
更多AI前沿科技资讯,请关注我们:
closerAI-一个深入探索前沿人工智能与AIGC领域的资讯平台
【closerAI ComfyUI】开源AI图像编辑新星来了!京东开源项目JoyAI-Image:让空间智能真正“活”起来

大家好,我是Jimmy。
前几天京东开源了一个叫JoyAI-Image的项目:它直接把图像理解、文字生图和指令编辑三件事揉进一个统一框架里,尤其在“空间智能”上,表现得特别亮眼。
先说说这个项目来自哪里。JD开源团队推出的JoyAI-Image,是一个多模态基础模型,核心是8B参数的多模态大语言模型(MLLM)加上16B参数的多模态扩散Transformer(MMDiT)。听起来有点技术,但简单讲,它让AI不再是“看图说话”那么简单,而是真正能“懂空间、控空间、改空间”。
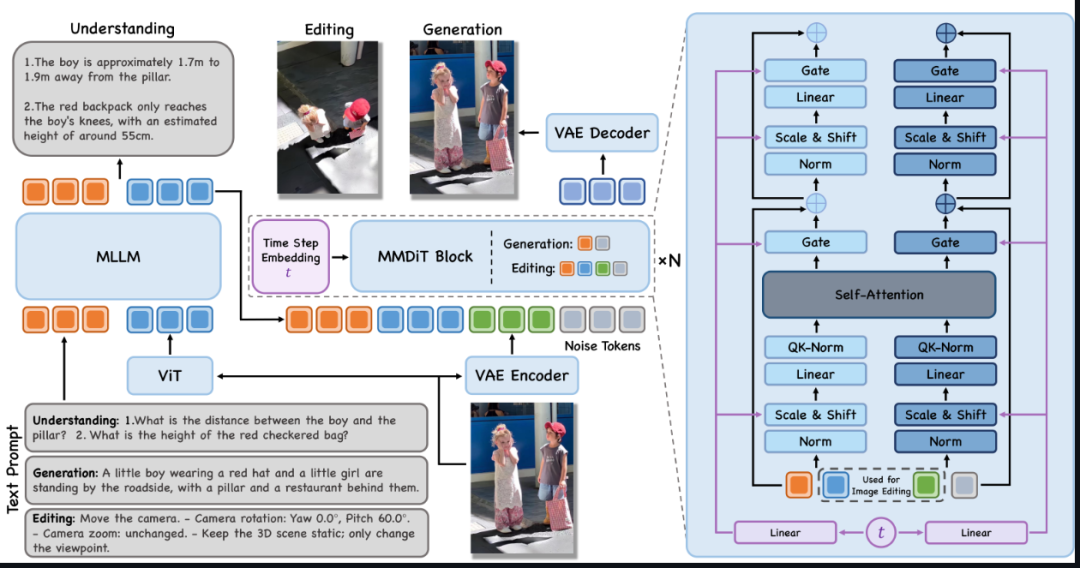
核心架构:MLLM 与 MMDiT 的强强联手
JoyAI-Image 的强大源于其独特的架构设计,它结合了两大核心组件:
- 8 亿像素级 MLLM(多模态大语言模型): 负责高精度的视觉理解、场景解析与指令分解。
- 16 亿像素级 MMDiT(多模态扩散变换器): 负责高质量的图像合成与像素级编辑。
通过共享接口,这两者构成了理解与生成之间的“双向循环”:更强的空间理解力让编辑更精准,而生成的视角变换又反过来为空间推理提供证据。
💎 项目核心亮点
1. 卓越的空间推理与操控
JoyAI-Image 引入了 OpenSpatial(空间理解数据)和 SpatialEdit(编辑数据),使其在处理复杂的空间关系时游刃有余。无论是物体的精确移动、旋转,还是虚拟相机的视角控制,它都能保持场景结构的一致性。
2. 突破性的长文本渲染
AI 生图领域常见的“文字乱码”问题在 JoyAI-Image 中得到了极大优化。它支持:
- 多格漫画排版
- 密集、多行的长文本渲染
- 多种语言与手写风格
- 复杂布局的真实场景文本
3. 高保真度的图像编辑
相比同类模型(如 Qwen-Image-Edit),JoyAI-Image 在执行相机运动(如偏航角 Yaw、俯仰角 Pitch 调整)时更为忠实,能够合成极具诊断意义的新视角,有效消除空间歧义。
📦 模型家族 (Model Zoo)
JoyAI-Image 提供了一系列针对不同任务优化的模型:
| 模型名称 | 任务类型 | 状态 | 描述 |
|---|---|---|---|
| JoyAI-Image-Und | 图像理解 | 已发布 | 实现高保真空间推理的文本-图像理解主干。 |
| JoyAI-Image-Edit | 图像编辑 | 已发布 | 指令引导的精确空间操作编辑模型。 |
| JoyAI-Image-Edit-Plus | 多图编辑 | 即将发布 | 支持跨图像合成、一致性联合操作。 |
| JoyAI-Image | 文本转图像 | 即将发布 | 具有高视角一致性的高质量生图模型。 |
相较于目前市面上主流的图像模型(如 Qwen-Image-Edit 或 Nano Banana Pro),JoyAI-Image 的核心竞争力主要体现在“空间智能的精确闭环”。
在与 Qwen-Image-Edit 的对比中,JoyAI-Image 在执行相机运动指令时表现得更“忠实”:
- 它能更好地保留场景的原始结构。
- 在变换视角时,不会轻易让背景“崩掉”或让物体变形。
💡 核心亮点对比表
| 特性 | 传统/主流模型 (如 Qwen-Image-Edit) | JoyAI-Image |
|---|---|---|
| 空间控制 | 语义模糊(如“把球放左边”) | 坐标/指令化(“Move into red box”) |
| 视角变换 | 随机性强,易变形 | 支持精确 Yaw/Pitch/Zoom 调节 |
| 文本渲染 | 易乱码,仅限短词 | 支持长文本、密集排版、多格漫画 |
| 底层逻辑 | 像素概率分布 | 空间理解与生成的双向循环 |
以下是案例展示:
一、高级文本渲染展示
JoyAI-Image 针对具有挑战性的文本密集型场景进行了优化,包括多格漫画、密集的多行文本、多语言排版、长篇布局、真实场景文本和手写风格。

二、多视图生成与空间编辑展示
JoyAI-Image 展示了一个基于空间的生成和编辑流程,支持多视角生成、几何感知变换、相机控制、物体旋转以及精确的、特定位置的物体编辑。在这些设置下,它能够保持场景内容、结构和视觉一致性,同时更准确地遵循视点相关的指令。

三、空间推理的空间编辑展示
JoyAI-Image 提供高保真度的空间编辑功能,是增强空间推理能力的有力催化剂。与 Qwen-Image-Edit 和 Nano Banana Pro 相比,JoyAI-Image-Edit 通过忠实地执行相机运动,合成最具诊断意义的视角。这些高保真度的新颖视角能够有效消除复杂空间关系的歧义,为后续推理提供更清晰的视觉证据。

目前有safetensors转换版本,且暂时没有comfyUI中的实现。目前消费级显卡几乎很难本地运行。看社区重视情况是否有量化版本和comfyUI支持。
- 主项目:https://github.com/jd-opensource/JoyAI-Image
- 编辑模型(官方):https://huggingface.co/jdopensource/JoyAI-Image-Edit
- safetensors转换版:https://huggingface.co/SanDiegoDude/JoyAI-Image-Edit-Safetensors
最后说一句:技术永远在迭代,今天觉得惊艳的东西,明天可能就被超越。但像JoyAI-Image这样认真做空间智能的尝试,还是值得我们多关注、多支持的。
图像编辑模型有很多,大家可以先体验下其它优秀的开源模型,如flux2 klein\qwen Edit2511等
本地算力不够怎么办?
flux2 klein多图编辑应用体验地址:
注册地址:https://www.runninghub.cn/?utm_source=kol01-RH151
通过这个链接第一次注册送1000点,每日登录送100点
最后几句:
如果对你有帮助,请一键三连支持下我,感谢
更多comfyUI工作流和资讯也可以在我们closerAI会员站上获取(查看原文)。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。
>/ 作者:JimmyMo
更多AI前沿科技资讯,请关注我们:
closerAI-一个深入探索前沿人工智能与AIGC领域的资讯平台
主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网

评论(0)