


更多AI前沿科技资讯,请关注我们:
【closerAI ComfyUI】通义万相wan2.1两倍加速生成,SageAttention加速注意力计算,速度提升30%!
大家好,我是Jimmy。相信最近大家都玩AI视频玩嗨了,特别是comfyUI官方支持wan2.1视频模型之后,工作流简化,同时生成速度得到一定的提升,虽然有所提速,但依旧很慢。我8G显存,用图生视频480P量化模型,跑2秒要7分~8分钟时间。但是!近期,comfyUI劳模KJ大佬,开发了Patch Sage Attention KJ 节点,在comfyUI官方wan2.1工作流中加入这个节点,生成速度直接提升约两倍。
Sage Attention:精确的8位注意力,用于即插即用推理加速
仓库地址:https://github.com/thu-ml/SageAttention/tree/main
以下是论文相关地址,大家有兴趣可查看。
这个仓库提供了SageAttention和SageAttention 2的正式实现。
SageAttention:精确的8位注意力,用于即插即用推理加速 论文:https://arxiv.org/abs/2410.02367 张金涛,魏佳,黄浩锋,张鹏乐,朱军,陈剑飞
SageAttention2:具有彻底的离群值平滑和每线程INT 4量化的高效注意力 论文:https://arxiv.org/abs/2411.10958 Jintao Zhang,Haofeng Huang,Pengle Zhang,Jia Wei,Jun Zhu,Jianfei Chen
SageAttention 是一种高效的量化注意力机制,旨在通过量化技术加速深度学习模型中的注意力计算,同时保持与原始模型相当的精度。
以下是 SageAttention 的主要作用和特点:
1. 加速注意力计算
SageAttention 通过量化(如 INT8 和 FP8)显著提高了注意力机制的计算速度。它在多种 GPU 架构(如 Ampere、Ada 和 Hopper)上实现了优化的内核,能够实现比 FlashAttention2 和 xformers 更快的速度。
速度提升:相比 FlashAttention2 和 xformers,SageAttention 分别实现了 2.1-3.1 倍和 2.7-5.1 倍的速度提升。
硬件兼容性:它支持多种 GPU 架构,包括 NVIDIA 的 Ampere、Ada 和 Hopper 系列,能够在不同硬件上实现高效的计算。
2. 保持精度
SageAttention 在加速的同时,通过以下技术保持了模型的精度:
两层累加策略:在 FP8 MMA 和 WGMMA 中,通过两层累加策略提高精度。
平滑技术:通过量化平滑技术(smoothing)减少量化误差,确保模型的端到端性能不受影响。
INT8 和 FP8 量化:对 QK 和 PV 的计算分别采用 INT8 和 FP8 量化,同时支持不同粒度的量化。
3. 即插即用的加速
SageAttention 提供了即插即用的接口,可以轻松替换现有的注意力实现(如 scaled_dot_product_attention),而无需修改模型的其他部分。
简单替换:通过一行代码替换,可以直接在现有模型中使用 SageAttention,实现加速效果。
兼容性:支持多种输入形状和注意力机制,包括因果注意力(causal attention)和不同序列长度的输入。
4. 支持多种特性
SageAttention 支持以下特性:
稀疏注意力:基于 SageAttention2 的稀疏注意力机制(SpargeAttn)可以进一步加速模型,而无需重新训练。
多线程量化:SageAttention2 引入了每线程量化(per-thread quantization),在保持硬件效率的同时提供更细粒度的量化。
分布式推理:支持 torch.compile 和非 CUDA 图模式推理,适用于大规模分布式推理场景。
5. 实际应用场景
SageAttention 可以广泛应用于需要高效注意力计算的场景,例如:
自然语言处理(NLP):加速 Transformer 模型的推理,如 GPT、BERT 等。
计算机视觉(CV):加速视频生成模型(如 CogVideoX)和图像生成模型。
多模态模型:在需要高效注意力机制的多模态任务中,SageAttention 可以显著提升推理速度。
说了这么多,以下是重点啦:SageAttention 的主要作用是通过量化技术加速注意力机制的计算,同时保持模型精度。它通过即插即用的方式,为深度学习模型提供了高效的加速解决方案,适用于多种 GPU 架构和应用场景。
而KJ大佬,就帮我实现了它在comfyUI中的使用。
Patch Sage Attention KJ节点
更新下KJ大佬节点,同时,安装下sageattn。以下以秋叶整合包为例,方法仅供参考啦。
安装sageattn方法:
1、https://github.com/woct0rdho/triton-windows/releases
在以上链接找到对应python的triton轮子文件,下载,放置python目录下。
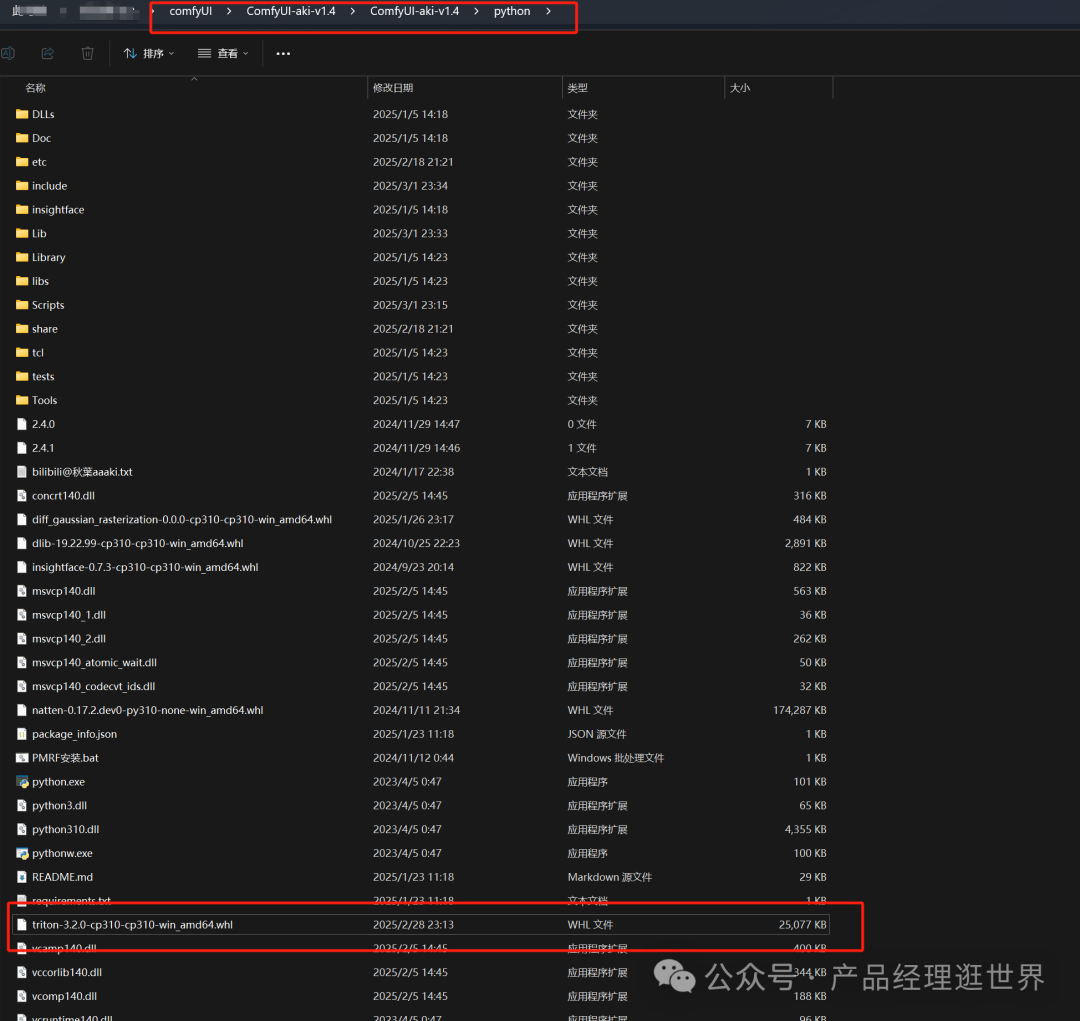
2、在comfyui python文件夹里 cmd,打开终端,输入:python -m pip install "轮子地址(右键轮子文件,复制文件地址然后粘贴到这里)",回车。
3、然后还要安装这个库:直接再输入这个命令:python.exe -m pip install SageAttention
4、检查下是否有下载:cuda tools 版本号为: cuda_12.4.1_551.78_windows ,没有的下载安装 。不要下载cuda 12.8 ,我试过最新的版本的不行。
其它有问题的报错的,建议大家看下后台,提示找不到的,就是需要下载的。以下大家参考下吧,没有的就安装下吧。closerAI 会员自行在模型库下载,已整理好。
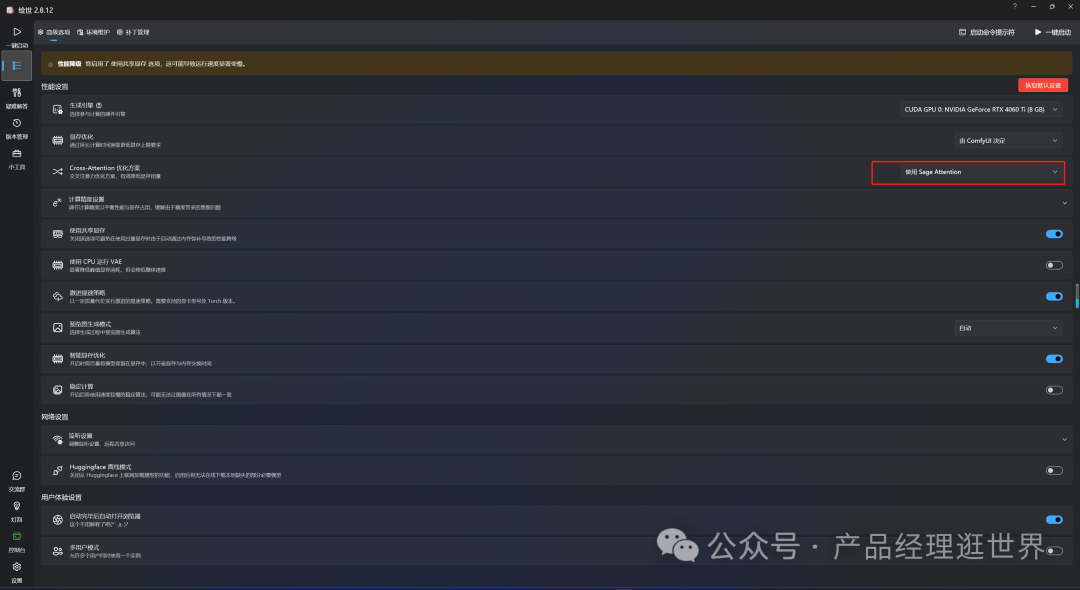
小提示,如果大家不想用这个加速推理的话,可以在秋叶整合包下面框住的位置,重新选回xFormers(推荐)即可。不过,这个适用于图片与视频生成的加速。所以,弄好后,基本生成都会提速。
以下是工作流,加入了Patch Sage Attention后,
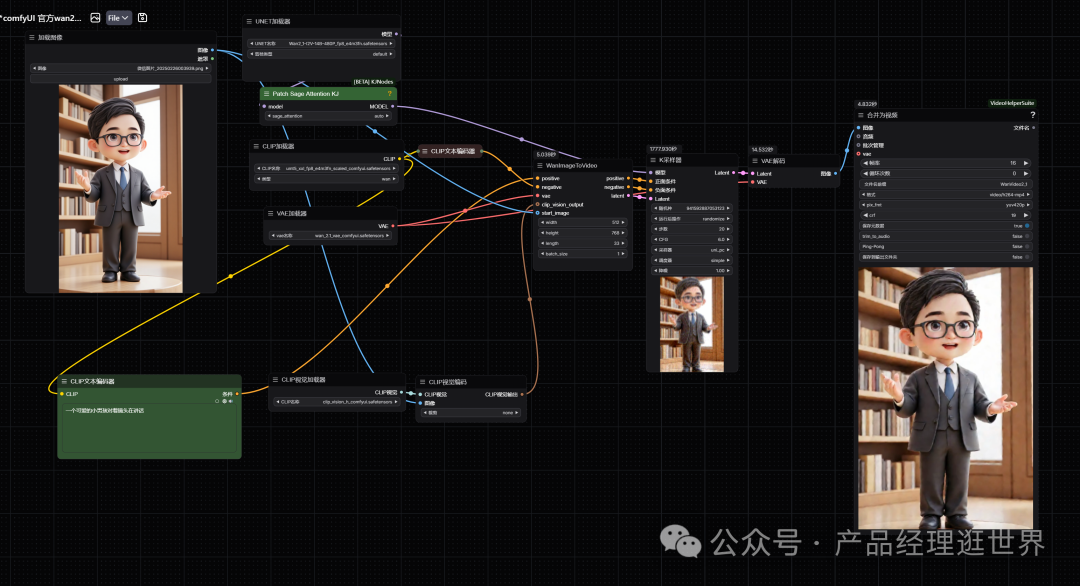
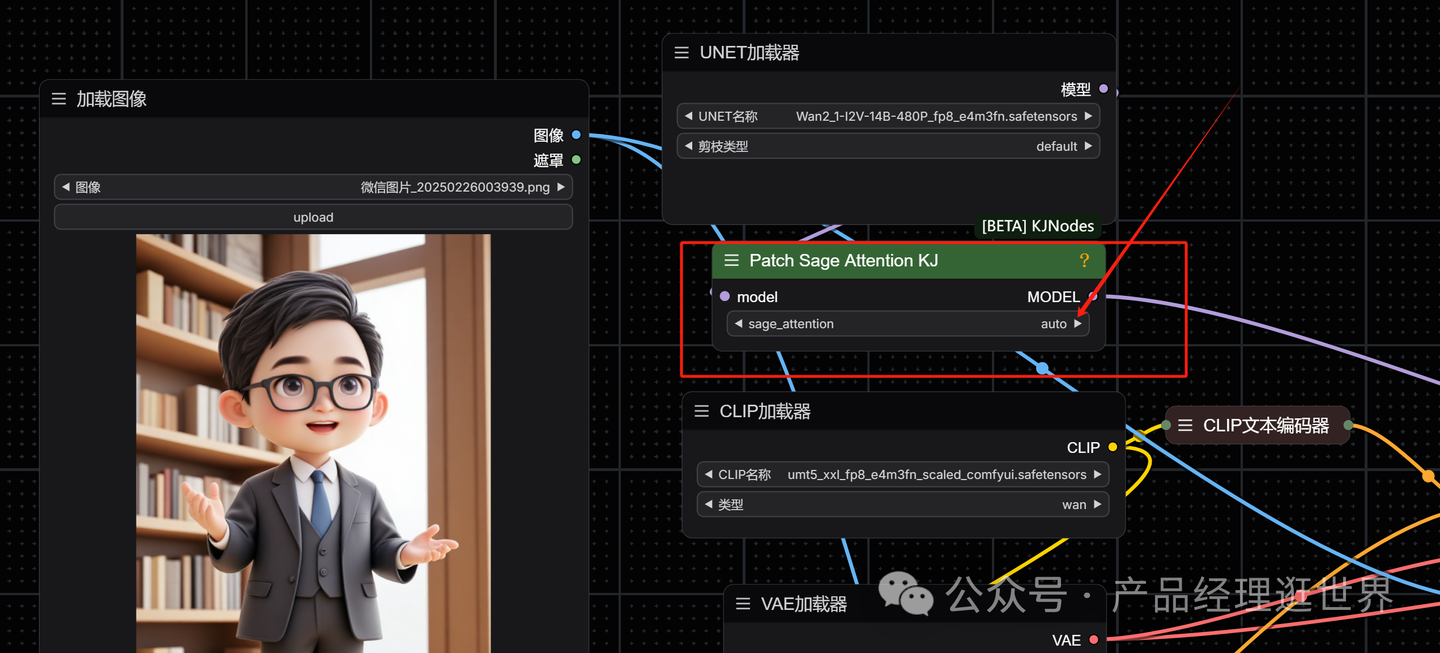
这里选择自动即可。
在加入这个节点后,我8G的显卡也尝试生成512*768尺寸的视频生成了。
虽然设备已是硬伤,但在各方面都优化后,也能玩玩。希望大佬们能再迭代下,让8G、16G的设备能在速度方面达到最极致,这样无论对于个人玩家还是整个AIGC市场都利用。毕竟长期使用收费产品是一笔不小支出。
结论,建议大家有能力有时间的可以安装下这个节点,提升视频生成速度。
以上是Sage Attention的介绍以及其在comfyUI中的安装与使用方法介绍,大家可以根据工作流思路进行尝试搭建。
当然,也可以在我们closerAI会员站上获取对应的工作流。
更多AI前沿科技资讯,请关注我们:

主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网

评论(0)