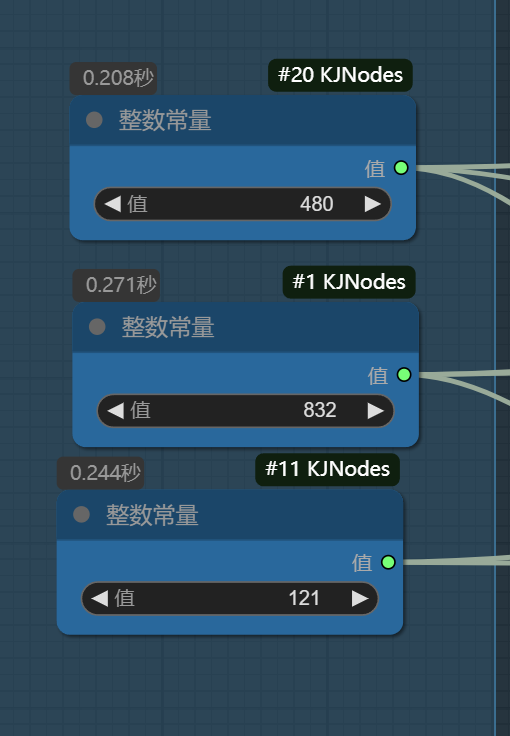
采样器设置如下:
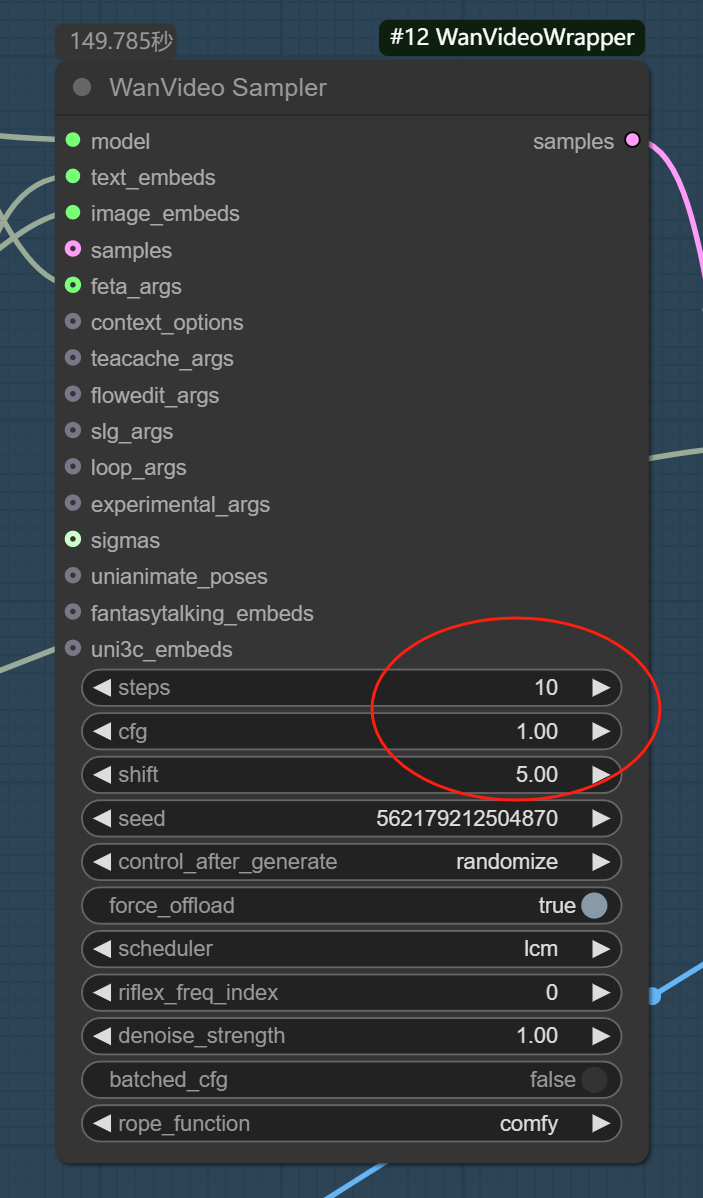
步数是建议4~10,都可以啦。自己尝试。
直接执行即可。
以下是测试结果:
本地算力不够怎么办?
如果本地设备算力不好的小伙伴,推荐使用线上comfyUI来运行体验:runninghub.cn
runninghub.cn self forcing+VACE图生视频(稳且快)体验地址:
https://www.runninghub.cn/ai-detail/1932648363076505601
注册地址:https://www.runninghub.cn/?utm_source=kol01-RH151
通过这个链接第一次注册送1000点,每日登录送100点
最后几句:
Self Forcing 的出现为自回归视频扩散模型的发展开辟了新的道路。它不仅解决了长期以来困扰该领域的训练与测试分布不匹配问题,还在保证生成质量的同时实现了实时视频生成,使得高质量视频生成不再依赖昂贵的硬件设备。
随着技术的不断进步和完善,Self Forcing 有望在视频制作、虚拟现实、实时通信等领域发挥重要作用,为用户带来更加便捷、高效的视频生成体验。相信在不久的将来,这一技术将进一步推动视频生成领域的发展,开启实时视频生成的新篇章。
以上是Self Forcing项目介绍、安装与体验过程。以及closerAI团队制作的stable diffusion comfyUI closerAI搭建的closerAI Self Forcing+VACE图生视频工作流介绍,大家可以根据工作流思路进行尝试搭建。
当然,也可以在我们closerAI会员站上获取对应的工作流(查看原文)。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。
>/ 作者:JimmyMo
更多AI前沿科技资讯,请关注我们:
closerAI-一个深入探索前沿人工智能与AIGC领域的资讯平台

主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网

评论(2)
大佬你能把使用的图片提供给我们吗,有的时候用自己的图片效果不太满意
这个拿图片去反推下提示词就行了啊。