
DeepSeek_V4.pdf:https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
一、核心架构创新:为百万级上下文而生的效率重构
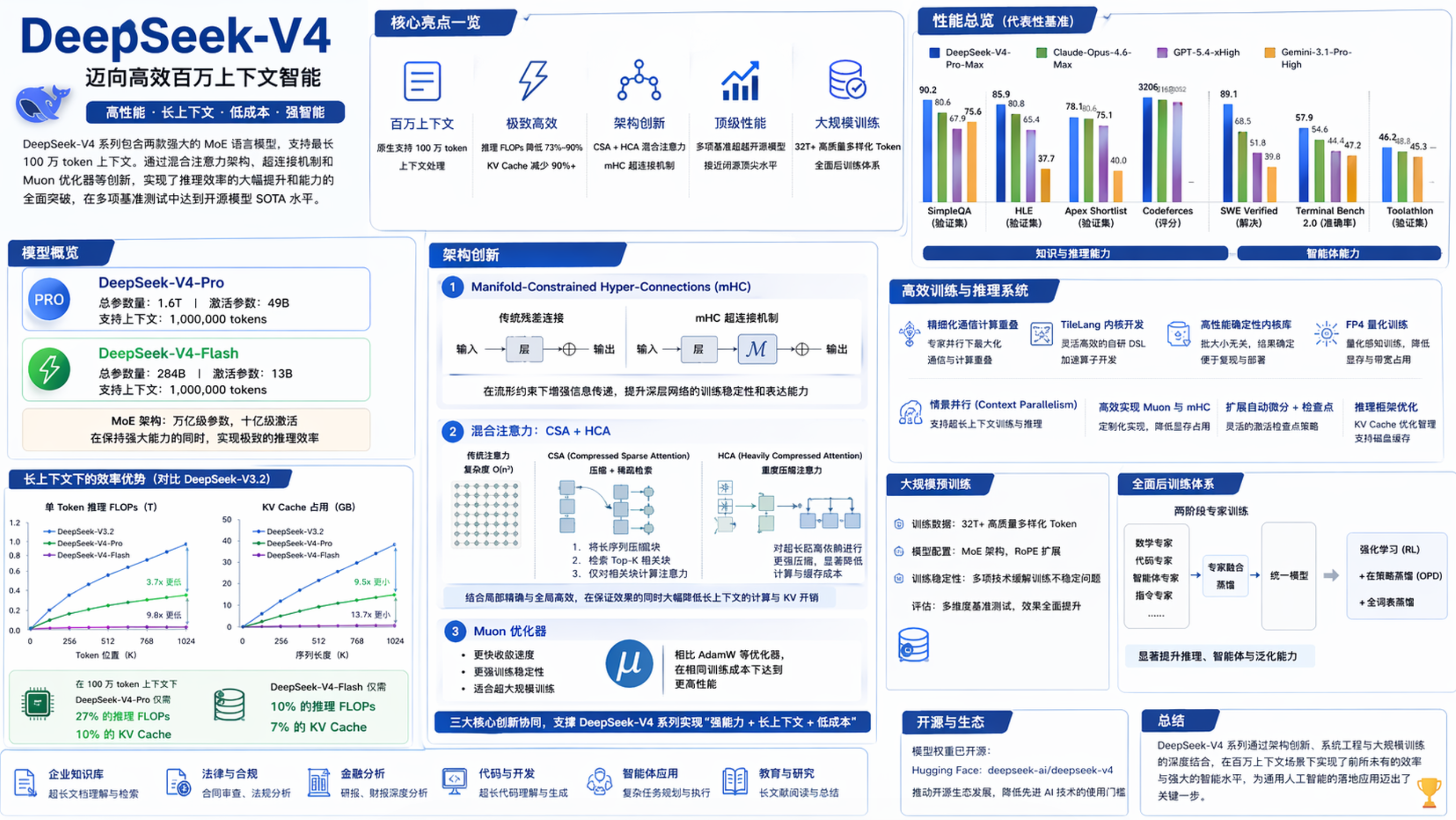
V4并非V3的简单升级,而是一次以长上下文效率为核心的架构重塑。其MoE和MTP骨架虽延续自V3,但注意力机制和残差连接被彻底重构。
1. 混合注意力机制:CSA + HCA
这是V4效率跃升的核心引擎。报告指出,在1M上下文时,V4-Pro的推理FLOPs仅为V3.2的27%,KV缓存仅为其10%,这主要归功于此设计。
- CSA(压缩稀疏注意力):
- 两级加速:先将每
m个token的KV缓存压缩为1个条目(序列长度变1/m),再通过稀疏注意力让每个查询token只关注Top-k个压缩条目。 - 重叠压缩与Lightning Indexer:压缩时利用了相邻块的重叠(
C^b与C^a重叠),保留了跨块信息。而Lightning Indexer以极低计算成本(低秩分解+FP4计算)快速筛选Top-k条目,大幅减少核心注意力的计算量。 - 共享KV MQA与分组输出投影:压缩条目同时作为Key和Value,结合分组投影,进一步压缩了KV缓存和计算。
- 两级加速:先将每
- HCA(重度压缩注意力):
- 极致压缩:采用比CSA大得多的压缩率
m'(m' >> m),将长序列压缩为极少条目,执行稠密注意力。适合对全局信息敏感、但无需细粒度局部交互的层。
- 极致压缩:采用比CSA大得多的压缩率
- 关键辅助设计:
- 滑动窗口分支:为CSA和HCA增加了一个独立的滑动窗口注意力分支(
n_win=128),弥补了压缩导致的局部细粒度信息丢失。 - 注意力汇(Attention Sink):引入可学习的汇token,允许注意力头将部分“注意力”释放到“虚空”中,使模型能灵活调整总注意力权重,提升数值稳定性。
- 滑动窗口分支:为CSA和HCA增加了一个独立的滑动窗口注意力分支(
2. 流形约束超连接(mHC)
代替了传统的残差连接,提升了万亿参数规模下的训练稳定性。
- 核心思想:将残差流扩展为
n_hc维,并用约束在双随机矩阵流形(Birkhoff polytope)上的矩阵B_l进行变换。 - 价值:双随机矩阵的谱范数≤1,保证了信号在前向和反向传播中非扩张,从根本上防止梯度爆炸/消失。这在堆叠大量层时的稳定性优势远超普通残差连接。
- 动态参数化:mHC的
A_l, B_l, C_l矩阵由输入动态生成(依赖RMSNorm和线性投影),并用Sigmoid和Sinkhorn-Knopp算法施加非负和双随机约束。
3. Muon优化器
- V4全面采用Muon优化器(除嵌入层、预测头、RMSNorm等用AdamW外)。
- 关键点:Muon通过Newton-Schulz迭代对梯度矩阵进行正交化来更新参数,这与mHC约束矩阵的“非扩张性”在数学上相呼应,共同稳固了训练信号。
- 混合NS迭代:前8步用激进系数快速逼近,后2步用保守系数稳定在精确值。这种两步策略兼顾了速度和精度。
二、训练稳定性:直面万亿参数模型的工程挑战
报告坦诚地讨论了训练中遇到的“尖峰”(Loss Spike)问题,并提出了两种实用对策,没有完全的理论解释,但分享出来供社区探索。
- 尖峰根源:经验性地定位在MoE层的异常值上,且路由机制被认为加剧了这种现象,形成了“恶性循环”。
- 应对策略1:预见性路由(Anticipatory Routing)
- 做法:在当前步
t,使用t-Δt时刻的历史参数来计算路由索引,解耦了骨干网络和路由网络的同步更新。 - 工程优化:为减少开销,系统提前预取数据并预计算路由索引。仅当检测到尖峰时才动态激活此模式,之后恢复常规训练,从而将额外成本降至最低。
- 做法:在当前步
- 应对策略2:SwiGLU钳制(Clamping)
- 做法:将SwiGLU激活函数的线性部分限制在
[-10, 10],门控部分上限定为10。 - 效果:直接、暴力地消除了异常值,有效稳定了训练,且未损伤模型性能。
- 做法:将SwiGLU激活函数的线性部分限制在
三、基础设施:软硬件协同的极致压榨
V4的高效不仅是算法设计,更依赖从底层算子到分布式框架的全栈优化。
- 细粒度通信计算重叠(MegaMoE内核):将MoE层的专家并行(EP)通信与计算融合为流水线。通过将专家切分为多个波次(Wave),实现了当前波次计算、下一波次传输、已完成波次结果发送的并发,理论上能容忍更低的互联带宽。已开源CUDA实现。
- TileLang与精度保证:为快速开发数百个融合算子,采用了领域特定语言TileLang,实现了高性能与开发效率的平衡。通过自动微分扩展实现张量级检查点,以极低成本进行激活重计算。同时,构建了保证批次不变性和确定性的高性能内核库,这对调试、一致性至关重要。
- FP4量化感知训练(QAT):激进地将MoE专家权重和CSA索引器的QK路径量化为FP4。并发现无损FP4到FP8的解量化技巧,可无缝复用现有FP8框架。
四、后训练:从专家融合到代理能力
V4的后训练流程有两大核心变化:用On-Policy Distillation (OPD) 替代了混合强化学习,并深化了专家专精训练。
- 专家训练与融合:
- 独立专精:针对数学、编程、代理等不同领域,独立训练出多个专家模型。
- OPD(On-Policy Distillation)融合:通过让学生模型(最终V4模型)在自己生成的轨迹上,最小化与多个教师模型(领域专家)的反向KL散度,将能力整合进一个模型。相比权重平均或混合RL,这种方法能更平滑地融合多领域专长。
- 推理努力模式:定义了Non-think、Think High、Think Max三种模式,通过RL时施加不同的长度惩罚和上下文窗口来控制。
- 代理能力强化:
- 交错思考(Interleaved Thinking):在工具调用场景下,跨用户轮次保留完整的推理轨迹,避免状态重置,有效支持了超长步数的复杂代理任务。
- DSec沙盒平台:为支持百万级并发的代理训练与评估,构建了支持容器、微虚拟机等多种隔离级别的弹性沙盒平台。
- 生成式奖励模型(GRM):对于开放式任务,直接使用带评语训练的生成模型来评价,避免了训练独立标量奖励模型的成本。
- 快速指令(Quick Instruction):在输入序列后追加特殊token,在已计算的KV缓存上零成本并行执行搜索触发、意图识别等辅助任务,极大地降低了首token延迟。
总结:V4的技术哲学
DeepSeek-V4的技术拆解揭示了一条清晰路径:它不是通过暴力扩展参数来获取能力,而是通过架构的深度创新(CSA/HCA、mHC)和工程上的极致优化(MegaMoE、FP4 QAT、OPD),在国产AI芯片的能效边界内,重新定义了长上下文模型的经济性与可能性。 其坦诚分享训练不稳定等难题的做法,也体现了开源先锋的责任感。
主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。

评论(0)