
更多AI前沿科技资讯,请关注我们:closerAI-一个深入探索前沿人工智能与AIGC领域的资讯平台
【closerAI ComfyUI】必须又要点赞!百度ERNIE开源音画同步生成模型!一个高质量、专注同步的联合音视频生成方案!开源界视频生成模型又添一员!赞!

大家好,我是Jimmy。这应该是国内开年以来在视频生成方面的又一重大消息。
百度ERNIE团队在四月份时,在图像生成方面带来了惊喜:【closerAI ComfyUI】是很强!这波要给满分!百度 ERNIE-Image生成模型为消费级显卡打造!速度与质量的权衡产物!掂!
一直在期待它的图像编辑模型的权重发布,但这次等来的不是它。而是在这两天开源的NAVA音视频模型:面向下一代的音视频生成框架!一个高质量、专注同步的联合音视频生成方案!
NAVA:音视频同步生成模型
NAVA(Native Audio-Visual Alignment)作为百度 ERNIE 团队 2026 年发布的面向下一代的音视频生成框架,其核心价值在于通过架构创新,打破了传统音视频生成中“音画不同步”与“控制力不足”的技术瓶颈。
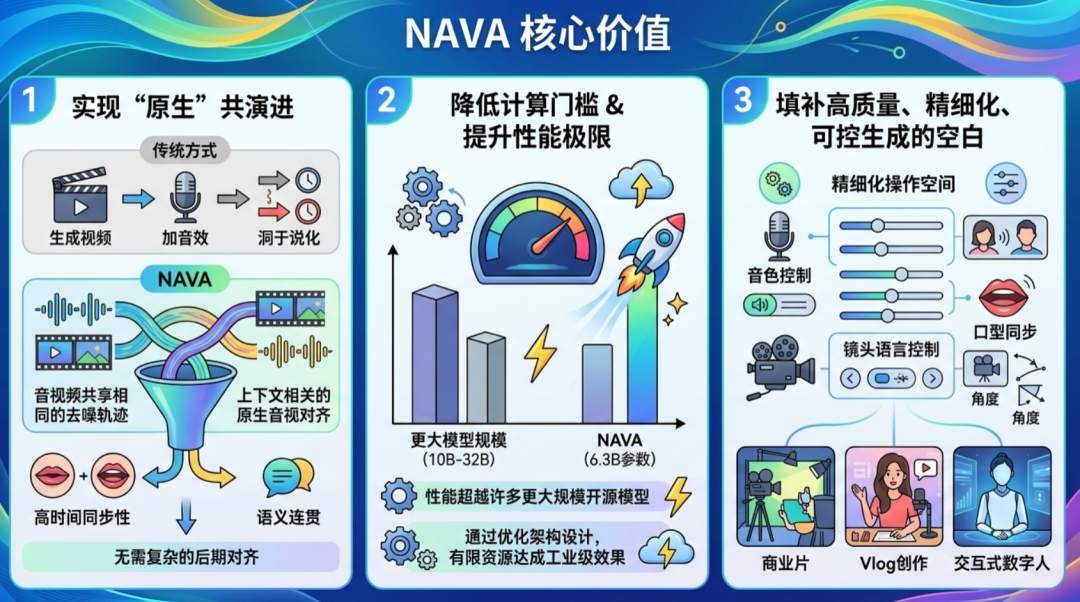
一、 核心价值:为什么它重要?
- 实现“原生”协同演化传统的音视频生成往往是“先生成视频,再配音”或“多塔架构分别生成再对齐”,这会导致音画节奏不匹配、口型与音频不一致。NAVA 将生成定义为“上下文相关的原生音视频对齐”,让音频和视频共享同一条去噪轨迹,在底层逻辑上实现了高度的时间同步与语义连贯,无需复杂的后期对齐。
- 降低算力门槛,提升性能上限在参数量仅为 63 亿(6.3B)的情况下,NAVA 展现出了超越众多更大参数规模(如 10B-32B)开源模型的性能表现。这证明了通过优化的架构设计,可以在有限的资源下实现工业级的生成效果。
- 填补了高质量、精细化可控生成的空白它不仅仅是生成一段视频,而是提供了包括“音色控制”、“口型匹配”、“镜头语言控制”在内的一整套精细化操作空间。这意味着它具备了商用电影、Vlog 创作、交互式数字人等场景的应用潜力。
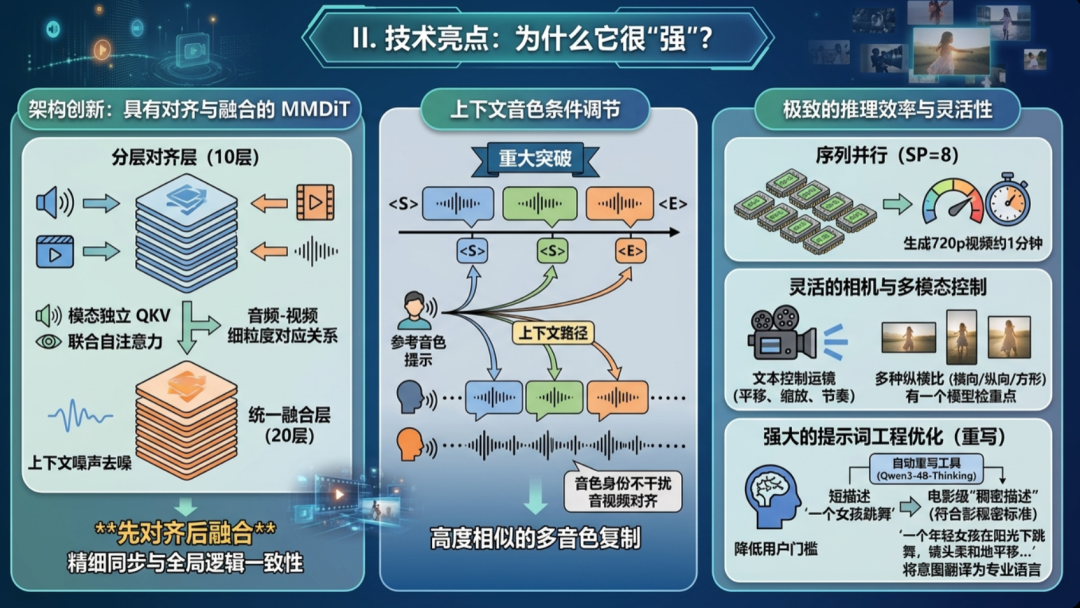
二、 技术亮点:它“强”在哪里?
- 架构革新:对齐后融合的 MMDiT
- 分层对齐层 (10 层)在专用的对齐空间内,先建立细粒度的音视频对应关系(通过模态独立 QKV 和联合自注意力机制)。
- 统一融合层 (20 层)随后进行上下文条件下的去噪。这种“先对齐后融合”的策略,既保证了细粒度的同步,又实现了全局的逻辑一致。
- 上下文音色条件化 (Contextual Timbre Conditioning)
- 这是一大突破。通过“上下文路径”,将参考音色线索精确绑定到特定的语音片段(<S>...<E> 标签)。这样既能实现极高相似度的多音色复刻,又不会让音色身份信息干扰到音视频对齐的基础空间。
- 极致的推理效率与灵活性
- 序列并行 (SP=8)支持在多卡环境下对单样本进行并行处理,极大提升了生成速度(720p 视频约 1 分钟生成)。
- 灵活的镜头与多模态控制通过文本描述即可直接控制镜头构图(如环绕、推近)、摄像机运动节奏,且支持从同一个模型检查点输出多种宽高比(横/竖/方)。
- 强大的提示词工程优化 (Rewrite)
- 官方配套提供了强大的提示词自动重写工具(利用 Qwen3-4B-Thinking),能将简短的描述扩展为符合电影工业标准的“密集描述”。这不仅是工具,更是一种将人类意图转化为模型“懂”的专业语言的桥梁,极大降低了用户使用门槛。
三、和 Wan2.2、LTX 2.3 比起来怎么样?
目前开源音视频生成里,Wan2.2(尤其是它的TI2V-5B版本)和LTX 2.3是两个绕不开的对手。
- Wan2.2的优势在于画面质量和运动自然度。它在图像细节、提示词遵循、物理运动上往往更胜一筹,适合追求电影感的纯视频生成。但它本身不带原生音频,需要额外处理声音,同步问题就得靠后处理解决。生成速度相对较慢,尤其是想做长一点的片子时,迭代成本不低。
- LTX 2.3则主打速度和实用性。它有原生音频生成,能一口气出带声音的视频,生成速度明显更快(很多人反馈在相同硬件上能快好几倍),支持更长的时长和竖版输出。这让它在快速迭代草稿、短视频制作上特别香。但代价是画面质量和提示遵循有时会打折扣,运动偶尔显得有点“飘”,音频虽然同步但精细度有限,尤其在复杂对话场景下。
NAVA 的定位则更偏向“同步优先”的极端。它在 Verse-Bench 上,AV同步指标(Sync-C、Sync-D)明显领先LTX 2.3和其它模型,同时视频质量(PQ、FD)也优于LTX和一些更大参数的对手。参数只有6.3B,却在720p分辨率上做到了更好的平衡。
特别值得一提的是它的Timbre-in-Context Conditioning,能用参考音频精准控制说话人的音色,在Seed-TTS评测里,WER和Speaker Similarity接近甚至超过一些专用音频模型。这点是Wan2.2(无原生音频)和LTX 2.3目前都做不到的精细度,尤其适合虚拟主播、多人对话、带情感的叙事视频。
当然,NAVA也不是万能的。目前生成长度以6-10秒为主,更长视频还需要进一步优化;中文密集提示词下效果最好,英文短提示需要rewrite辅助。单卡跑速度一般,推荐多卡Sequence Parallel才能爽起来。

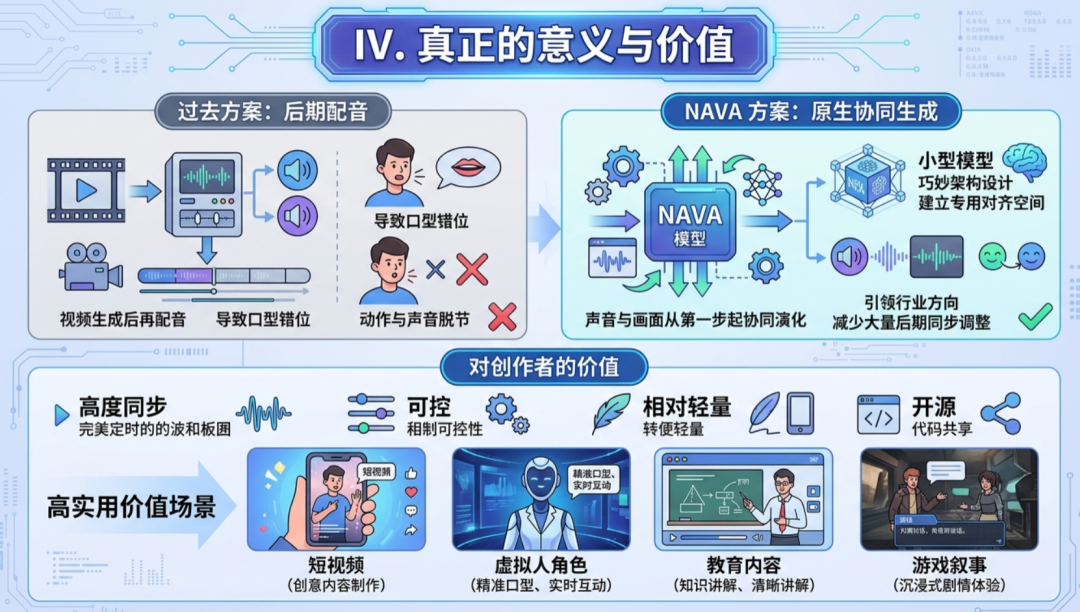
四、它的真正意义和价值
NAVA 最重要的贡献,不是简单地把音频塞进视频生成流程,而是真正推动了“原生协同生成”这个方向。
过去很多方案都是“视频做好了再配音”,结果经常出现唇形不对、动作和声音脱节的问题。NAVA证明了:用更小的模型,通过架构上的巧妙设计(先建专用对齐空间),就能让声音和画面从生成第一步就共同演化。这种思路对整个行业都是有启发的——未来高质量音视频内容,可能不再需要大量后期修同步。
对普通创作者来说,它提供了一个同步强、可控性好、相对轻量的开源方案。尤其在短视频、虚拟数字人、教育内容、游戏叙事这些需要精准音画配合的场景,NAVA的实用价值很高。
总结:
总的来说,NAVA
虽然底层是其它模型但胜在架构创新,不是参数最大、画面最炸的那一个,但它在“音视频真正像一个人一样说话做事”这个关键问题上,往前迈了一大步。这才是联合生成最需要解决的痛点。值得持续关注,剩下的交给社区各位大佬,我也希望有量化模型出来能玩玩体验下。
项目地址:https://ernie-research.github.io/NAVA/
模型地址:https://huggingface.co/robingg1/NAVA
仓库:https://github.com/ernie-research/NAVA
开源代码和权重都在 Hugging Face(robingg1/NAVA)和 GitHub 上放出来了,部署虽然有点门槛,但 Gradio 界面和 prompt rewriter 已经把门槛降了不少。感兴趣的朋友可以去试试,特别是手里有多卡、又对唇同步和音色控制有要求的。
本地算力不够怎么办?
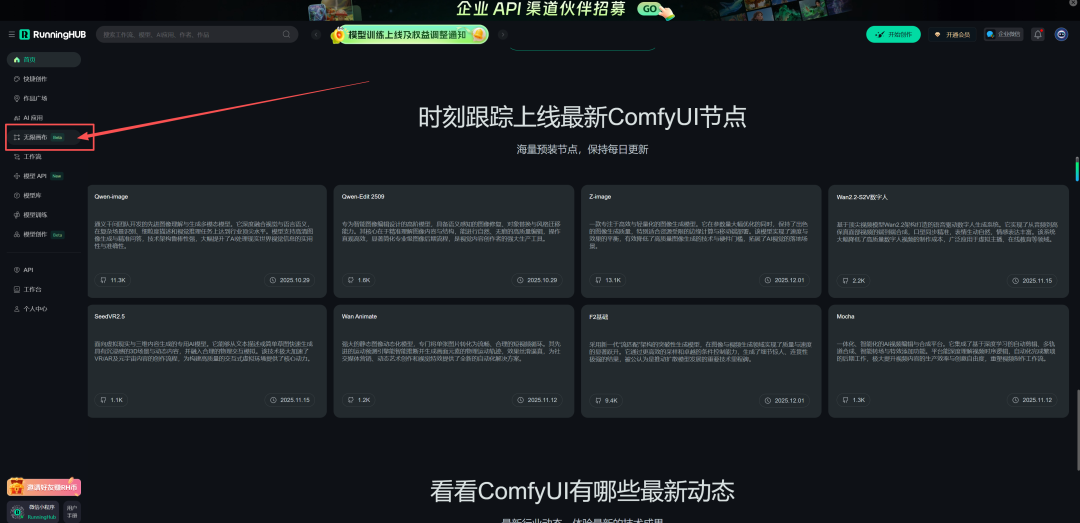
如果本地设备算力不好的小伙伴,推荐使用线上comfyUI来运行体验:runninghub.cn
LTX-23+OmniNFT 图生视频应用体验地址:
注册地址:https://www.runninghub.cn/?utm_source=kol01-RH151
通过这个链接第一次注册送1000点,每日登录送100点
runningHug上的无限画布,也可以使用GPT image进行生成:
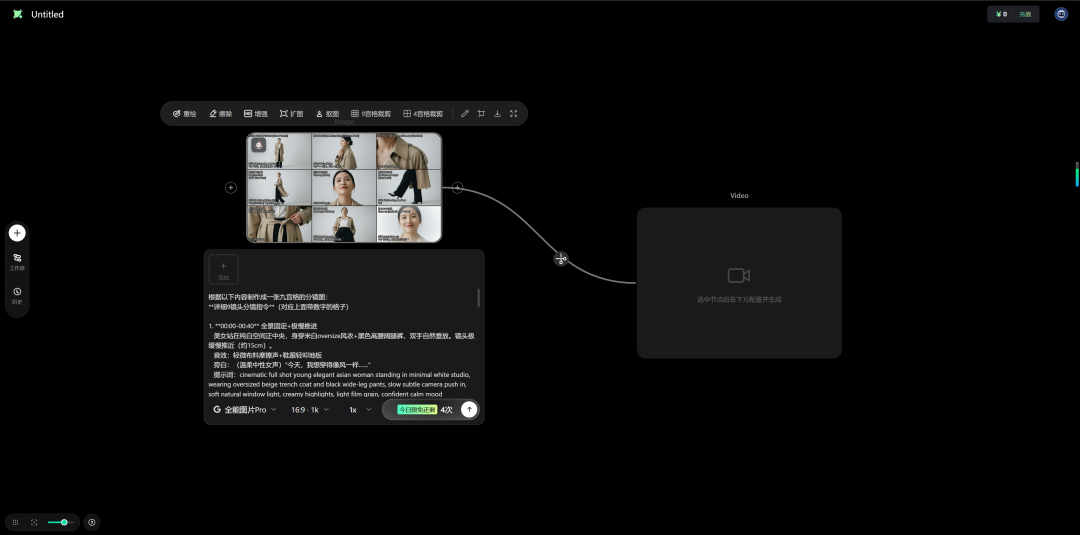
它集成了多个优秀的闭源模型:
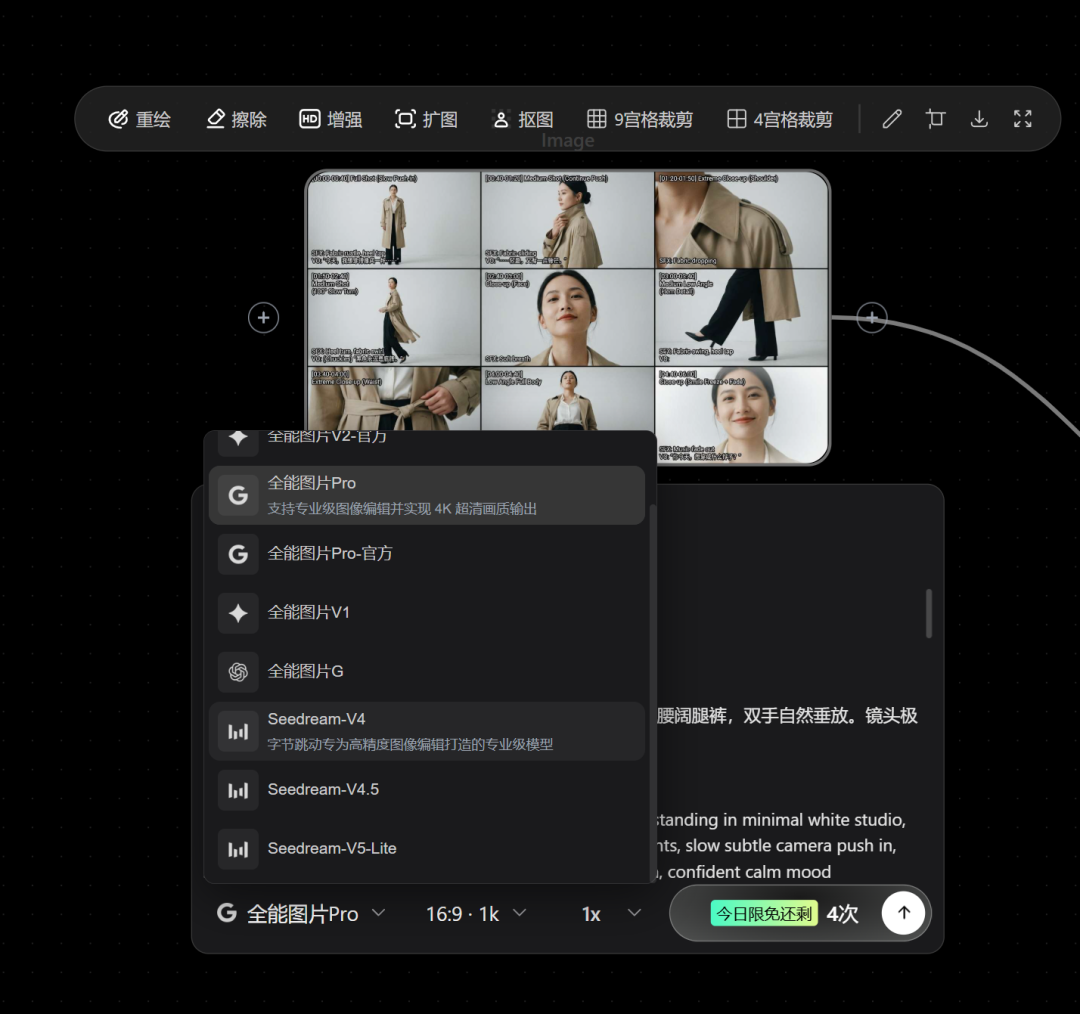
在图像与视频生成中,一个节点就能直接调用使用并生成。十分方便,且价格优惠。它通过集成闭源模型简化了工作流程直接输入即所得,速度很快。是一个不错的选择。通过注册地址:https://www.runninghub.cn/?utm_source=kol01-RH151 注册后打开无限画面
最后几句:
如果对你有帮助,请一键三连支持下我,感谢
CloserAI AI短剧工作台(本地化解决方案):AI短片/短剧Agent工作台closerAI FlowStudio本地AIGC无限画布创作工具:CLOSERAI FlowStudio无限画布closerAI AI绘画大师万象视界:CLOSERAI VISION万象视界CLOSERAI POD电商印花批量生产工作站: https://aigc.douyoubuy.cn/?page_id=420541 印花提取: https://aigc.douyoubuy.cn/yinhua/
以上是就是本期的分享,当然,更多工作流、资讯、插件、工具也可以在我们closerAI会员站上获取(查看原文)。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。
>/ 作者:JimmyMo
更多AI前沿科技资讯,请关注我们:closerAI-一个深入探索前沿人工智能与AIGC领域的资讯平台
主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网

评论(0)